
在机器学习中,超参数是用于控制机器学习模型的学习过程的参数。为了与从数据中学到的机器学习模型参数区分开,所以称其为超参数。超参数的配置决定了机器学习模型的性能,每组独特的超参数集可以对应一个学习后的机器学习模型。对于大多数最先进的机器学习模型,所有可能的超参数组合的集合可能会很大。大多数机器学习模型软件包的默认参数值都经过了一些特别的调整优化,可实现不错的基线性能。这意味着可以直接使用,但这些如果针对特定的情况还是需要找到特定的超参数值,这样才能达到最佳的性能。

许多算法和库都提供了自动化的超参数选择。超参数选择是一种优化的过程,在该过程中目标函数由模型表现表示。优化任务是找到一组让机器学习模型的性能表现得最好的参数。
超参数优化的空间非常丰富,最初也是最简单的优化方式是暴力搜索:通过详尽搜索所有可能的超参数组合来找到最佳的超参数。如果可以详尽地搜索超参数空间,那么肯定可以提供一组最佳超参数组合。但是在计算资源和时间方面,暴力搜索搜索超参数空间通常是不可行的,这是因为超参数搜索属于非凸优化的范畴,寻找全局最优几乎是不可行的,因为它可能会陷入几个次优的“陷阱”之一,也称为局部最小值,这使得算法很难搜索超参数的整个空间。
暴力搜索优化的一个替代方案是黑盒(Black-Box)非凸优化技术。黑盒非凸优化算法可根据某些预定义的度量找到足够最佳的局部最小值(或最大值)的次优解。
Python具有许多这样的工具。比如sklearn中的GridSearchCV就是暴力优化。而IBM开发的RBFopt包则提供了黑盒优化的方法。它的工作原理是使用径向基函数来构建和细化正在优化的函数的代理模型。并且它不需要对被优化函数的形状或行为做任何假设,而且可以被用于优化复杂的模型,如深度神经网络。
本文中将使用Kaggle上公开可用的电信客户流失数据集。数据集可以在Apache 2.0许可证下免费使用,修改和共享。
数据准备
首先,让我们使用pandas读取数据:
df = pd.read_csv("telco_churn.csv")
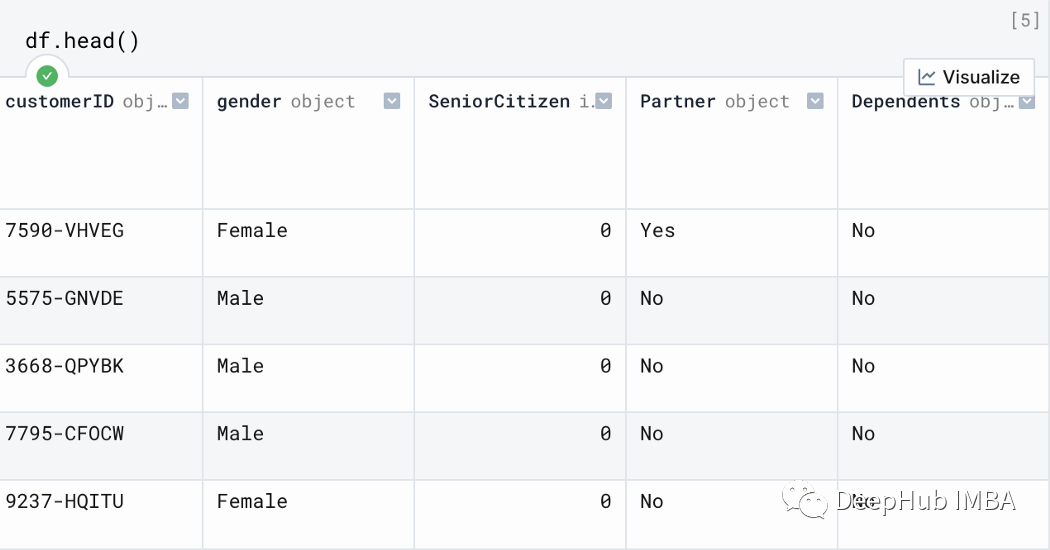
我们看到数据包含诸如客户ID、性别、身份等字段。
字段“churn”,它对应于客户是否重复购买。值为“No”表示该客户重复购买,值为“Yes”表示该客户停止购买。
这是一个简单的分类模型,以gender、senorcitizen、InternetService、DeviceProtection、MonthlyCharges和TotalCharges字段作为输入,并预测客户是否会流失。所以需要将分类列转换为机器可读的值,因为只有数值类型的值才可以作为输入传入机器学习模型。
df['gender'] = df['gender'].astype('category')
