
pandas.的query函数为我们提供了一种编写查询过滤条件更简单的方法,特别是在的查询条件很多的时候,在本文中整理了10个示例,掌握着10个实例你就可以轻松的使用query函数来解决任何查询的问题。

首先,将数据集导入pandas DataFrame - df
import pandas as pd
df = pd.read_csv("Dummy_Sales_Data_v1.csv")
df.head()

它是一个简单的9999 x 12数据集,是使用Faker创建的,我在最后也会提供本文的所有源代码。
在开始之前,先快速回顾一下pandas -中的查询函数query。查询函数用于根据指定的表达式提取记录,并返回一个新的DataFrame。表达式是用字符串形式表示的条件或条件的组合。
PANDAS DATAFRAME(.loc和.iloc)属性用于根据行和列标签和索引提取数据集的子集。因此,它并不具备查询的灵活性。而括号符号[]可以灵活地基于条件过滤数据帧,但是如果条件很多的话编写代码是繁琐且容易出错的。
pandas query()函数可以灵活地根据一个或多个条件提取子集,这些条件被写成表达式并且不需要考虑括号的嵌套
在后端pandas使用eval()函数对该表达式进行解析和求值,并返回表达式被求值为TRUE的数据子集或记录。所以要过滤pandas DataFrame,需要做的就是在查询函数中指定条件即可。
使用单一条件进行过滤
在单个条件下进行过滤时,在Query()函数中表达式仅包含一个条件。返回的输出将包含该表达式评估为真的所有行。
示例1
提取数量为95的所有行,因此逻辑形式中的条件可以写为 -
Quantity == 95
需要将条件写成字符串,即将其包装在双引号“”中。query代码如下
df.query("Quantity == 95")

看起来很简单。它返回了数量为95的所有行。如果用一般查询的方式可以写成:
df [df [“Quantity”] == 95]
但是,如果想在同一列中再包含一个条件怎么办?
它在括号符号中又增加了一对方括号,如果是3个条件或者更多条件呢?那么他就变得难以管理。这就是Query的优势了。
在多个条件过滤
一个或多个条件下过滤,query()的语法都保持不变
但是需要指定两个或多个条件进行过滤的方式
- and:回在满足两个条件的所有记录
- or:返回满足任意条件的所有记录
示例2
查询数量为95&单位价格为182 ,这里包含单价的列被称为UnitPrice(USD)
因此,条件是 -
Quantity == 95
UnitPrice(USD) == 182
那么代码就是:
df.query("Quantity == 95 and UnitPrice(USD) == 182")
这个查询会报错:
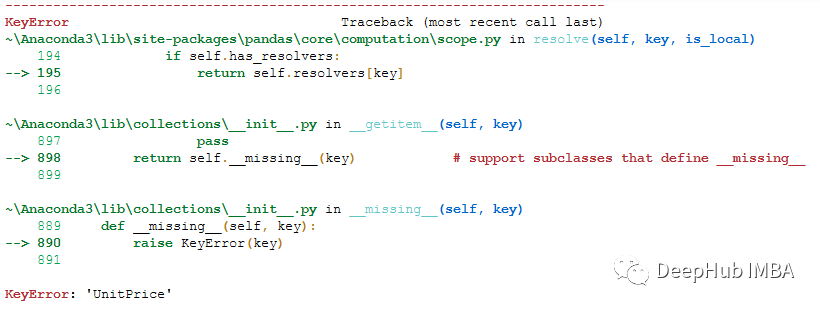
但是为什么报错?
这是因为query()函数对列名有一些限制。列名称UnitPrice(USD)是无效的。我们要使用反引号把列名包含起来
df.query("Quantity == 95 and `UnitPrice(USD)` == 182")

当两个条件满足时,只有3个记录。
或者我们直接将列名改成合理的格式:
df.rename(columns={'UnitPrice(USD)':'UnitPrice',
'Shipping_Cost(USD)':'Shipping_Cost',
'Delivery_Time(Days)':'Delivery_Time'},
inplace=True)
这里就不需要使用反引号了:
df.query("Quantity == 95 and UnitPrice == 182")
示例3
我们现在只需要满足一个条件:
df.query("Quantity == 95 or UnitPrice == 182")

