2023知识追踪最新综述来自顶刊!!!——《Knowledge Tracing:A Survey》
2023知识追踪最新综述——《Knowledge Tracing:A Survey》,文章发表在ACM Computing Survey上
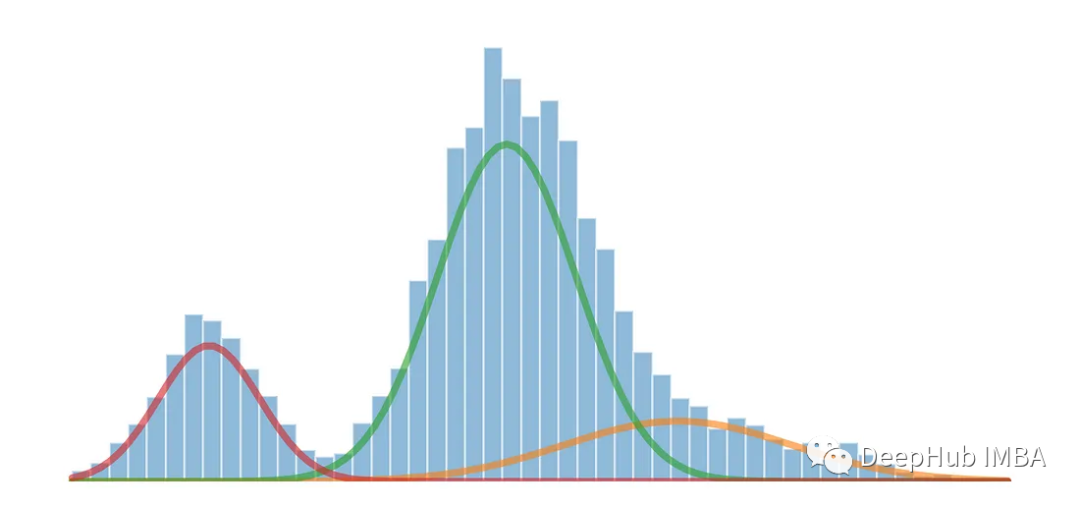
使用高斯混合模型拆分多模态分布
本文介绍如何使用高斯混合模型将一维多模态分布拆分为多个分布。
不同数据类型的相关性分析总结
在进行数据建模之前,我们一般会进行数据探索和描述性分析,发现数据规律及数据之间的相关性,本文主要从检验方法和可视化图形两个方面对不同数据类型的相关性分析方法进行总结,以加强对数据的了解和认识,为建模打下基础。
《数据挖掘》学堂在线【第一章:概述】习题答案参考与解析
《数据挖掘》慕课MOOC学堂在线【第一章:概述】课后作业习题答案参考与解析
数据分析及治理工程师
企业的信息化建设需要数据,那么数据是很重要的,数据分析的目的在于为业务服务,而为了更好的达成这一目的。对于元数据的采集和主数据的分析,以及数据标准的制定,和数据质量的保证是非常重要的。
Python中进行特征重要性分析的9个常用方法
特征重要性分析用于了解每个特征(变量或输入)对于做出预测的有用性或价值。目标是确定对模型输出影响最大的最重要的特征,它是机器学习中经常使用的一种方法。
spss时间序列预测
确定后,可能输出的没有预测数据,也可能输出差异大的预测数据, 需注意,将方法这里多尝试几次,做切换,从专家切到ARIMA,从ARIMA切到专家,调整季节值等,多调试几次,就能输出预测数据。保存:这里需注意变量名前缀,预测需以字母开头。分析-时间序列预测-创建传统模型;方法:ARIMA,条件:000。
pandas分组与聚合groupby()函数详解
groupby分组与聚合、分层索引、设置是否包含NaN、排除组键,星巴克零售店铺数据下载,星巴克零售店铺directory.csv数据获取,groupby用法详解,pandas分组与聚合,groupby如何使用
7.Python数据分析项目之银行客户流失分析
银行客户流失分析

Pandas DataFrame 数据存储格式比较
Pandas 支持多种存储格式,在本文中将对不同类型存储格式下的Pandas Dataframe的读取速度、写入速度和大小的进行测试对比。
多模态推荐系统综述
多模态推荐综述

15个基本且常用Pandas代码片段
以上这15个Pandas代码片段是我们日常最常用的数据操作和分析操作。熟练的掌握它,并将它们合并到工作流程中,可以提高处理和探索数据集的效率和效果。
常用的数据可视化工具有哪些?要操作简单的
提供含柱形图、仪表盘、树图等在内的数十种数据可视化图表,支持自定义制作数据可视化图表,从报表背景、标题小图标、图表颜色、字体、交互效果等都可自定义。注册登录后,即可根据以点击、拖拉的方式来实现数据可视化分析,SpeedBI数据分析云将高效响应、智能分析数据、可视化呈现数据分析结果。SpeedBI数据
一文了解scATAC-seq分析的一些必知概念
本文是作者在进行scATAC-seq时进行的一些基础知识铺垫
python人工智能技术
人工智能(AI)已成为当今世界的热门话题,它的应用范围越来越广泛。其中,Python成为AI开发中最受欢迎的编程语言之一。Python提供了许多功能强大的库和框架,大大简化了开发人员的工作。在本文中,我们将介绍Python在人工智能领域中的三个主要应用。
2023华中杯C题全保姆教程及代码 空气质量预测
构建 AQI多步预测模型,使用均方根误差(RMSE) 对建模效果进行评估,并对测试集及其预测结果进行可视化。
JAVA整合Milvus矢量数据库及数据
Milvus下载安装步骤及可视化工具、java整合Milvus进行数据操作,MilvusServiceClient
【通信原理】通信系统概念、组成、分类、度量的分析与研究
在当今信息高速发展的信息化社会,信息和通信已经成为现代社会的关键存在,通信技术对人们的生活方式和社会发展产生了重大影响。本文将从通信系统概念、组成、分类、度量几个方面来展开学习。本文将从通信系统概念、组成、分类、度量几个方面来介绍了一下通信系统的基本知识,对通信系统有了一个的了解,知道如何去度量详细
AI自动生成领域大牛?巧用文心千帆快速创建垂直领域专家
生成式AI一直是我所关注的技术,尤其现在集成多态大模型的基础之上,能否实际落地运用于各式各样的场景领域一直都是现今热点讨论的技术话题。对于如今比较成熟的生成式AI,如ChatGPT,ChatGLM和文心一言,都可以通过自然语言交互的形式,根据用户的指令,完成问答、文本创作、代码查错等任务。但是我们普
【强化学习】——Q-learning算法为例入门Pytorch强化学习
强化学习(Reinforcement Learning,RL)是一种机器学习方法,其目标是通过智能体(Agent)与环境的交互学习最优行为策略,以使得智能体能够在给定环境中获得最大的累积奖励。