df['gender_cat'] = df['gender'].cat.codes
df['SeniorCitizen'] = df['SeniorCitizen'].astype('category')
df['SeniorCitizen_cat'] = df['SeniorCitizen'].cat.codes
df['InternetService'] = df['InternetService'].astype('category')
df['InternetService_cat'] = df['InternetService'].cat.codes
df['DeviceProtection'] = df['DeviceProtection'].astype('category')
df['DeviceProtection_cat'] = df['DeviceProtection'].cat.codes
df[['gender_cat', 'SeniorCitizen_cat', 'InternetService_cat', 'DeviceProtection_cat']].head()
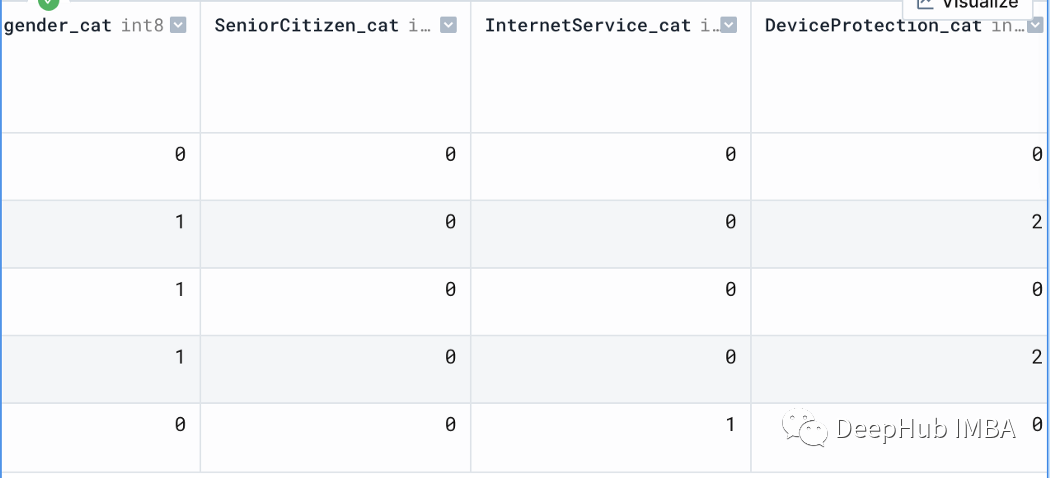
我们还必须对churn列,也就是我们的目标列做一类似的操作:
df['Churn'] = df['Churn'].astype('category')
df['Churn_cat'] = df['Churn'].cat.codes
因为有一些缺失值,所以需要处理TotalCharges列,将无效值替换为NaN,并用TotalCharges的平均值填充
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], 'coerce')
df['TotalCharges'].fillna(df['TotalCharges'].mean(), inplace=True)
定义一个变量X,它将是一个series ,包含我们模型的输入。输出将是一个名为Y的变量,它将包含流失率值:
X = df[['TotalCharges', 'MonthlyCharges', 'gender_cat', 'SeniorCitizen_cat', 'InternetService_cat', 'DeviceProtection_cat']]
y = df['Churn_cat']
下一步就是拆分用于训练和测试的数据。还是使用scikit-learn中model_selection模块中的train_test_split方法:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
