
大型网站类目目录的数量很大,一般都无法进行手动标记,所以理解大型目录的内容对在线业务来说是一个重大挑战,并且这使得对于新产品发现就变得非常困难,但这个问题可以通过使用自监督神经网络模型来解决。
在过去我们一直使用人工在系统中进行产品的标记,这样的确可以解决问题但是却耗费了很多人力的成本。如果能够创建一种机器学习为基础的通用的方式,在语义上自动的关联产品,并深入了解现有的目录内容,就可以将产品推荐、搜索、促销活动和运营情报变为自动化的操作。
在这篇文章中,描述了一种通过在网站内部的用户搜索数据上使用自监督学习技术来训练高质量的可推广嵌入的方法。除此以外本位还列举了一些替代方法,并详细介绍了我们所选解决方案的模型训练和评估过程和各个方法的优略对比。
大型网站的类目问题
对于大型网站来说,网站目录的内容并不是恒定的,如果我们添加了新的类目,对于机器学习来说则需要训练新的模型,有没有一种能够在不建立定制模型的情况下处理目录的方法呢?首先,了解类目的内容对于运营业务和面向消费者内容搜索很重要,因为:
- 类目可以根据消费者的已知偏好进行新的推荐
- 当消费者与新商店互动时,将产品品推荐给他们
- 在搜索查询时推荐更相关商店和产品
- 自动推荐类似消费者最近订单历史的促销
- 了解消费者在搜索后购买哪些物品
等等。。
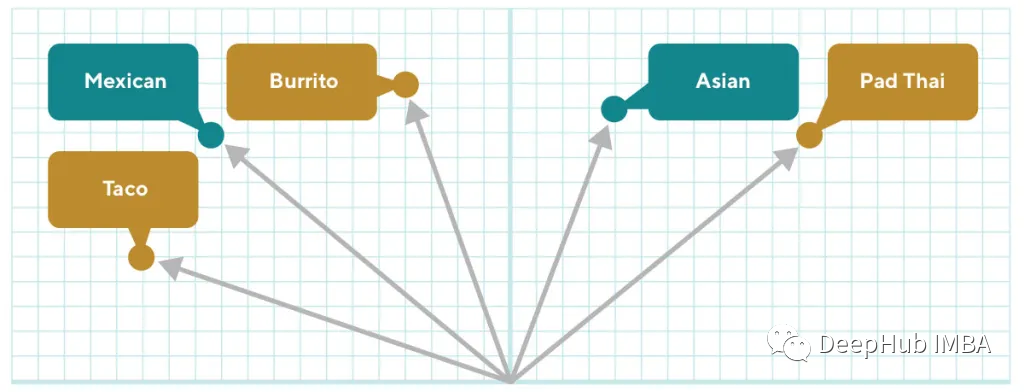
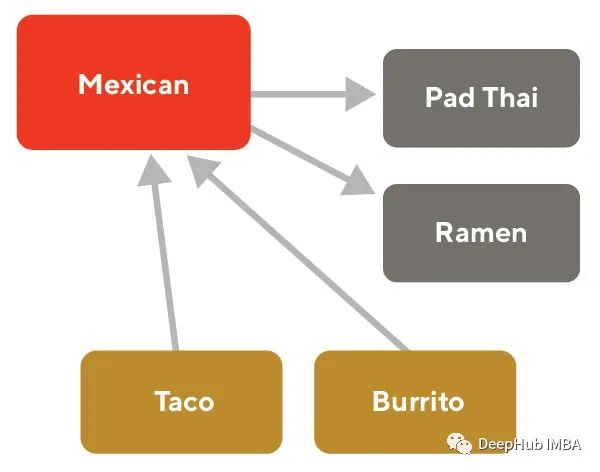
在同一潜在空间中查询(绿色)和产品(黄色)表示的示例。我们想学习一个嵌入表示形式,其中相同颜色的线具有高余弦相似性(之间的角度很小),而不同颜色的界线则具有很小的余弦相似性(它们之间的大角度)。这意味着我们需要将查询和项目编码到同一空间中,并为它们两个都学习高质量的表示。
