
处理单一任务是强化学习的基础,它的目标是在不确定的环境中采取最佳行动,产生相对于任务的最大长期回报。但是在多代理强化学习中,因为存在多个代理,所以代理之间的关系可以是合作的,也可以是对抗,或者两者的混合。多代理的强化学习引入了更多的复杂性,每个代理的状态不仅包括对自身的观察,还包括对其他代理位置及其活动的观察。
在训练对抗的多代理模型时,目标一般是让所有竞争的代理通过达到一种称为纳什均衡的博弈状态来发现对抗对手的最佳策略。所以对抗性多代理强化学习可以适应和建模现实世界的问题,如公司间或国家间的经济竞争。
而对于协作式多代理学习,其目标是让多个代理朝着某个目标进行协作。这可能涉及到代理之间的“沟通”,例如学习如何在实现长期目标的协作中专注于完成特定的子任务。协作式多代理强化学习可以应用于现实环境,例如在仓库操作中操作一队机器人,甚至是一辆自动驾驶出租车。
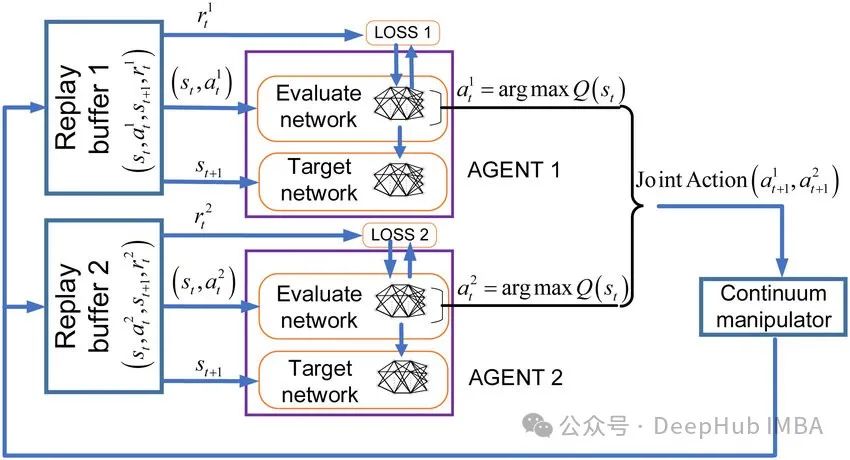
在本文中我们将只关注合作多代理学习的问题,不仅因为它在我们日常生活中更常见,而对于我们学习来说也相对的简单一些。
Multi-Agent Deep Q-Networks (MADQN)
Deep Q-Networks (DQN)时针对单个代理的,而我们可以通过一些细微的调整来制定多代理深度Q-Networks (MADQN)。
MADQN可以有3种不同的表述,即独立MADQN (iMADQN)、集中训练分散执行MADQN (CTDE MADQN)和集中训练和集中执行DQN (CTCE MADQN):
iMADQN
这是应用于多代理场景的普通DQN实现。每个代理都有其独特的在线网络和目标网络对。每个代理的状态应该包括对其其他代理的观察。训练和推理都是分散的,也就是说我们把每一个代理想象成为独立个体,他会根据环境状态和其他代理的状态来进行决策。
CTDE MADQN
集中训练和分散执行MADQN采用将专门的代理状态输入到一对在线网络和目标网络中并进行训练。通过将索引元素连接到默认状态向量来区分每个代理的状态。训练过程是集中的,但是每个代理状态的动作推理是分开进行的。可以将其理解为只训练一个代理,在推理时我们将这个代理进行克隆(通俗的解释)。
CTCE MADQN
集中训练和集中执行DQN采用多平台方法进行多代理学习。它利用一个“中央代理”,接收所有代理的连接状态向量,并同时输出各个代理的每个动作。CTCE DQN可以应用于多代理设置,它将其转换为单代理问题。训练和推理都是集中的。
下面我们将逐个解释和实现每个算法
Python代码实现
我们选择自ma-gym的“Switch4”,4种不同颜色的代理在网格的4个不同角落开始,有一条狭窄的小巷将两对代理隔离在环境的每一侧。而游戏的目标是让每个代理穿过小巷进入到另一边相同颜色的盒子中。
代理必须学会如何进行协调,避免在狭窄的小巷里互相阻塞,这样才能以最少的步数进入各自的箱子。我们设定如果一个代理到达相应的盒子将获得+5奖励。每个操作步骤的代价为-0.1。动作空间是离散的,有以下几个操作“上”、“下”、“左”、“右”和“什么都不做”的索引。
当所有彩色代理到达各自的箱子或超过规定的最大时间步数时,一次的训练就结束了。下面的GIF展示了4个代理在2次训练中的网格中执行随机动作。

对于这个简单的游戏我们来说明一下最佳的解,因为每个操作步都时-0.1所以我们应该保证在不影响中间移动的代理的情况下来操作其他颜色的代理,比如说一边的两个代理同时穿过中间的过道。如果单代理操作,得到的最大奖励为14,而如果同时2个代理穿过过道的话能够得到大概16左右的奖励,我们就以这两个数值作为参考来试下我们的模型。
1、iMADQN
# The DQN network architecture
classDQN(nn.Module):
def__init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.output_dim=output_dim
self.fc=nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, output_dim)
)
defforward(self, x):
returnself.fc(x)
# The Replay Buffer
classReplayBuffer:
def__init__(self, buffer_size):
self.buffer=deque(maxlen=buffer_size)
self.rewards=deque(maxlen=buffer_size)
defpush(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
self.rewards.append(float(reward))
defsample(self, batch_size):
states, actions, rewards, next_states, dones=zip(*random.sample(self.buffer, batch_size))