训练模型
我们使用随机森林分类模型,并且只使用默认参数进行训练,作为基类模型
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
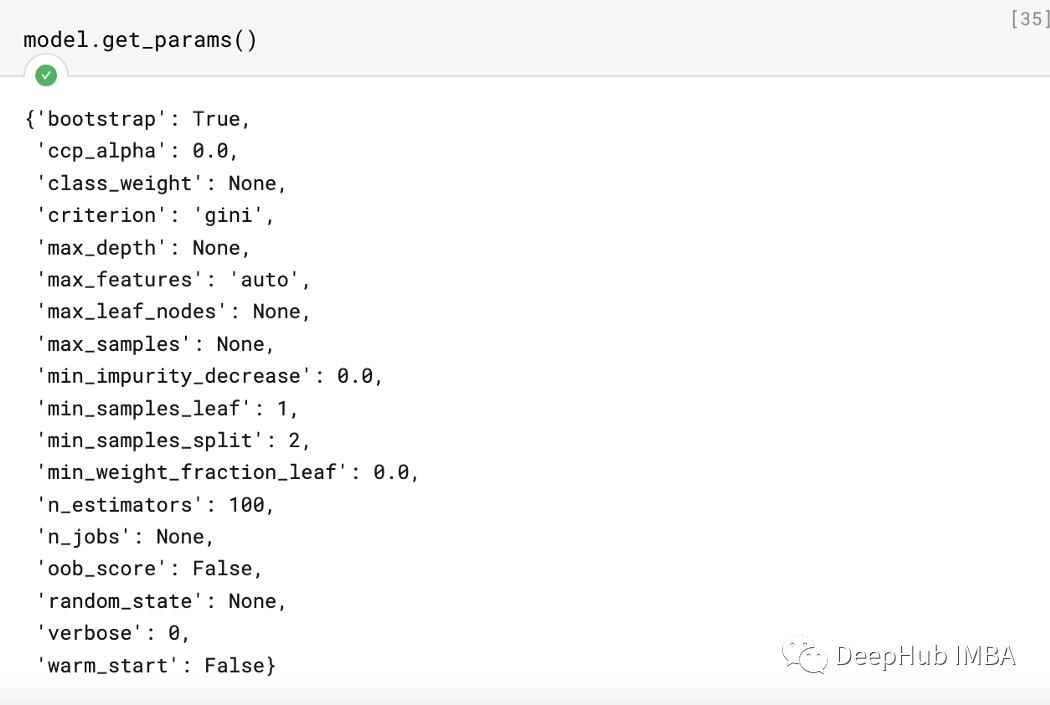
让我们打印模型的默认参数值。在模型对象上调用get_params()方法:
model.get_params()
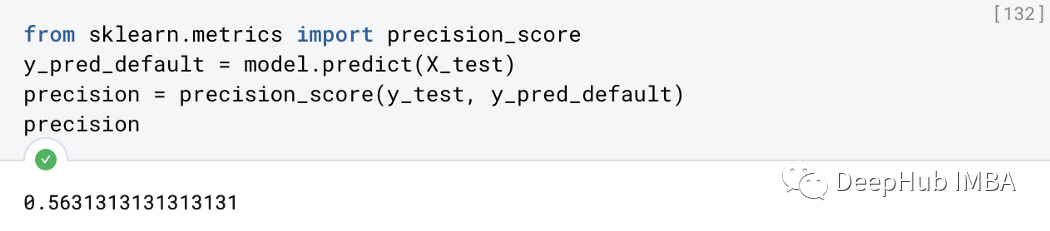
使用精度来评估我们的分类模型。
from sklearn.metrics import precision_score
y_pred_default = model.predict(X_test)
precision = precision_score(y_test, y_pred_default)
precision
现在让我们看看如何应用暴力的网格搜索来找到最佳随机森林分类模型。
GridSearchCV
GridSearchCv等暴力搜索方法的工作原理是在整个搜索空间中搜索最佳超参数集。所以就需要定义用于指定参数的字典,GridSearch会遍历字典中所有的组合,然后找到最好的组合。
from sklearn.model_selection import GridSearchCV
params = {'n_estimators': [10, 100],
'max_features': ['sqrt'],
'max_depth' : [5, 20],
'criterion' :['gini']}
定义好字典后,初始化对象,并开始训练:
grid_search_rf = GridSearchCV(estimator=model, param_grid=params, cv= 20, scoring='precision')
grid_search_rf.fit(x_train, y_train)
训练完成后可以显示最佳参数:
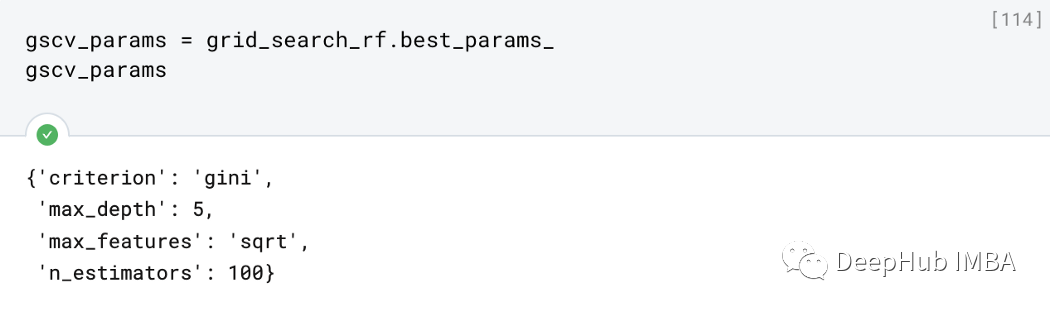
gscv_params = grid_search_rf.best_params_
gscv_params
获得最佳参数后,使用最佳参数重新训练随机森林模型:
gscv_params = grid_search_rf.best_params_
model_rf_gscv = RandomForestClassifier(**gscv_params)
model_rf_gscv.fit(X_train, y_train)
看看结果
y_pred_gscv = model_rf_gscv.predict(X_test)
