
广义优势估计(GAE):端策略优化PPO中偏差与方差平衡的关键技术
GAE的理论基础建立在资格迹(eligibility traces)和时序差分λ(TD-λ)之上,是近端策略优化(PPO)算法的重要基础理论
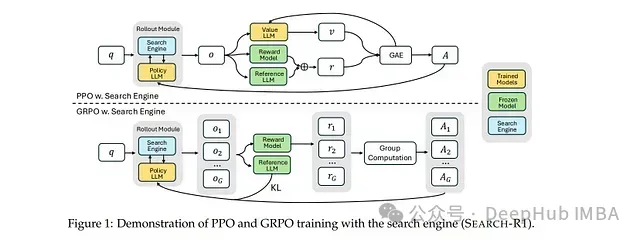
SEARCH-R1: 基于强化学习的大型语言模型多轮搜索与推理框架
该模型的核心创新在于**完全依靠强化学习机制(无需人工标注的交互轨迹)**来学习最优的搜索查询策略及基于检索知识的推理方法,从而显著提升问答任务的性能表现。
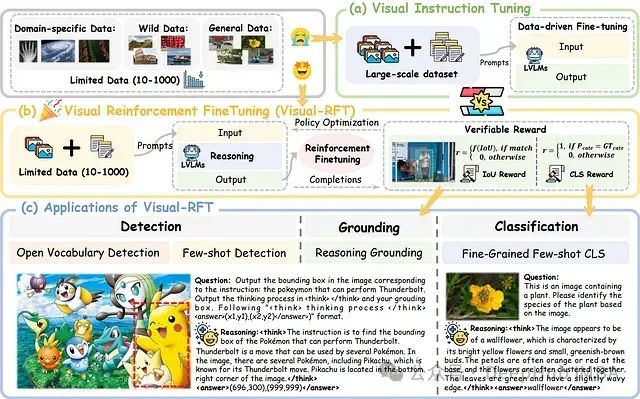
Visual-RFT:基于强化学习的视觉语言模型微调技术研究
Visual-RFT 的核心理念在于促进模型通过渐进式推理进行学习,而非简单地记忆标准答案。该方法鼓励模型生成多样化的响应并进行自主推理,随后基于答案正确性的验证信号调整学习方向。
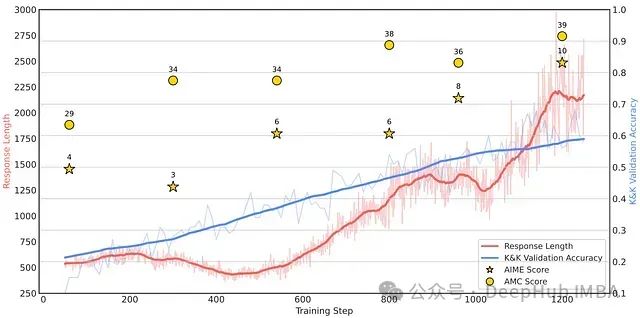
Logic-RL: 小模型也能强推理,通过基于规则的强化学习提升大语言模型结构化推理能力
这篇论文探讨了基于规则的强化学习(RL)如何解锁LLM中的高级推理能力。通过在受控的逻辑谜题上进行训练并强制执行结构化的思考过程,即使是相对较小的模型也能开发出可转移的问题解决策略。
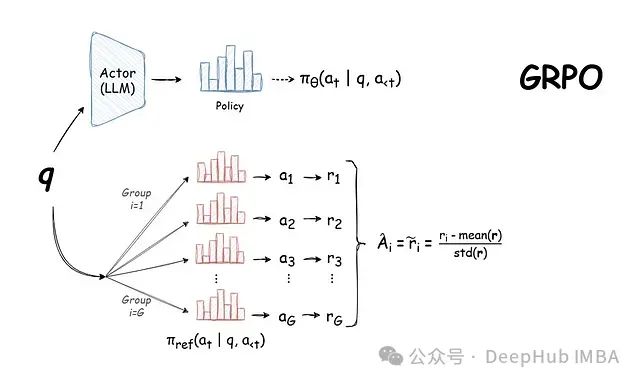
DeepSeek 背后的技术:GRPO,基于群组采样的高效大语言模型强化学习训练方法详解
本文将深入分析 GRPO 的工作机制及其在语言模型训练领域的重要技术突破,并探讨其在实际应用中的优势与局限性。
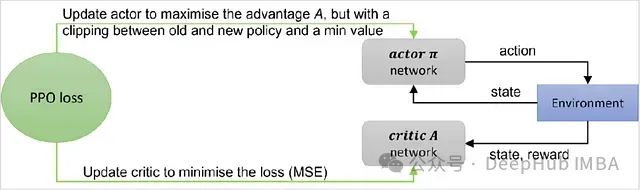
