
活动地址:CSDN21天学习挑战赛
工欲善其事,必先利其器
子曰:“工欲善其事,必先利其器。居是邦也,事其大夫之贤者,友其士之仁者。”
各位爱好机器学习的小伙伴们,大家好!在我们学习和工作中,使用好的工具会事半功倍。sklearn就是一把机器学习领域的瑞士军刀。有了它,很多事情就变得简单了!
scikit-learn是基于Python语言的机器学习库,具有如下特点:
1.简单高效的数据分析工具
2.可在多种环境中重复使用
3.建立在Numpy,Scipy以及matplotlib等数据科学库之上
4.开源且可商用的-基于BSD许可
sklearn的内容很多,本文想通过一个小案例来说明一些关键的概念。
数据集
巧妇难为无米之炊,数据集是机器学习的原材料,没有数据,一切都是空谈。sklearn.datasets模块提供了多种数据集:
1.自带的小数据集(Toy datasets):sklearn.datasets.load_<name>
2.可在线下载的数据集(Real world datasets):sklearn.datasets.fetch_<name>
3.计算机生成的数据集(Generated datasets):sklearn.datasets.make_<name>
4.其他可加载的数据集(Loading other datasets)
PCA降维
PCA(Principal Component Analysis) ,即主成分分析,是一种使用最广泛的数据降维算法。主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。主要步骤就是先计算样本矩阵的协方差矩阵,然后对协方差矩阵进行矩阵分解,按一定的规则(比如特征值大则对应的特征向量越重要)取出前k个特征值及特征向量,得到的特征向量既是降维的结果。
流形学习
流形学习也主要用于降维,有些数据利用PCA降维效果不理想,于是就有了流形学习的诸多方法,如Isomap、LLE等。其主要思想是假设所处理的数据点分布在嵌入于外维欧式空间的一个潜在的流形体上,降维时要保证降维前后每个样本数据之间的相似度尽量保持不变。主要步骤基本上是根据原数据矩阵,按一定的相似度规则,计算出代表相似度的矩阵,然后在对相似度矩阵进行矩阵分解,选出的特征向量就是降维的结果。详细的内容会在以后的文章中详细说明。
Pipeline(管道)
Pipeline 可以把多个评估器(转换器、分类器等)链接成一个大模型。这个是很有用的,因为处理数据的步骤一般都是固定的。Pipeline 在这里有多种用途:
1.便捷性和封装性:你只要对数据调用 fit和 predict 一次来适配所有的一系列评估器。
2.联合的参数选择:你可以一次grid search管道中所有评估器的参数。
3.安全性:训练转换器和预测器使用的是相同样本,管道有助于防止来自测试数据的统计数据泄露到交叉验证的训练模型中。
除了最后一个评估器,管道的所有评估器必须是转换器 (必须有 transform 方法)。最后一个评估器的类型不限(转换器、分类器等等)。
案例:手写数字数据上的 K-Means 聚类演示
本文案例采用手写数字数据,将数据从原始 64 维空间投影到一个二维空间,并在这个新空间中绘制数据和集群。Isomap和LLE与PCA相比,计算较慢,读者在运行时稍稍耐心一下啊!!
样本数据的图片展示如下:

代码如下:
import numpy as np
from sklearn.datasets import load_digits
import matplotlib.colors
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
from sklearn.manifold import (
Isomap,
LocallyLinearEmbedding
)
# 加载数据:手写数字数据
digits = load_digits()
data = digits.data
labels = digits.target
# 样本个数,样本属性个数,类别标签个数
(n_samples, n_features), n_digits = data.shape, np.unique(labels).size
print(f"# 类别: {n_digits}; # 样本数: {n_samples}; # 样本属性个数 {n_features}")
# 绘图展示前30个数字
fig0 = plt.figure(figsize=(7, 7))
fig0.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(30):
ax = fig0.add_subplot(6, 5, i+1, xticks=[], yticks=[])
ax.imshow(digits.images[i], cmap=plt.cm.binary, interpolation='nearest')
ax.text(0, 7, str(digits.target[i]))
plt.show()
# 通过管道构建模型,首先进行降维,然后利用K-means进行聚类,这里对比了3种不同降维方法的效果
models = [Pipeline([('reduction', PCA(n_components=2)), ('clr', KMeans(init="k-means++", n_clusters=n_digits, n_init=4))]),
Pipeline([('reduction', Isomap(n_neighbors=30, n_components=2)), ('clr', KMeans(init="k-means++", n_clusters=n_digits, n_init=4))]),
Pipeline([('reduction', LocallyLinearEmbedding(n_neighbors=30, n_components=2, method="modified")), ('clr', KMeans(init="k-means++", n_clusters=n_digits, n_init=4))])]
# 模型标题
model_titles = ["PCA降维加K-means聚类,聚类中心用叉号表示", "Isomap降维加K-means聚类,聚类中心用叉号表示", "LLE降维加K-means聚类,聚类中心用叉号表示"]
for t in range(len(models)):
# 训练模型
model = models[t]
model.fit(data)
# 降维后的数据(二维)
reduced_data = model.named_steps["reduction"].transform(data)
# 绘图网格间隔
h = 0.02
# 生成绘图网格数据
x_min, x_max = reduced_data[:, 0].min() - 1, reduced_data[:, 0].max() + 1
y_min, y_max = reduced_data[:, 1].min() - 1, reduced_data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 对网格数据进行聚类预测
Z = model.named_steps["clr"].predict(np.c_[xx.ravel(), yy.ravel()])
# 绘制结果
Z = Z.reshape(xx.shape)
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(1)
plt.clf()
plt.imshow(
Z,
interpolation="nearest",
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap=plt.cm.Paired,
aspect="auto",
origin="lower",
)
# 绘制聚类中心
plt.plot(reduced_data[:, 0], reduced_data[:, 1], "k.", markersize=2)
centroids = model.named_steps["clr"].cluster_centers_
plt.scatter(
centroids[:, 0],
centroids[:, 1],
marker="x",
s=169,
linewidths=3,
color="w",
zorder=10,
)
plt.title(model_titles[t])
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
结果如下:

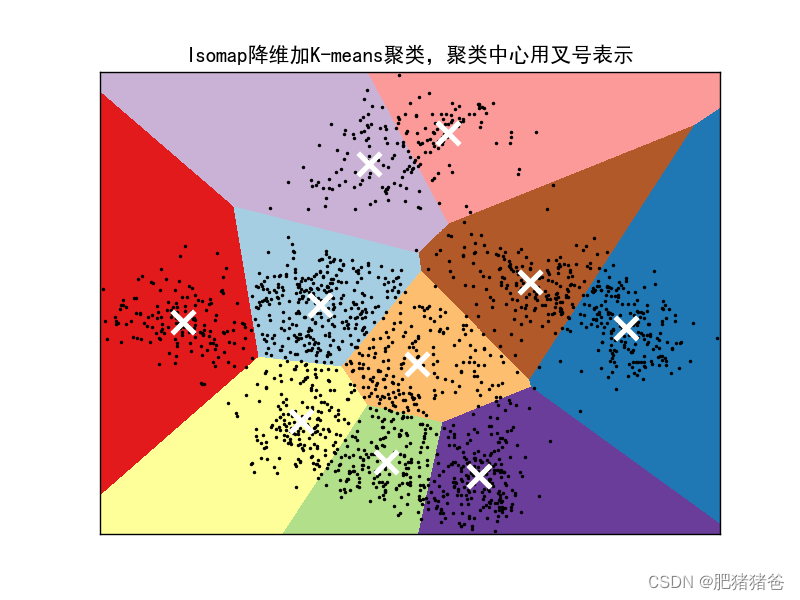

本文案例降维后仅保留2个维度,要是对数据进行预测,准确率可能比较低,本文只是通过该案例说明一些sklearn的概念!
作者这水平有限,有不足之处欢迎留言指正
本文转载自: https://blog.csdn.net/weixin_37522117/article/details/126436506
版权归原作者 肥猪猪爸 所有, 如有侵权,请联系我们删除。
版权归原作者 肥猪猪爸 所有, 如有侵权,请联系我们删除。