
数据预处理是机器学习生命周期的非常重要的一个部分。特征工程又是数据预处理的一个重要组成, 最常见的特征工程有以下一些方法:
- 编码
- 缩放
- 转换
- 离散化
- 分离
等等
在本文中主要介绍特征缩放和特征编码的主要方法。
特征缩放
特征缩放是一种在固定范围内对数据中存在的独立特征进行标准化的技术。有些机器学习模型是基于距离矩阵的,例如:k - nearest - neighbors, SVM和Neural Network。对于这些模型来说,特性缩放是非常重要的,特别是当特性的范围非常不同的时候。范围较大的特征对距离计算的影响较大。
标准化 Standarization
数据的标准化是将数据按比例缩放,使之落入一个小的特定区间,把数据转换为统⼀的标准。z-score标准化,即零-均值标准化(常用方法)
- 标准化(或z分数归一化)缩放后,特征就变为具有标准正态分布,具有μ= 0和σ= 1,其中μ均值,σ是平均值的标准差。
- 通过标准化约68%的值介于-1和1之间。
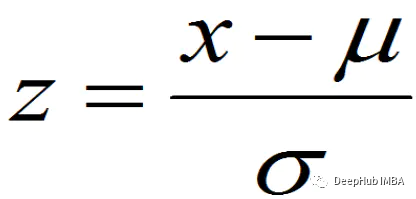
from sklearn.preprocessing import StandardScaler
scale = StandardScaler().fit(data)
scaled_data = scale.transform(data)
规范化(归一化)Normalization
规范化是把数据变为(0,1)之间的小数。主要是为了方便数据处理,将数据映射到0~1范围之内,可以使处理过程更加便捷、快速。
规范化经常被用作机器学习数据准备的一部分。规范化的目标是更改数据集中数值列的值,以使用通用的刻度,而不会扭曲值范围的差异或丢失信息
最常见的方法是最小-最大缩放,公式如下:
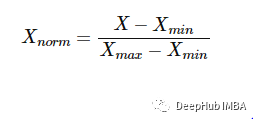
from sklearn.preprocessing import MinMaxScaler
norm = MinMaxScaler().fit(data)
transformed_data = norm.transform(data)
将特征的每个值除以最大值是规范化的另一种方法。它通常与稀疏数据一起使用(例如图像)。
data_norm = data['variable']/np.max(data['variable'])
另一种规范化方法是RobustScalar,用于处理异常值问题。RobustScalar使用四分位范围(IQR),因此它对异常值是稳健的。
from sklearn.preprocessing import RobustScaler
rob = RobustScaler().fit(data)
data_norm = rob.transform(data)
标准化与规范化的区别
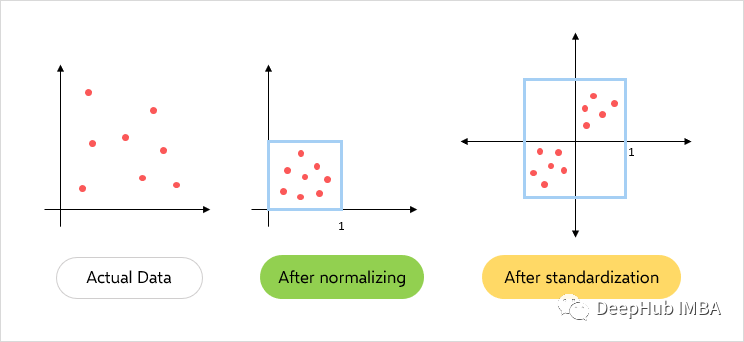
- 在规范化中只更改数据的范围,而在标准化中会更改数据分布的形状。
- 规范化将这些值重新缩放到[0,1]的范围内。在所有参数都需要具有相同的正刻度的情况下是非常有效的。但是数据集中的异常值会丢失。
- 而在标准化中,数据被缩放到平均值(μ)为0,标准差(σ)为1(单位方差)。
- 规范化在0到1之间缩放数据,所有数据都为正。标准化后的数据以零为中心的正负值。
如何选择使用哪种缩放方法呢?
