
数据可视化是数据分析的一个重要方面,它提供了一种理解数据并从中得出有意义见解的方法。Pandas 是最常见的于数据分析的 Python 库,它基于Matplotlib扩展了一些常用的可视化图表,可以方便的调用,本篇文章就让我们看看有哪些图表可以直接使用。
在本文中,我们介绍使用 Pandas 进行数据可视化的基础知识,包括创建简单图、自定义图以及使用多个DF进行绘图。
我们将导入必要的库并加载示例数据集。
importpandasaspd
importmatplotlib.pyplotasplt
df=pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv")
我们使用泰坦尼克的示例数据集,包含有乘客的信息,包括他们的船舱等、年龄、票价和生存状态等信息。
创建简单的图
Pandas的 plot 方法提供了创建基本图(例如线图、条形图和散点图)的简单方法。让我们看几个例子。
线图
线图用于表示连续间隔或时间段内的数据趋势。要创建线图,调用plot 方法时需要将 kind 参数指定为 line。
df.plot(kind="line", x="age", y="fare")
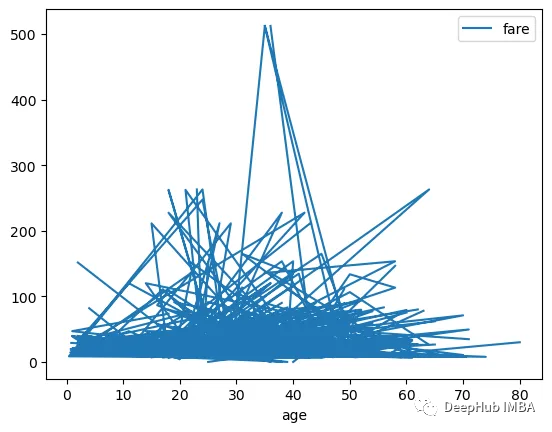
看着很乱对吧,这是因为我们展示的数据无法用线图进行表示,下面我们用更好的图表表示年龄这个字段
直方图
我们可以在字段后直接使用hist方法来生成数据的直方图
df.age.hist(figsize=(7.3,4), grid=False)
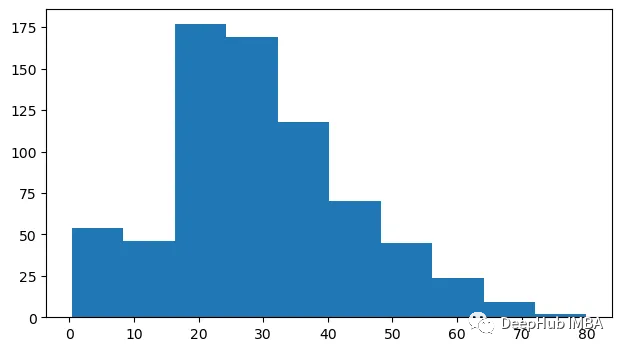
这样是不是就一目了然了,能够清楚地看到年龄的分布情况
条形图
条形图用于表示分类数据,其中每个条代表一个特定类别。要创建条形图,可以 pandas DataFrame 上使用 plot 方法并将 kind 参数指定为 bar。
df["class"].value_counts().plot(kind="bar")
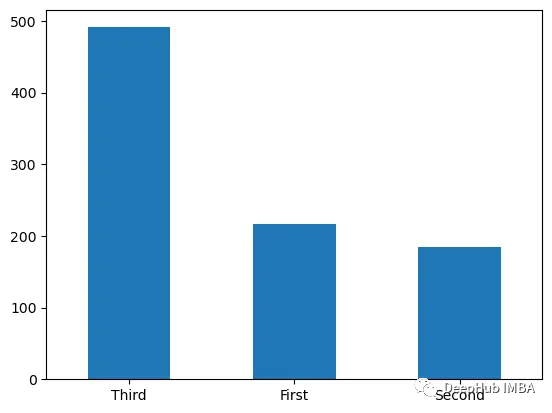
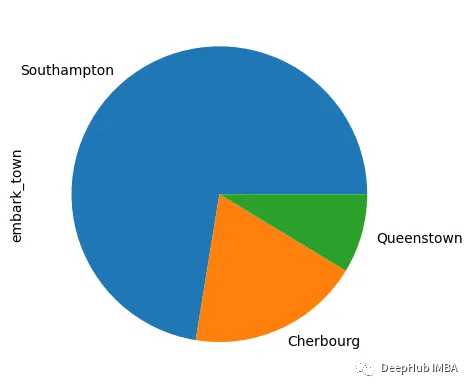
饼图
饼图与条形图类似,但是它主要来查看数据的占比
df["embark_town"].value_counts().plot(kind="pie", rot=0)
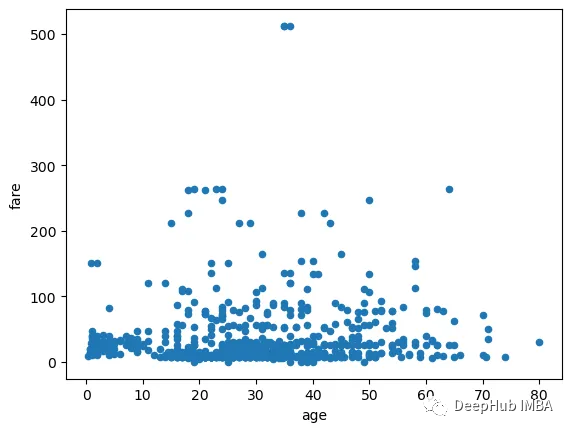
散点图
散点图用于表示两个连续变量之间的关系。要创建散点图使用 plot 方法将 kind 参数指定为 scatter。
df.plot(kind="scatter", x="age", y="fare")
Plot方法
Pandas的可视化主要使用.plot()方法,它有几个可选参数。其中最重要的是kind 参数,它可以接受 11 个不同的字符串值,并根据这些值创建不同的图表:
- “area”面积图
- “bar”垂直条形图
- “barh”水平条形图
- “box”箱线图
- “hexbin” hexbin 图
- “hist”直方图。
- “kde”内核密度估计图表
- “density”是“kde”的别名