近端策略优化(PPO)算法的理论基础与PyTorch代码详解
近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度强化学习领域获得了广泛应用。特别是在大语言模型(LLM)的人类反馈强化学习(RLHF)过程中,PPO扮演着核心角色。本文将深入探讨PPO的基本原理和实现细节。
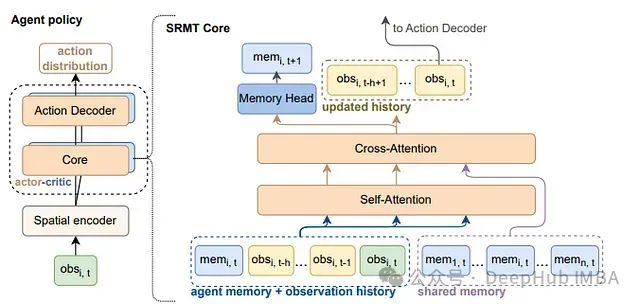
SRMT:一种融合共享记忆与稀疏注意力的多智能体强化学习框架
本研究将系统阐述**SRMT的技术架构、核心功能、应用场景及实验数据**,深入分析其在**多智能体强化学习(MARL)**领域的技术优势。
深度强化学习实战:训练DQN模型玩超级马里奥兄弟
本文将探讨深度学习在游戏领域的一个具体应用:构建一个能够自主学习并完成**超级马里奥兄弟**的游戏的智能系统。
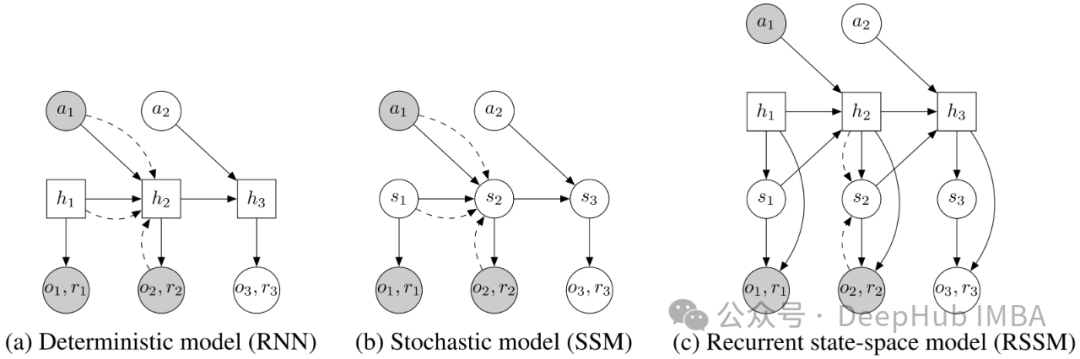
面向强化学习的状态空间建模:RSSM的介绍和PyTorch实现
循环状态空间模型(Recurrent State Space Models, RSSM)最初由 Danijar Hafer 等人在论文《Learning Latent Dynamics for Planning from Pixels》中提出。
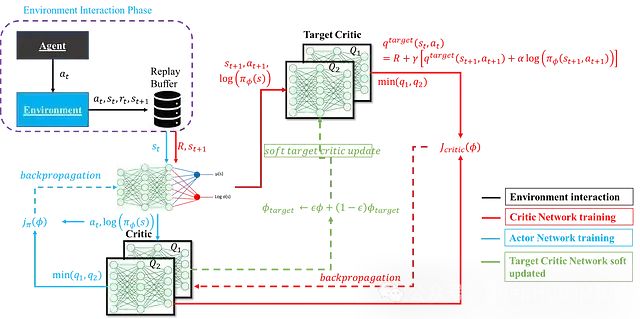
深度强化学习中SAC算法:数学原理、网络架构及其PyTorch实现
软演员-评论家算法(Soft Actor-Critic, SAC)因其在样本效率、探索效果和训练稳定性等方面的优异表现而备受关注。
【SARL】单智能体强化学习(Single-Agent Reinforcement Learning)《纲要》