- 当数据具有识别量表并且使用的算法不会对数据的分布,比如K-Nearealt邻居和人工神经网络时,规范化是有用的。
- 当数据是识别量表时,并且使用的算法确实对具有高斯(正态)分布的数据进行假设,例如如线性回归,逻辑回归和线性判别分析标准化很有用。
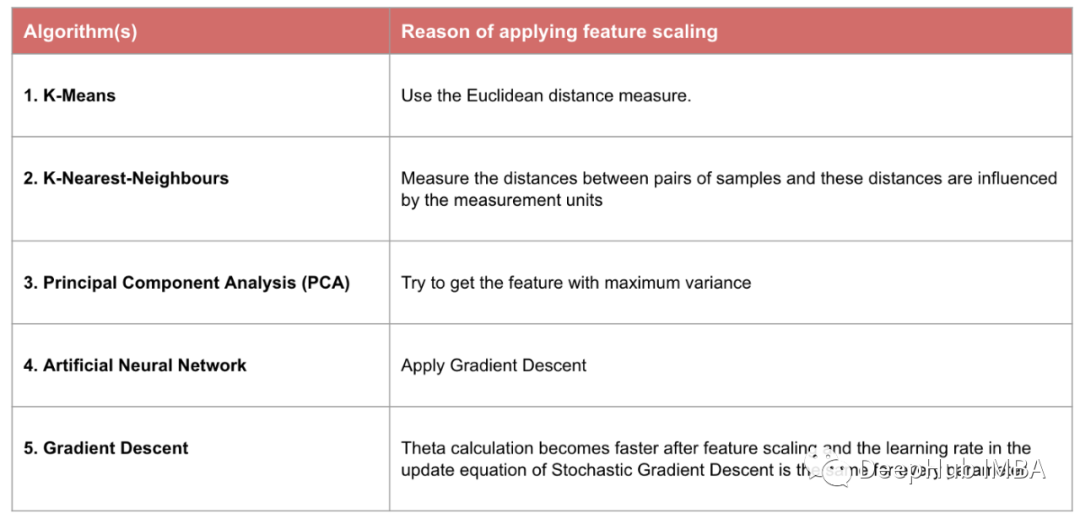
虽然是这么说,但是使用那种缩放来处理数据还需要实际的验证,在实践中可以用原始数据拟合模型,然后进行标准化和规范化并进行比较,那个表现好就是用那个,下图是需要使用特征缩放的算法列表:
特征编码
上面我们已经介绍了针对数值变量的特征缩放,本节将介绍针对分类变量的特征编码,在进入细节之前,让我们了解一下特征编码的不同类型。
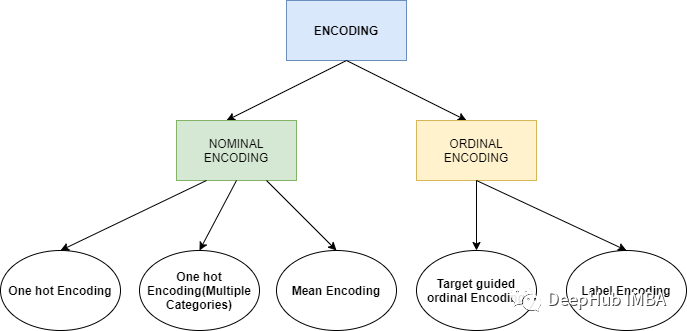
NOMINAL CATEGORICAL是我们不需要关心排列或顺序的分类变量。例如性别,产品类别,国家地区,这些分类变量没有顺序的概念。
ORDINAL CATEGORICAL是序数类别,这里的类别还包含了顺序的信息,比如我们考试的分数 ,优、良、中、差,优是最好的,差是最不好的。或者是我们的教育程度,小学,中学,大学,硕士,也是按照顺序排列的。
了解了上面的类型后,我们开始进行特征编码的介绍:
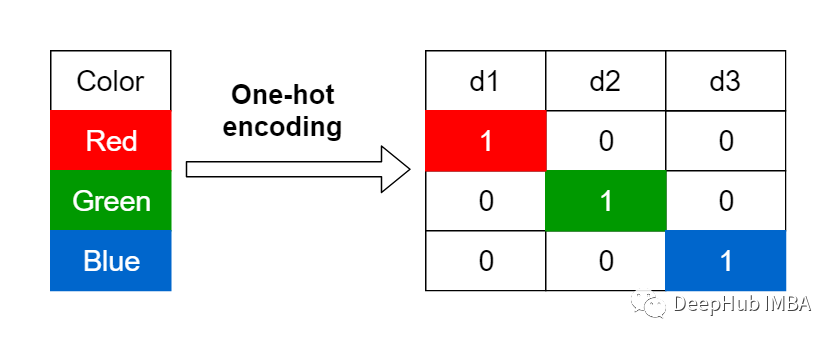
独热编码(ONE HOT)
我们有一个包含3个分类变量的列,那么将在一个热编码中为一个分类变量创建每个热量编码3列。
独热编码又称一位有效编码。其方法是使用 N位 状态寄存器来对 N个状态 进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
