
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
Cart字段回归树算法
CART回归树的字段选择方式、如何利用模型树来提升CART回归树的效能
CART回归树和分类数大体上是相同的。只有在叶结点的地方比较特别,分类树在叶结点是yes或者no,回归树就是一个值。
数值其实就是平均数,方差作为不纯度衡量的标准(衡量目前的分布,是不是有一致性的倾向,就和之前的entropy,gain ratio差不多)
之前发明ID3,C4.5,C5.0的人也搞了一个M5,其实就是CART的加强版预测的比较准。
我们先说明CART回归数的基本内容,再说明M5对它的改进
案例:

字段1代表的是地理位置,字段2代表的是房屋类型,是独立的还是连接的,字段3代表的是与学区房的距离,字段4代表的是房屋大小。字段5代表的房屋社区有多少户人家(一般户数越多,价格越低)。实际成交价格。
这里我们把房屋价格作为均值,来预测房屋价格可以吗,当然是可以的,价格的均值是173.5,如果我们用这个来预测,我们就会发现,预测结果误差比较大。均值代表我们的机械模型,我们的结果一定要比这个好。我们发现如果预测结果差,那么它的方差误差也会非常大
现在我们了解了,我们要用均值为预测结果,方差为预测依据。那我们就可以建立CART模型了。

我们发现市区的房子,大概比郊区的房子贵2.5倍。
我们这个时候用252K来预测Urban的房屋价格。105K来预测Rural房屋价格。肯定是要比178.5K来预测二者价格要准确许多。
然后我们在用房屋类型字段进行划分,我们发现,结果是300K和220K
右边Type效果,所以我们使用Miles进行分堆,就是用之前的二分法。进行分堆。
我们发现,其实它很像是吧数据根据字段进行一个聚类,然后预测。所以效果很好,就算到现在也非常好用。
CART回归树的字段选择方式:
之前我们叶节点用的都是平价值,那我们就想,能不能不用平均值来预测,而采用线性回归来预测呢?发现效果很好。
我们这里用的是简单线性回归,它不采用很多的字段,就采用一个字段,进行预测。
比如左下角的那个数据,我们原本使用的是300这个平均值作为预测结果。但是现在我们选用简单线性回归,我们那第一个字段来试一试,0.1*2200+90=310,发现结果和第一个字段是一致的,相对来说比较准确。

小插曲:M5如何利用模型树来提升CART回归树的效能
M5的改进就是在这一步,选择不使用一元的简单线性回归,而是采用多元的线性回归来改进叶节点的精确性。
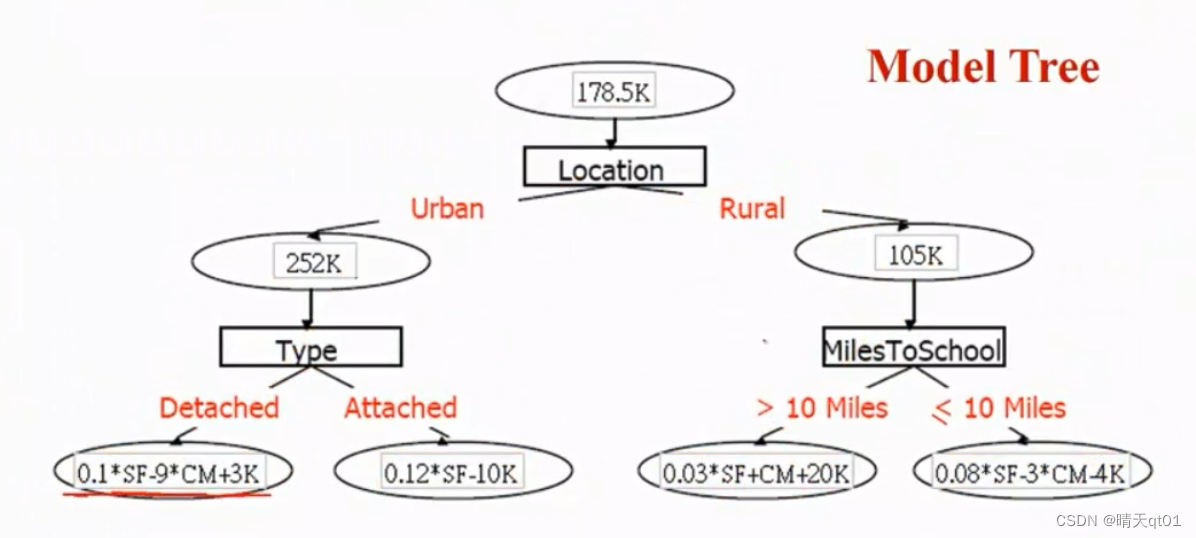
他把这个命名为模型树,因为你会发现如果树不成长的话,最差也是一个多元线性回归的模型进行预测。如果树展开,有4个叶节点,那么就说明有4个多元线性回归预测模型。那肯定要比一个多元线性回归预测要准确。
为什么效果一定会好呢?
举个例子,如果现在出现了一个非线性的模型它是呈现抛物线的情况,那么只有一条多元线性回归线的话,点到线的距离,就是误差值。