强化学习(Reinforcement Learning,简称 RL)是一种让机器“通过尝试和错误学习”的方法。它模拟了人类和动物通过经验积累来学会做决策的过程,目的是让机器或智能体能够在复杂的环境中选择最优的行为,从而获得最大的奖励。我们在这里介绍了单智能体强化学习的相关算法。
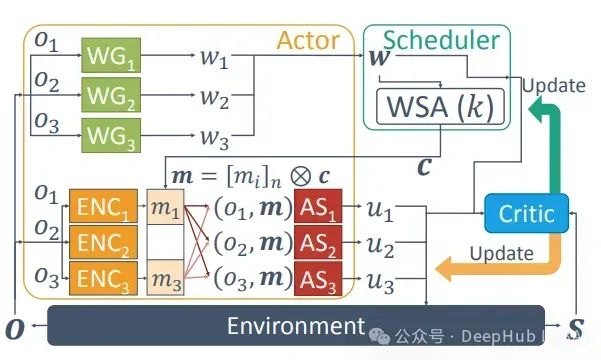
多代理强化学习综述:原理、算法与挑战
多代理强化学习是强化学习的一个子领域,专注于研究在共享环境中共存的多个学习代理的行为。每个代理都受其个体奖励驱动,采取行动以推进自身利益
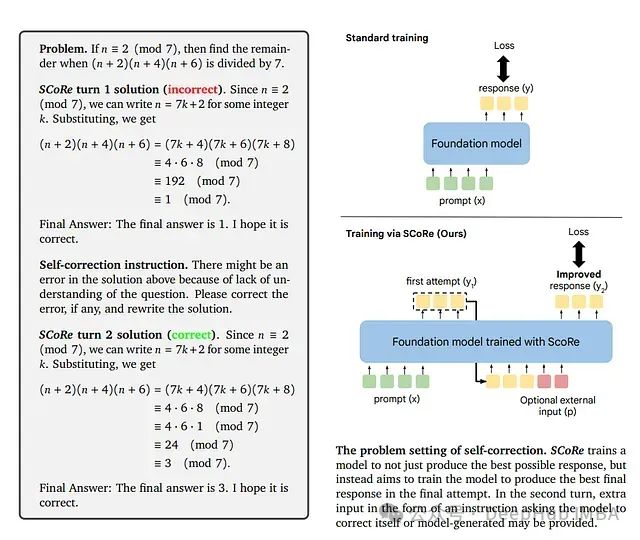
SCoRe: 通过强化学习教导大语言模型进行自我纠错
这是谷歌9月发布在arxiv上的论文,研究者们提出了一种新方法**自我纠错强化学习(SCoRe)**,旨在使大语言模型能够在没有任何外部反馈或评判的情况下"即时"纠正自己的错误。
【RL】强化学习入门:从基础到应用
【RL】强化学习入门:从基础到应用强化学习,本文介绍了强化学习的基础和python经典实现。(Reinforcement Learning, RL)是机器学习的一个重要分支,它使得智能体通过与环境的互动来学习如何选择最优动作,以最大化累积奖励。近年来,随着深度学习技术的发展,强化学习取得了显著的进展
吴恩达机器学习 第三课 week3 强化学习(月球着陆器自动着陆)
Coursera课程 吴恩达机器学习 第3课 :无监督学习、推荐算法和强化学习
AI:263-强化学习在自动驾驶领域的应用与前沿挑战
自动驾驶汽车是当前人工智能和机器学习的热门研究方向,而强化学习(Reinforcement Learning,RL)因其在复杂动态环境中的决策能力,成为推动自动驾驶技术的重要工具。本文将探讨强化学习在自动驾驶中的应用、面临的挑战,并提供一个简单的代码实例以展示如何在自动驾驶中应用强化学习。