precision_gscv = precision_score(y_test, y_pred_gscv)
precision_gscv
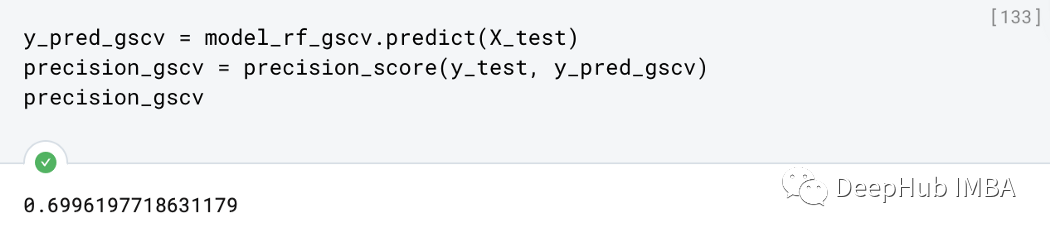
可以看到,精度比我们的默认参数的基线模型有了很大的提升,但是如果对于大型的模型不可能有资源和时间遍历所有的超参数空间,所以就需要我们使用以前介绍的贝叶斯优化或者本文的黑盒优化方法了。
RBFopt黑盒优化
现在让我们使用RBFopt进行超参数黑盒优化。
安装RBFopt:
%pip install -U rbfopt
为了进行优化,所以需要为的模型参数定义一个上界和下界列表。下界列表将包含10个估计器的数量和5个最大深度。上界列表将包含100个估算数和20个最大深度:
lbounds = [10, 5]
ubounds = [100, 20]
然后就是定义目标函数:接受n_estimators和max_depth的输入,并为每组参数构建多个模型。对于每个模型,我们将计算并返回精度。RBFopt会自动的为n_estimators和max_depth找到一组能最大化精度的值。因为RBFOPT是找到最小值,但是我们的目标是最大化精度,所以我们要返回精度的相反数:
import rbfopt
from sklearn.model_selection import cross_val_score
def precision_objective(X):
n_estimators, max_depth = X
n_estimators = int(n_estimators)
max_depth = int(max_depth)
params = {'n_estimators':n_estimators, 'max_depth': max_depth}
model_rbfopt = RandomForestClassifier(criterion='gini', max_features='sqrt', **params)
model_rbfopt.fit(X_train, y_train)
precision = cross_val_score(model_rbfopt, X_train, y_train, cv=20, scoring='precision')
return -np.mean(precision)
然后就是指定运行的次数、函数调用和超参数的维度数:
num_runs = 1
max_fun_calls = 8
ndim = 2
运行RBFopt:
obj_fun = precision_objective