在搜索的背景下,我们还希望能够创建一个可以与产品和商铺嵌入进行比较的可查询嵌入。模型需要将查询和产品置于相同的潜在空间(上图1)以使其可比。一旦将查询“mexican”和产品“taco”进行嵌入,嵌入空间就可以告诉我们二者是相关的(余弦相似度)。我们还需要将商铺和购买者嵌入在同一潜在空间中, 这使我们能够使用嵌入方式包括目录知识来进行商铺的推荐。
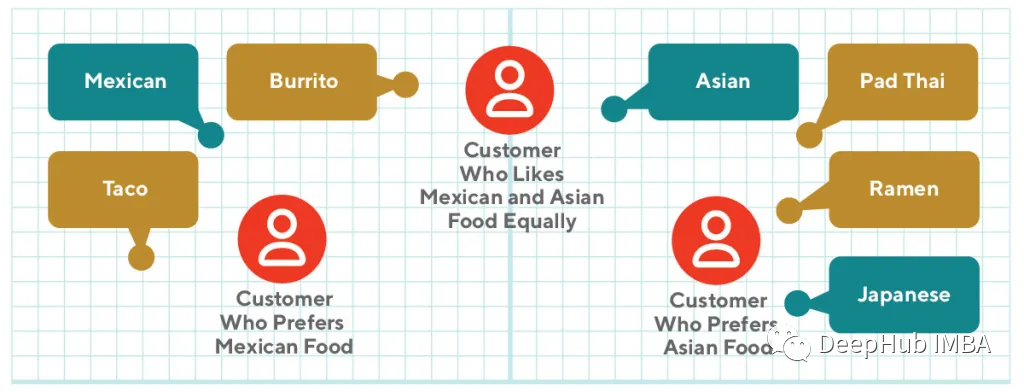
通过定义消费者嵌入(蓝色)为他们的商品嵌入(绿色)的平均值,我们可以了解消费者的不同偏好。在上图中,经常购买墨西哥菜的消费者比经常购买亚洲菜的消费者更接近墨西哥菜。同时购买这两种食品的消费者将会在墨西哥食品和亚洲食品集群之间形成一种嵌入。
所以我们要解决的问题是如何使用有限的标记数据有效地在非常罕见的类上训练,这就需要利用自监督的方法来训练嵌入。但在开始之前,我们先回顾一下传统的技术来训练嵌入,这样可以让我们理解为什么它们不能解决问题。
构建嵌入的技术的回顾
对于上面的用例来说,传统的方法包括对条目id进行Word2vec训练或对深度学习分类器进行训练并取最后一层线性层的输出。在自然语言处理(NLP)中,对BERT这样的大型预训练模型进行微调也变得很常见。但是对于不断发展的大而稀疏的目录问题,我们将一一介绍这些方法:
方案1:在实体id上嵌入Word2vec
可以使用访问或购买等客户行为对任意一组实体id进行Word2vec嵌入训练。这些嵌入通过假设在同一会话中与客户交互的实体彼此相关来学习id之间的关系,这与Word2vec分布假设类似。商店和客户的行为定期训练这类嵌入,以便在推荐和其他个性化应用程序中使用。见下图
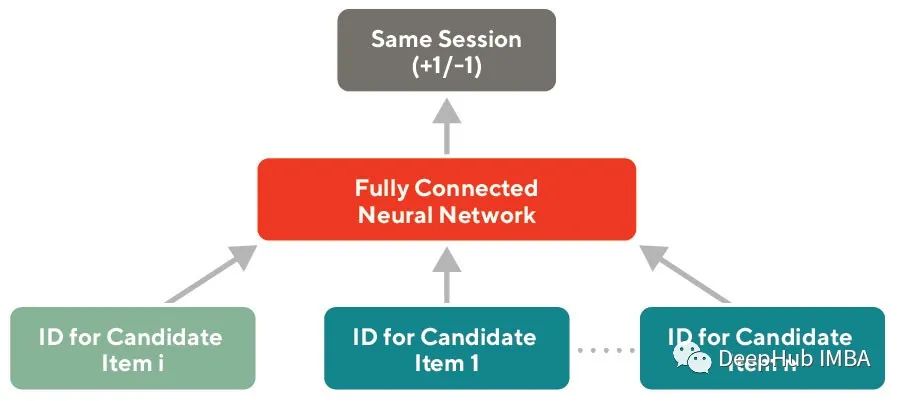
Word2vec嵌入在为大型目录保留语义相似性方面存在一些缺陷。当新实体添加到目录中时,它们需要定期进行再训练。如果每天都要添加数百万个产品,每天重新训练这些嵌入在计算上是非常昂贵的。使用这种方法训练的嵌入容易出现稀疏性问题,因为很少与客户交互的id没有得到很好的训练。
方案2:基于监督任务的深度神经网络训练嵌入