它返回满足两个条件中的任意一个条件的所有列。
我们也可以使用 | 替代 or关键字。
示例4
假设想获得数量不等于95的所有行。最简单的答案是在条件之前使用not关键字或否定操作符〜
df.query("not (Quantity == 95)")

结果它包含数量不是95的所有行。
其实这里的条件不一定必须是相等运算符,可以从==,!=,>,<,≥,≤中选择,例如
df.query("Quantity != 95")
文本列过滤
对于文本列过滤时,条件是列名与字符串进行比较。
请Query()表达式已经是字符串。那么如何在另一个字符串中写一个字符串?将文本值包装在单个引号“”中,就可以了
示例5
想获得即状态“未发货”所有记录,可以在query()表达式中写成如下的形式:
df.query("Status == 'Not Shipped'")

它返回所有记录,其中状态列包含值 - “未发货”。
与数值的类似可以在同一列或不同列上使用多个条件,并且可以是数值和非数值列上条件的组合。
除此以外, Pandas Query()还可以在查询表达式中使用数学计算
查询中的简单数学计算
数学操作可以是列中的加,减,乘,除,甚至是列中值或者平方等,如下所示:
示例6
df.query("Shipping_Cost*2 < 50")
虽然这个二次方的操作没有任何的实际意义,但是我们的示例返回了所有达到要求的行。

我们还可以在一个或多个列上包含一些复杂的计算。
示例7
我们随便写一个比较复杂的公式:
df.query("Quantity**2 + Shipping_Cost**2 < 500")

如果使用最原始的[]的形式,这个公式的查询基本上没法完成,但是使用query()函数则变为简单的多
除了数学操作,还可以在查询表达式中使用内置函数。
查询中的内置函数
Python内置函数,例如SQRT(),ABS(),Factorial(),EXP()等,也可以在查询表达式中使用。
示例8
查找单位价格平方根的超过15的行
df.query("sqrt(UnitPrice) > 15")

query()函数还可以在同一查询表达式将函数和数学运算整合使用
示例9
df.query("sqrt(UnitPrice) < Shipping_Cost/2")

到目前为止,所有查询示例都是关于数值和文本列的。但是,query()的还不仅限于这些数据类型,对于日期时间值 Query()函数也可以非常灵活的过滤。
日期时间列过滤
使用Query()函数在日期时间值上进行查询的唯一要求是,包含这些值的列应为数据类型dateTime64 [ns]
在示例数据中,OrderDate列是日期时间,但是我们的df其解析为字符串,所以我们需要先进行转换:
df["OrderDate"] = pd.to_datetime(df["OrderDate"], format="%Y-%m-%d")
为了提取有关日期的有用信息并在Query()需要使用DT提取器,DT是一种访问对象,用于提取日期时间,例如DateTime系列的属性。
示例10
获得八月份的所有记录
df.query("OrderDate.dt.month == 8")

所有记录都是八月份的。OrderDate.dt.month显示了如何使用DT访问者仅提取整个日期值的月份值。
如果提取2021年8月订购日为15或以上的所有订单,可以写成这样
df.query("OrderDate.dt.month == 8 and OrderDate.dt.year == 2021 and OrderDate.dt.day >=15")

DT很好用并且可以在同一列上结合了多个条件,但表达式似乎太长了。所以可以通过编写更非常简单的表达式来过滤:
df.query("OrderDate >= '2021-08-15' and OrderDate <= '2021-08-31'")
我们直接传递一个符合日期格式的字符串,它会自动的转换并且比较
将上面的所有内容整合:
df.query("OrderDate >= '2021-08-15' and OrderDate <= '2021-08-31' and Status == 'Delivered'")

查询表达式包含了日期时间和文本列条件,它返回了符合查询表达式的所有记录
替换
上面的查询中都会生成一个新的df。这是因为:query()的第二个参数(inplace)默认false。
与一般的pandas提供的函数一样,Inplace的默认值都是false,查询不会修改原始数据集。如果我们想覆盖原始df时,需要将intplace = true。但是一定要小心使用intplace = true,因为它会覆盖原始的数据。
总结
我希望在阅读本文后,您可以更频繁,流利地使用Pandas Query()函数,因为Query可以方便以过滤数据集。这些查询的函数我每天都会或多或少的使用。
本文的所有示例代码在这里:
https://github.com/17rsuraj/data-curious/blob/master/TowardsDataScience/pandas_query_deep_dive.ipynb