但是如果我们做2条多元线性回归,左边用一条线性回归模型来预测,右边用另一台多元线性回归模型来预测,那么就可以用多条线性回归模型来预测非线性的问题了。
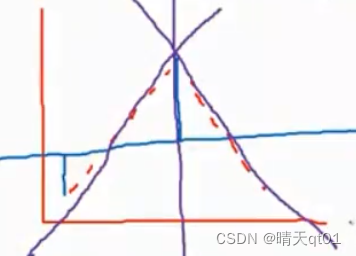
模型树可以做非线性的回归,所以它一定会比多元线性回归的效果好。最差就是退回多元回归线性模型。
继续CART字段选择方式
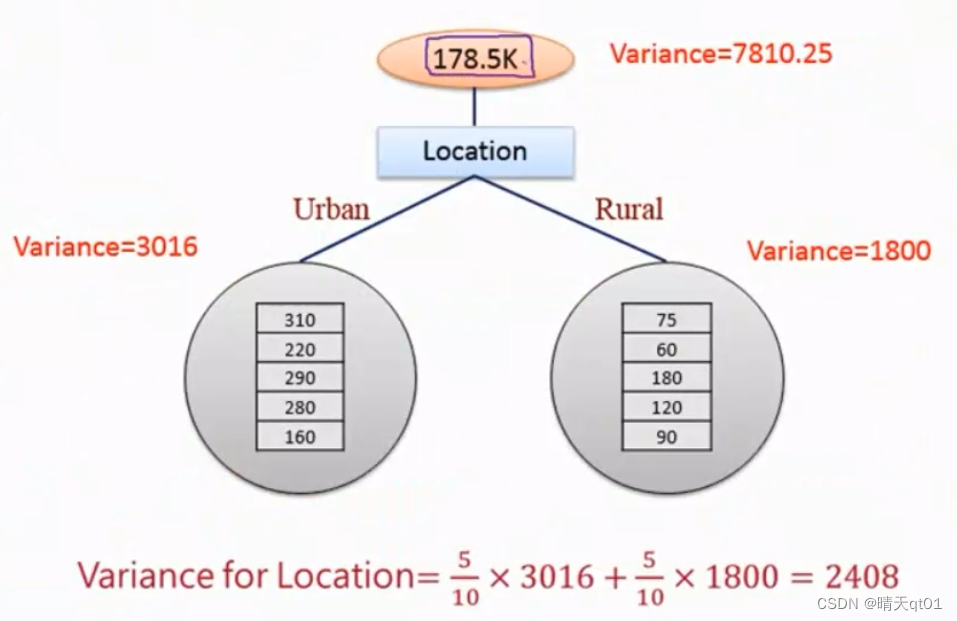
如果我们用178.5继续预测,我们说预测结果误差太大,那怎么表现这个误差大呢?我们就采用方差的形式来表现这个误差。于是我们和之前CART的分类树一样,我们一个一个试,找出字段中效果最好的二元分支。
我们发现用location把数值将分差降低到2408,原本是7810.25.
然后我们计算其他的字段

明显location效果主要些。
然后是连续型字段,mails
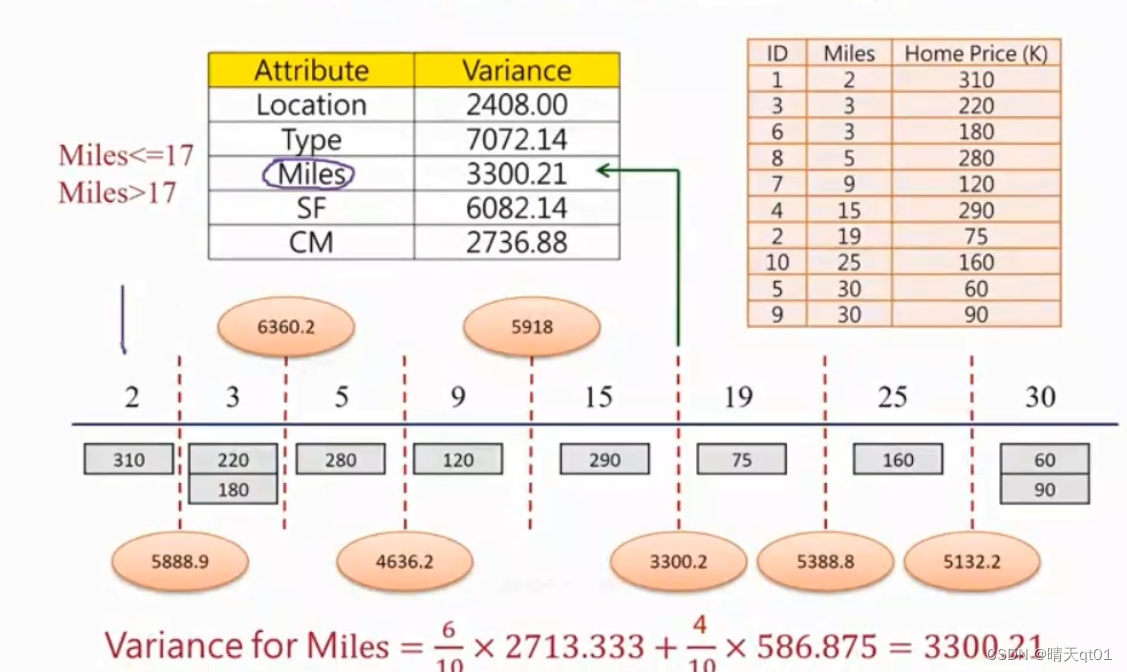
每个切点我们都试一试。方差最小的情况是以17为分割点3300。
然后我们选择最好的字段,也就是location。
M5改善的效果就是叶节点利用多元线性回归方程(模型树来预测模型。)来作为预测结果。
版权归原作者 晴天qt01 所有, 如有侵权,请联系我们删除。