深度神经网络在分类任务上的训练误差较低,可以学习到高质量的目标类表示。网络最后一层隐藏层的输出可以被视为原始输入的嵌入。对于多样化和大型高质量的标记数据集,这种方法可以非常有效地学习高质量的嵌入,并可以在分类任务中重用。
这种训练方法并不总是保证底层嵌入具有良好的度量特性。因为我们的优先级是下游应用程序的易用性,希望这些嵌入可以轻松地使用简单的指标,如余弦相似度进行比较。由于这种方法是需要监督的,学习度量的质量在很大程度上取决于训练集标注的质量。我们需要确保数据集具有良好的负样本,以确保模型能够学会区分密切相关的标签。对于数据样本有限的稀有类,这个问题就变得尤其严重。所以无监督的解决方案可以通过从未标记的数据自动生成样本并学习标签的表示来规避这个问题。
方案3:微调一个预先训练好的语言模型,比如BERT
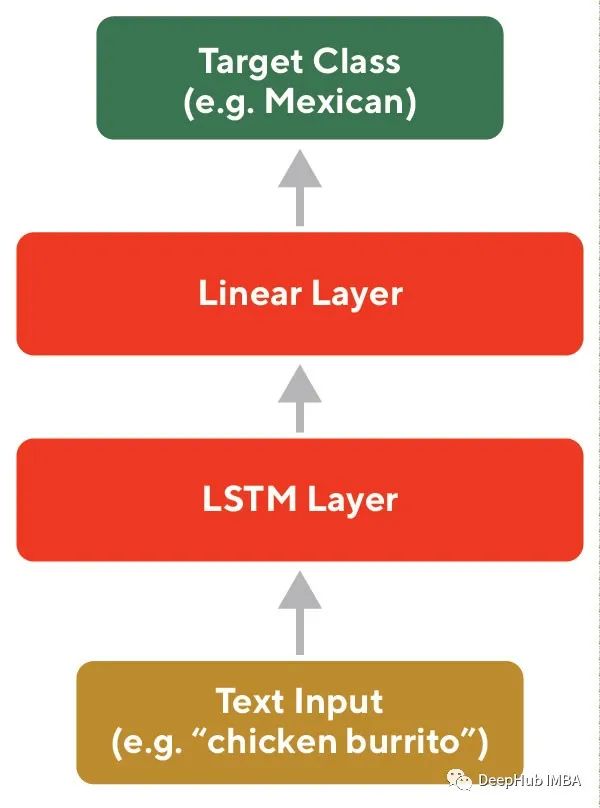
随着最近在大型语料库上训练大型NLP模型方面取得的进展,通过迁移学习对这些模型进行微调学习针对特定任务的嵌入已经成为一种流行的方法(下图5中的示例架构)。BERT是一种流行的预训练模型,这种方法可以使用开源库直接实现,并且可以克服数据稀疏的问题,并且作为一个非常良好的基线模型。
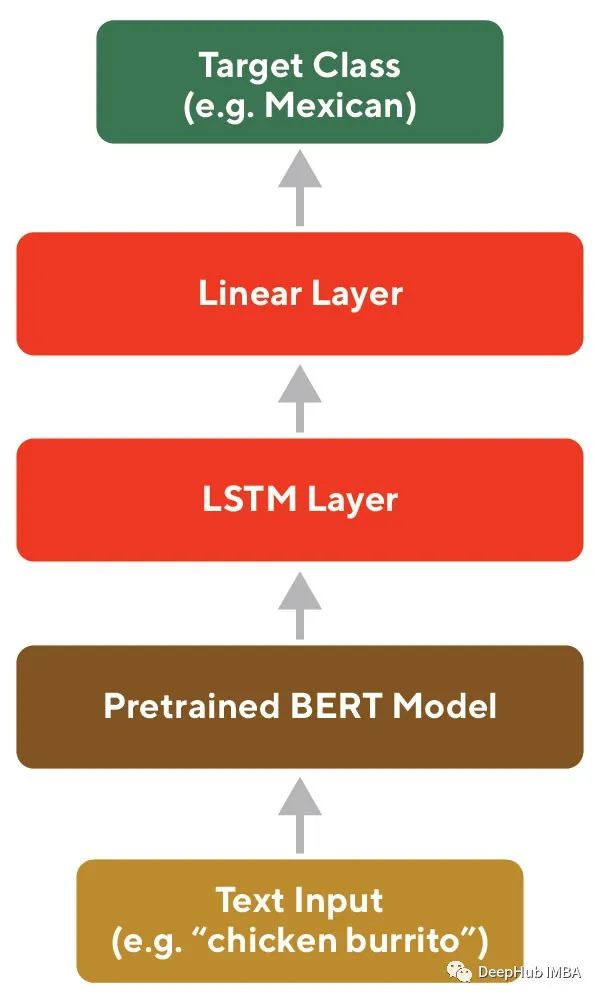
虽然BERT嵌入是在基线上的一个显著改进,但由于模型规模的原因它的训练和推理非常耗时。即使使用蒸馏模型(如DistilBERT或ELECTRA),也可能比小得多的定制模型慢得多。另外就是如果有足够多的领域特定数据,即使它是未标记的,与预先训练的语言模型相比,自监督方法对于特定任务具有更好的度量属性。
通过自监督学习训练嵌入
在调研了上述方法之后,我们使用自我监督的方法基于类目名称和搜索查询来训练嵌入。通过使用子词信息,如字符级信息,这些嵌入也可以推广到训练数据中没有出现的文本。
为了保证良好的度量性能,使用了带有三重损失的孪生神经网络(也称为Siamese Neural Network)架构。三重损失试图在潜在空间中把相似的样本挤到一起,把不同的样本分开。孪生神经网络可以确保用于查询和产品文本的编码以一种保持相似示例之间距离的方式嵌入到相同的潜在空间中。