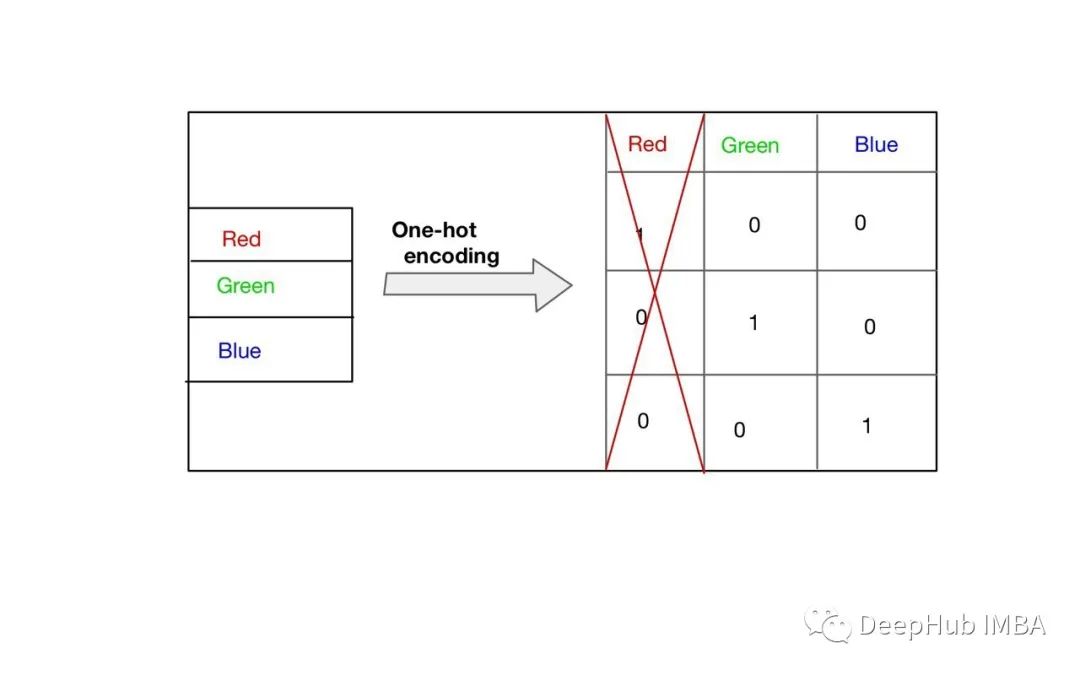
哑变量陷阱
哑变量陷阱是指一般在引入虚拟变量时要求如果有m个定性变量,在模型中引入m-1个虚拟变量。否则如果引入m个虚拟变量,就会导致模型解释变量间出现完全共线性的情况。
所以上面的例子中,我们可以跳过任何列我们这里选择跳过第一列“red”
独热编码虽然简单,但是页有非常明显的缺点:
假设一列有100个分类变量。现在如果试着把分类变量转换成哑变量,我们会得到99列。这将增加整个数据集的维度,从而导致维度诅咒。
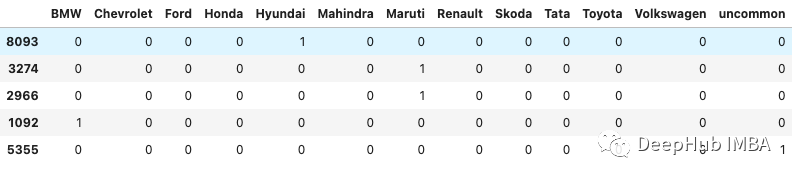
所以基本上,如果一列中有很多分类变量我们就不应该用这种方法。这里有一个简单的解决办法,只考虑那些重复次数最多的类别,例如只考虑前10个数量最多的类别,并只对这些类别应用编码。
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(drop='first',sparse=False,dtype=np.int32)
counts = df['brand'].value_counts()
df['brand'].nunique()
threshold = 100
repl = counts[counts <= threshold].index
pd.get_dummies(df['brand'].replace(repl, 'uncommon')).sample(5)
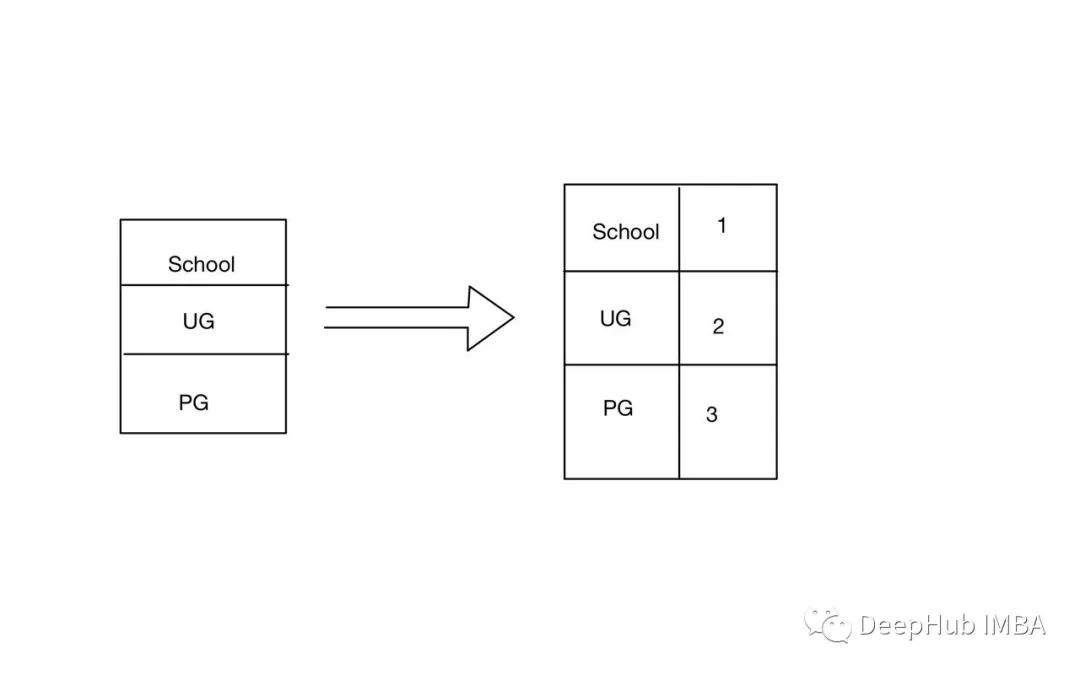