- “line”折线图
- “pie”饼图
- “scatter”散点图
如果你不指定kind 参数,它的默认值为“line”。也就是折线图。如果不向 .plot() 提供任何参数,那么它会创建一个线图,其中索引位于 x 轴上,所有数字列位于 y 轴上。虽然这对于只有几列的数据集来说是一个有用的默认值,但对于大型数据集及其多个数字列来说,它看起就不好了。
还有就是:作为将字符串传递给 .plot() 的 kind 参数的替代方法,DataFrame 对象有几种方法可用于创建上述各种类型的图:
.area()
.bar()
.barh()
.box()
.hexbin()
.hist()
.kde()
.density()
.line()
.pie()
.scatter()
还记得我们第一个直方图的.hist方法吗,他就是kind=‘hist’的一个替代。
定制图表样式颜色
我们还可以通过使用不同的参数来自定义图表的外观,例如标记的颜色、大小和形状、标签和标题。
df.plot(kind="scatter", x="age", y="fare", color="red", alpha=0.5)
plt.xlabel("Age")
plt.ylabel("Fare")
plt.title("Relationship between Age and Fare")
plt.show()
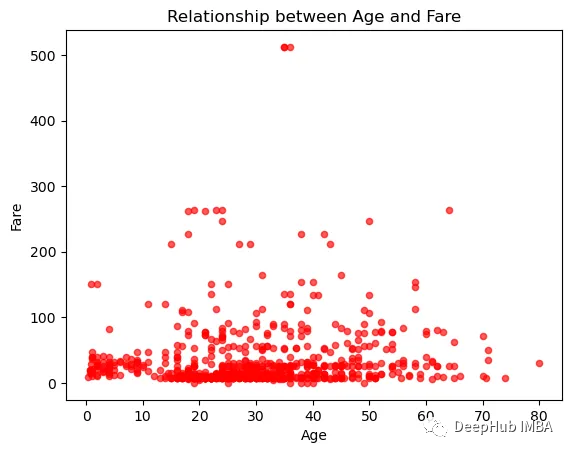
就像我们最初介绍的那样,pandas绘图的底层是使用Matplotlib,所以这些参数都是与Matplotlib一致的,我们可以随意进行调整。
多个DataFrame绘图
Pandas还没有提供多个DataFrame的方法,所以我们只能使用Matplotlib,就像下面这样:
df_survived=df[df["survived"] ==1]
df_not_survived=df[df["survived"] ==0]
plt.scatter(df_survived["age"], df_survived["fare"], color="green", label="Survived")
plt.scatter(df_not_survived["age"], df_not_survived["fare"], color="red", label="Not Survived")
plt.xlabel("Age")
plt.ylabel("Fare")
plt.title("Relationship between Age and Fare")
plt.legend()
plt.show()
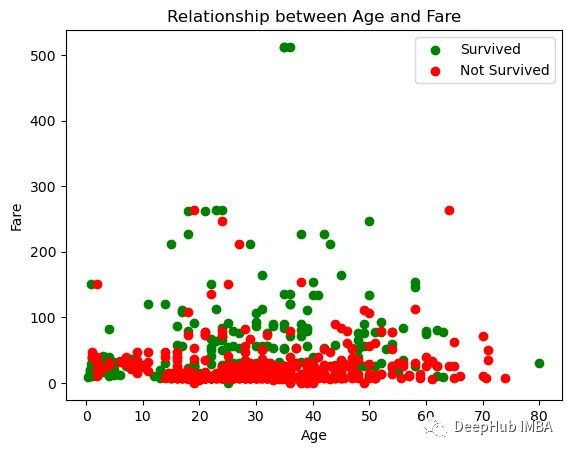
总结
作为最常用的数据分析库 Pandas 提供了一种创建图表的简单方法,这种方法可以帮我们快速对数据集进行简单的分析,快速的了解数据集的情况。如果需要对数据进行更高级的可视化,可以使用Seaborn、Plotly等更高级的库。
Panda的可视化文档在这里,有兴趣的可以详细查看:
https://pandas.pydata.org/docs/user_guide/visualization.html
希望本文对你有所帮助。