构建数据集
为了训练三重损失,我们需要一个结构为<anchor, positive, negative>的数据集。将anchor定义为原始查询文本,并将查询的“相关”和“不相关”分别视为positive和 negative。
为了构造这个数据集(下图6中的示例),需要开发一组启发式方法来制定训练任务。使用以下启发式方法分别确定正训练样本和负训练样本对应的相关和不相关项目:
如果用户搜索了查询Q,然后在同一个会话中立即购买了X,并且X是购物车中最贵的商品,那么商品X与查询Q相关
这种对于正样本的启发式方法确保我们只取购物车中的主要商品,我们认为它可能是最相关的
如果X是在查询R中购买的,Q和R的Levenshtein距离是> 5,那么商品X对于查询Q来说是不相关的
这种针对负样本的启发式方法保证了为类似查询购买的商品(例如“burger”和“burgers”)不会被视为无关的,生成高质量的负样本对于防止模式崩溃是至关重要的。在这个例子中,即使是文本中这种简单的启发式和自然的变化对于训练来说也足够了,但是可能还有更好的方法需要我们去研究。

我们还对输入进行了最小的规一化,将所有字符串小写并删除标点符号。这使得经过训练的模型能够适应拼写错误和其他语言的自然变化。
为了确保模型可以推广到词汇表外标记的样本,我们使用字符三元组序列来处理输入。我们试验了多种替代标记方案(单词ngram、字节对编码、WordPiece和单词+字符ngram),但发现三元组具有相似或更好的预测性能,可以更快地训练。

模型的架构
该模型是一个孪生网络(下图8),它使用由深神经网络组成的编码器和输出最终嵌入的线性层。所有权重都在编码器之间共享。由于权重是在编码器之间共享的,所以所有头部的编码都进入相同的潜在空间。编码器的输出用于计算三重损失。
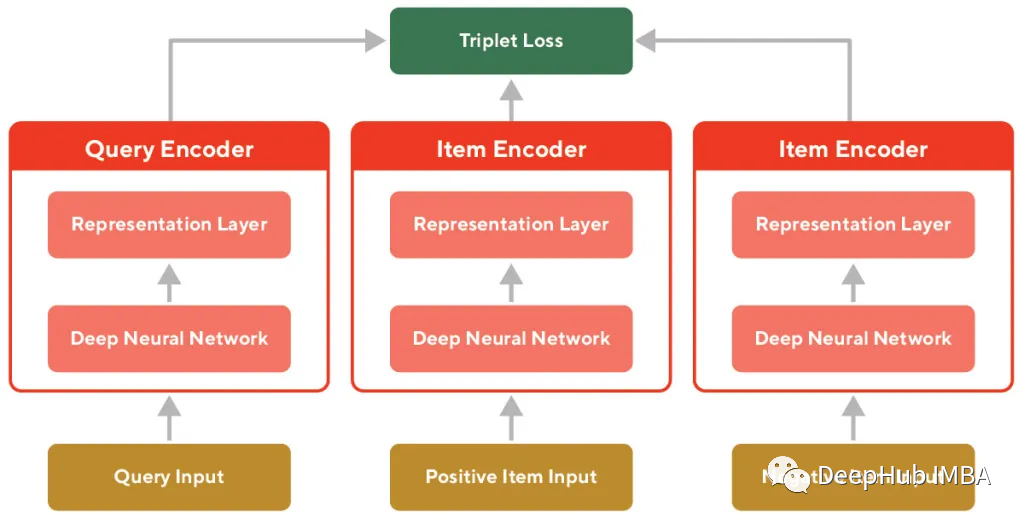