序列化标签编码(ORDINAL ENCODING)
这种编码方式仅用于序数类别,因为排名是根据类别的重要性来提供的。例如下表PHD被认为是最高的学位,所以给了它最高的标签。
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['Poor','Average','Good'],['School','UG','PG']])
oe.fit(X_train)
X_train = oe.transform(X_train)
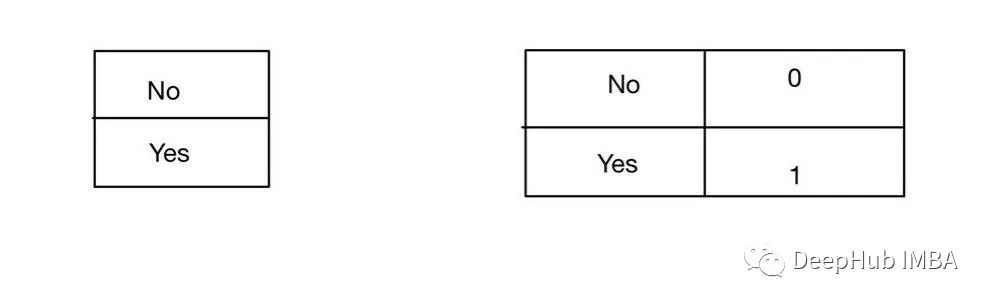
标签编码(LABEL ENCODING)
标签编码与序列化标签编码是相同的,但是它编码后的数字并不包含序列的含义。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(y_train)
le.classes_
目标指导的序列化编码
这种方法根据输出计算每个分类变量的平均值,然后对它们进行排名。如下表所示
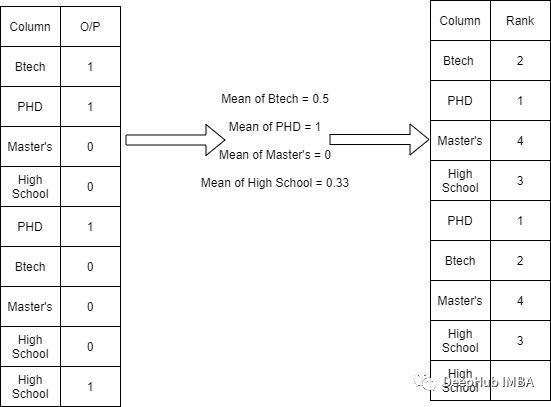
在序数类别中,我们可以应用这项技术,因为我们最后输出的结果包含了顺序的信息。
平均数编码(MEAN ENCODING)
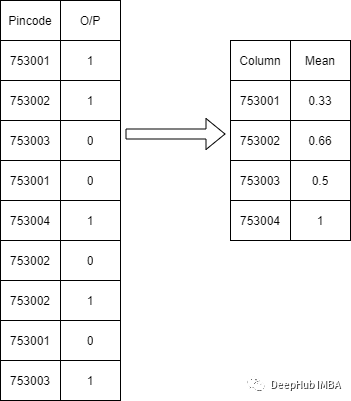
在这种方法将根据输出将类别转换为其平均值。在有很多特定列的分类变量的情况下,可以应用这种类型的方法。
例如,下面的表中,我们根据特征的类别进行分组,然后求其平均值,并且使用所得的平均值来进行替换该类别
作者:sumit sah