bb = rbfopt.RbfoptUserBlackBox(dimension=ndim, var_lower=np.array(lbounds, dtype=np.float), var_upper=np.array(ubounds, dtype=np.float), var_type=['R'] * ndim, obj_funct=obj_fun)
settings = rbfopt.RbfoptSettings(max_evaluations=max_fun_calls)
alg = rbfopt.RbfoptAlgorithm(settings, bb)
查看找到的超参数
fval, sol, iter_count, eval_count, fast_eval_count = alg.optimize()
obj_vals = fval
sol_int = [int(x) for x in sol]
params_rbfopt = {'n_estimators': sol_int[0], 'max_depth': sol_int[1]}
params_rbfopt
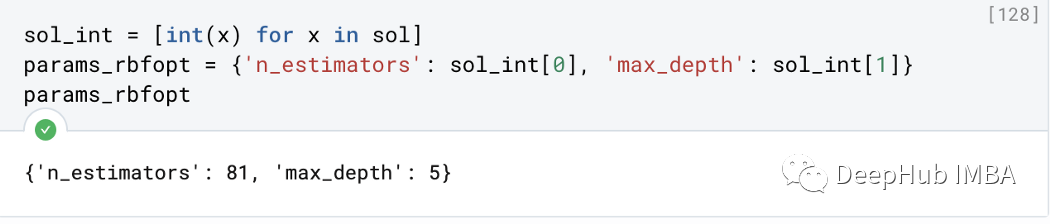
RBFopt为n_estimators和max_depth分别找到了最优值81和5。
将这些最优参数传递到新模型中,并拟合训练数据和查看结果:
model_rbfopt = RandomForestClassifier(criterion=’gini’, max_features=’sqrt’, **params_rbfopt)
model_rbfopt.fit(X_train, y_train)
y_pred_rbfopt = model_rbfopt.predict(X_test)
precision_rbfopt = precision_score(y_test, y_pred_rbfopt)
precision_rbfopt
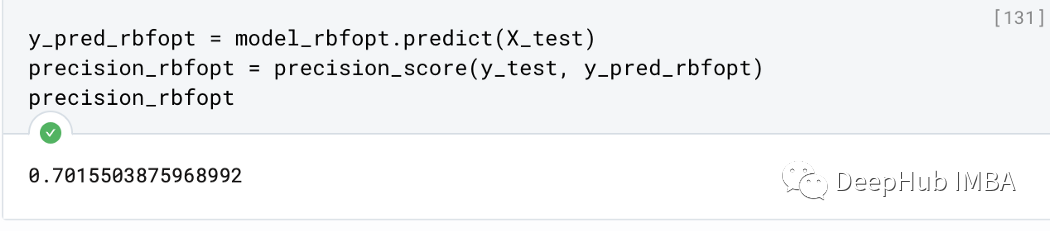
不仅精度上有了轻微的提升,优化算法也执行的更快速了,这对于大型超参数搜索空间的情况特别有用。
总结
虽然大多数机器学习算法的默认超参数提供了良好的基线性能,但为了得到更好的性能,超参数调整通常是必要的。暴力优化技术是有用的,但它在时间和计算方面需求很大。更有效的黑盒优化方法(如RBFopt)是暴力优化一个很好的替代。RBFopt是一种非常有用的黑盒技术,如果你想进行超参数的优化,可以从它开始。
本文代码:https://github.com/spierre91/deepnote/blob/main/hyperparameter_tuning_tutorial.ipynb
作者:Sadrach Pierre, Ph.D.