损失计算如下:
L(a, p, n, margin) = max(d(a, p) -d(a, n) + margin, 0)
对于“Mexican”查询(红色),三重损失试图将positive(黄色)的嵌入靠近,并将negative(灰色)分开。
神经网络代码样本。在此处抽取编码器的详细信息,以说明如何计算前向传播和损失。
classSiameseNetwork(torch.nn.Module):
def__init__(self, learning_rate, transforms, model, **kwargs):
super().__init__()
self.learning_rate=learning_rate
self.transforms=transforms
self._encoder=model(**kwargs)
self.loss=torch.nn.TripletMarginLoss(margin=1.0, p=2)
defconfigure_optimizers(self):
returntorch.optim.Adam(self.parameters(), lr=self.learning_rate)
def_loss(self, anchor, pos, neg):
returnself.loss(anchor, pos, neg)
defforward(self, anchor, seq1, seq2):
anchor=self._encoder(anchor)
emb1=self._encoder(seq1)
emb2=self._encoder(seq2)
returnanchor, emb1, emb2
实际的编码器体系结构是双向LSTM,然后是线性层。LSTM负责将一系列字符的处理到向量中。
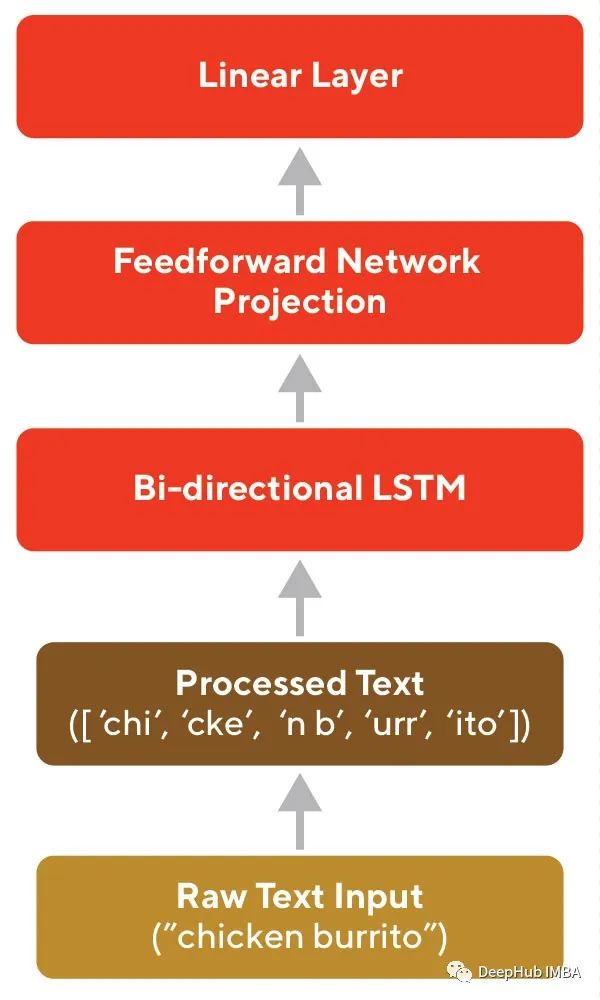
下面是编码器的代码
classLSTMEncoder(torch.nn.Module):