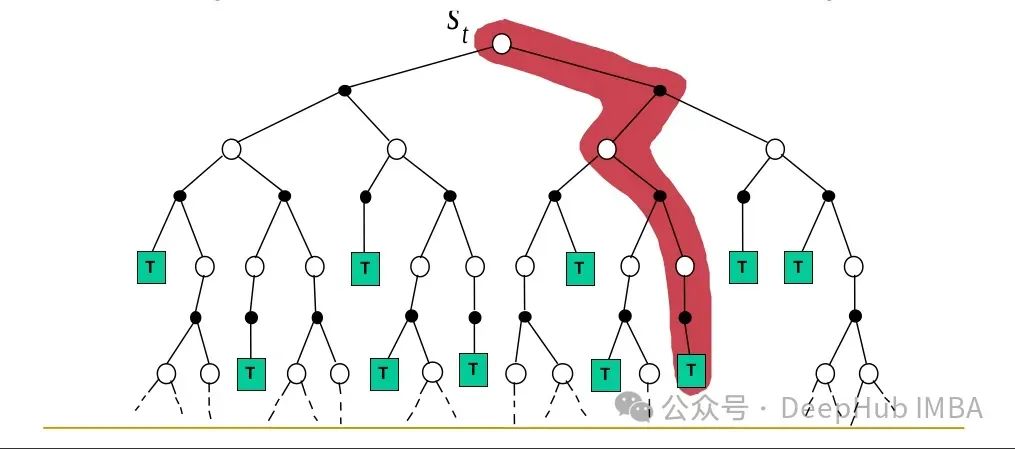
Monte Carlo方法解决强化学习问题
本文继续深入探讨蒙特卡罗 (MC)方法。这些方法的特点是能够仅从经验中学习,不需要任何环境模型,这与动态规划(DP)方法形成对比。
强化学习—多智能体
多智能体强化学习是强化学习中的一个重要分支,涉及多个智能体在动态和交互的环境中学习和决策。它面临着挑战,如非稳定性、维度灾难以及智能体之间的协作与竞争。然而,随着算法的不断进步,MARL 在多个复杂应用领域中显示出巨大的潜力和前景。如果有更多的具体问题或需要深入讨论某个方面,欢迎继续提问!在一个包含
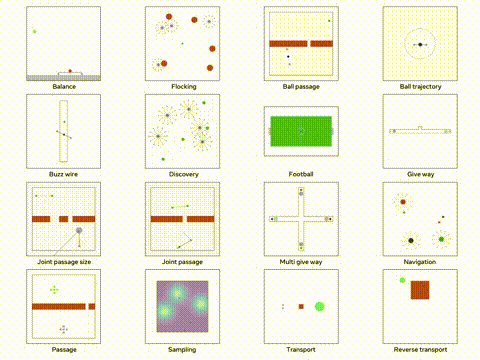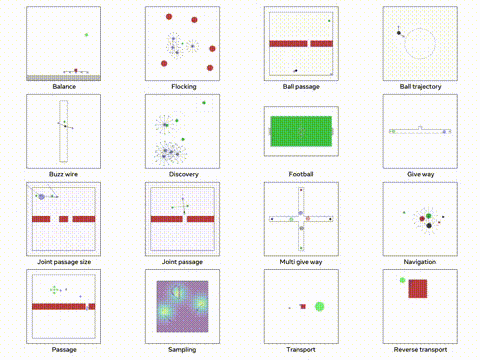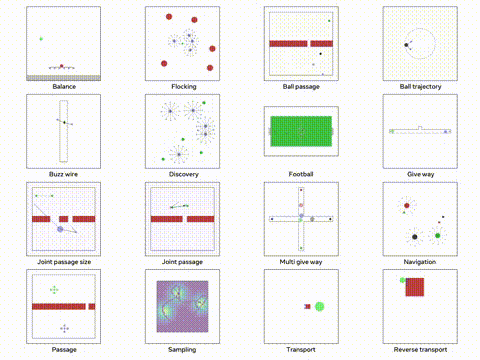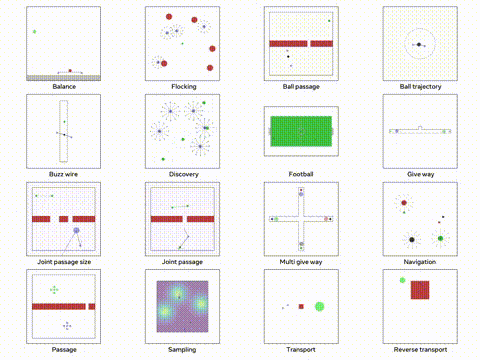
使用 Python TorchRL 进行多代理强化学习
本文将深入探讨如何使用 TorchRL 解决 MARL 问题,重点关注多代理环境中的近端策略优化(PPO)。
【强化学习】Q-learning训练AI走迷宫
Q-learning是一种基于强化学习的算法,用于解决Markov决策过程(MDP)中的问题。这类问题我们理解为一种可以用有限状态机表示的问题。它具有一些离散的状态state、每一个state可以通过动作action转移到另外一个state。每次采取action,这个action都会带有一些奖励re