def__init__(self, output_dim, n_layers=1, vocab_size=None, embedding_dim=None, embeddings=None, bidirectional=False, freeze=True, dropout=0.1):
super().__init__()
ifembeddingsisNone:
self.embedding=torch.nn.Embedding(vocab_size, embedding_dim)
else:
_, embedding_dim=embeddings.shape
self.embedding=torch.nn.Embedding.from_pretrained(embeddings=embeddings, padding_idx=0, freeze=freeze)
self.lstm=torch.nn.LSTM(embedding_dim, output_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)
self.directions=2ifbidirectionalelse1
self._projection=torch.nn.Sequential(
torch.nn.Dropout(dropout),
torch.nn.Linear(output_dim*self.directions, output_dim),
torch.nn.BatchNorm1d(output_dim),
torch.nn.ReLU(),
torch.nn.Linear(output_dim, output_dim),
torch.nn.BatchNorm1d(output_dim),
torch.nn.ReLU(),
torch.nn.Linear(output_dim, output_dim, bias=False),
)
defforward(self, x):
embedded=self.embedding(x) # [batch size, sent len, emb dim]
output, (hidden, cell) =self.lstm(embedded)
hidden=einops.rearrange(hidden, '(layer dir) b c -> layer b (dir c)', dir=self.directions)
returnself._projection(hidden[-1])
模型评估
根据定性指标(如对嵌入UMAP投影的评估)和定量指标(如基线f1分)来评估模型。通过观察嵌入的UMAP投影来评估定性结果(下图)。可以看到相似的类被投射到彼此附近,这意味着嵌入可以很好地捕捉语义相似性。
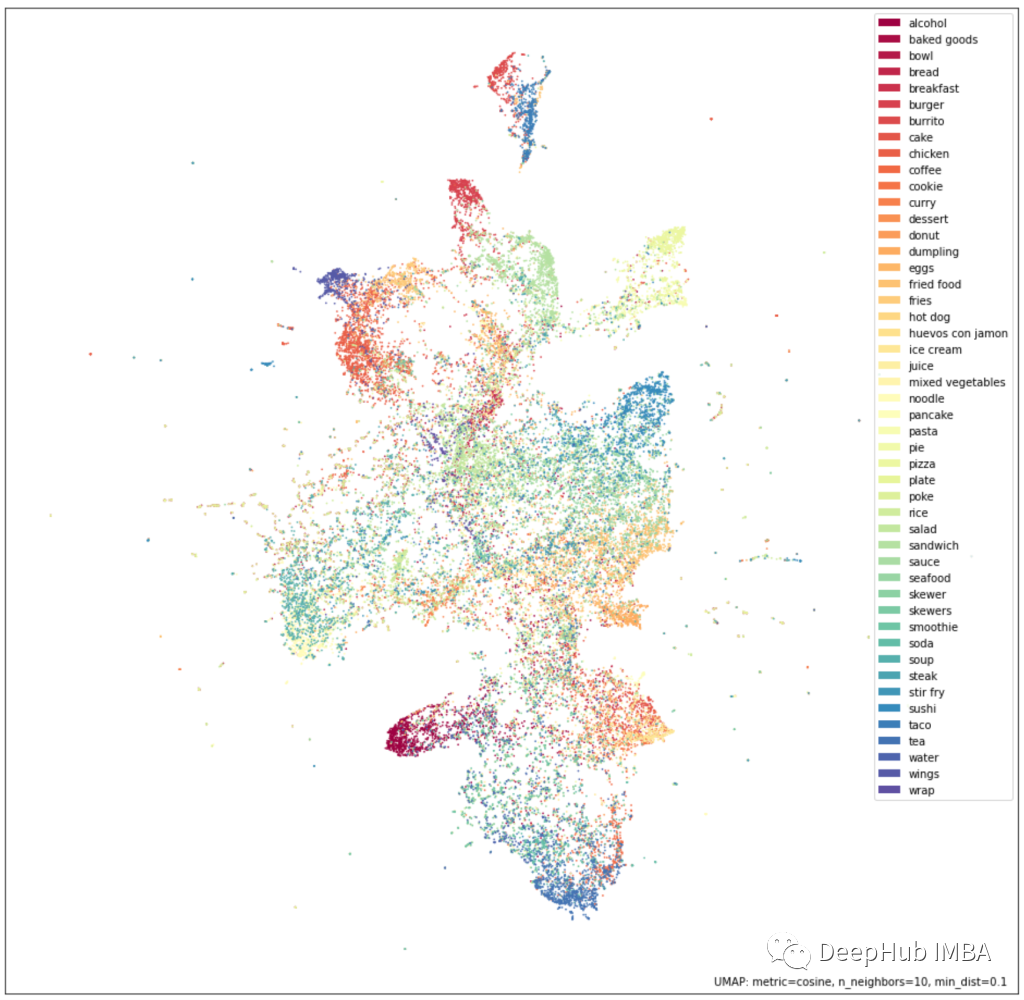
考虑到定性评估的良好结果,我们还在一些基线分类任务上对模型进行了更严格的基准测试,这样可以了解嵌入的质量以及在其他内部模型中使用它们的潜在收益。

模型的f1评分比基线(FastText分类器)提高了约23%。这是一个巨大的提升,特别是因为Siamese神经网络是在零样本分类任务上评估的,而基线是在标记数据上训练的。
使用这些嵌入作为下游分类任务的特征,可以显著提高样本效率。在训练标记模型时,使用FastText分类器训练同样精确的模型需要超过现有标记数据三倍数据量。这表明,学习得到的表征携带了关于文本内容的大量信息。
嵌入应用程序示例
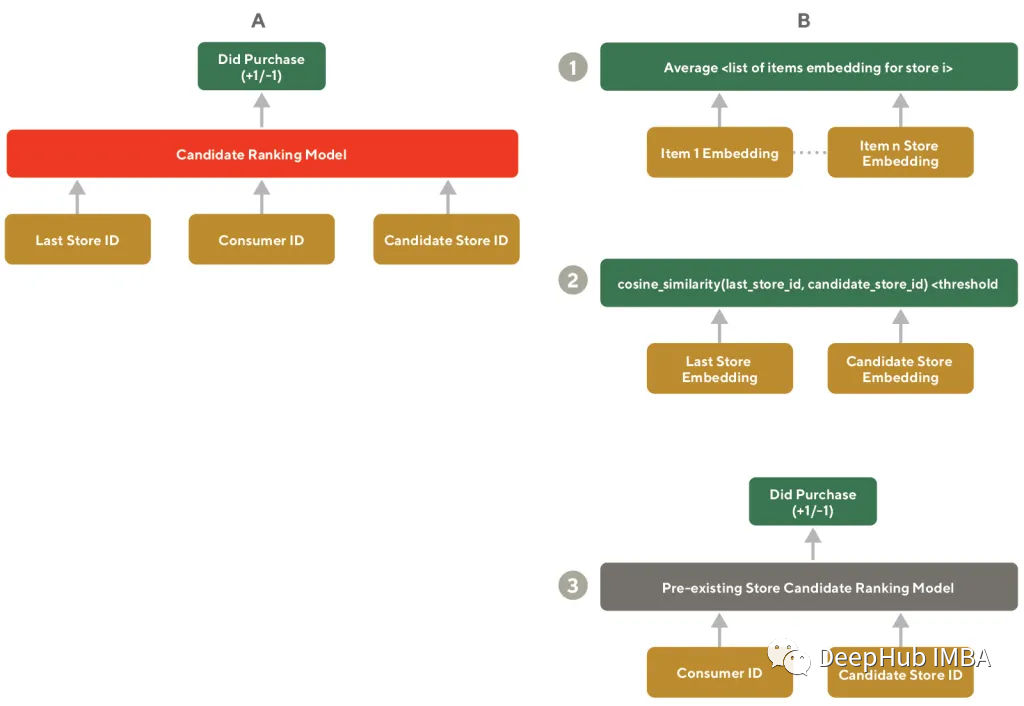
为了改善对客户的内容推荐,我们通过客户最近购买的店铺类别来推荐相似的其他店铺。如果没有嵌入则需要构建一个专门的模型,该模型考虑到<consumer_id,last_store_id>,并尝试预测每个候选store_id上购买率。但是我们这里使用我们已经生成的嵌入,这就需要2个步骤:
- 在已经生成的嵌入中检索与last_store_id最相似的店铺
- 使用排名器,为每个客户进行筛选后的店铺进行个性化排名。
由于通过余弦相似度计算非常快速的,并且我们不需要为排名收集任何其他数据,下图是这一过程的详细信息。通过平均每个商铺中商品嵌入,还可以简单的生成一个商铺的语义嵌入,并且可以在批处理过程中完成,减少实时系统负载。
总结
自监督方法通常特别有助于在快速增长的目录中开发立即可重用的ML产品。虽然其他ML方法可能更适合于特殊任务,但自监督嵌入仍然可以为需要高质量文本数据表示的任务添加强大的基线。与现成的嵌入方法(如FastText或BERT)相比,通常特定于领域的嵌入方法更适合于内部应用程序(如搜索和推荐)。
引用:
1] Siamese Neural Networks for One-shot Image Recognition. https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
[2] A Simple Framework for Contrastive Learning of Visual Representations. https://www.cs.toronto.edu/~hinton/absps/simclr.pdf
[3] Deep Metric Learning with Triplet Loss. https://arxiv.org/pdf/1412.6622.pdf
[4] FaceNet: A Unified Embedding for Face Recognition and Clustering. https://arxiv.org/pdf/1503.03832.pdf
作者:Abhi Ramachandran
本文是doordash公司的在线实践分享,原文地址如下:
https://doordash.engineering/2021/09/08/using-twin-neural-networks-to-train-catalog-item-embeddings/