returnnp.array(states), np.array(actions), np.array(rewards), np.array(next_states), np.array(dones)
def__len__(self):
returnlen(self.buffer)
classDQNAgent:
def__init__(self, input_dim, output_dim, gamma=0.99, lr=1e-3, tau=0.002):
self.policy_network=DQN(input_dim, output_dim).float()
self.target_network=DQN(input_dim, output_dim).float()
self.target_network.load_state_dict(self.policy_network.state_dict())
self.optimizer=optim.Adam(self.policy_network.parameters(), lr=lr)
self.gamma=gamma
self.tau=tau
self.replay_buffer=ReplayBuffer(125000)
defact(self, state, epsilon=0.1):
ifnp.random.rand() <epsilon:
returnnp.random.randint(env.action_space[0].n)
state=torch.FloatTensor(state).unsqueeze(0)
q_values=self.policy_network(state)
returnq_values.argmax().item()
defsoft_update(self):
fortarget_param, policy_paraminzip(self.target_network.parameters(), self.policy_network.parameters()):
target_param.data.copy_(self.tau*policy_param.data+ (1-self.tau) *target_param.data)
deftrain(self, batch_size=128):
state, action, reward, next_state, done=self.replay_buffer.sample(batch_size)
state=torch.FloatTensor(state)
action=torch.LongTensor(action)
reward=torch.FloatTensor(reward)
next_state=torch.FloatTensor(next_state)
done=torch.FloatTensor(done)
q_values=self.policy_network(state)
next_q_values=self.target_network(next_state)
q_value=q_values.gather(1, action.unsqueeze(1)).squeeze(1)
next_q_value=next_q_values.max(1)[0]
q_target=reward+self.gamma*next_q_value* (1-done)
loss=nn.functional.mse_loss(q_value, q_target.detach())
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.soft_update()
下面是训练的代码,我们设置了4个代理,代表4种颜色,每个代理都是一个独立的网络
# Initialize the gym environment
env=gym.make('ma_gym:Switch4-v0', max_steps=250)
num_agents=env.n_agents
input_dim=env.observation_space[0].shape[0]
output_dim=env.action_space[0].n
# Initialize the agents
agent0=DQNAgent(input_dim*num_agents, output_dim)
agent1=DQNAgent(input_dim*num_agents, output_dim)
agent2=DQNAgent(input_dim*num_agents, output_dim)
agent3=DQNAgent(input_dim*num_agents, output_dim)
num_episodes=3000
batch_size=128
epsilon_start=1.0
epsilon_end=0.01
epsilon_decay=0.99
epsilon=epsilon_start
moving_rewards=deque(maxlen=10)
forepisodeinrange(num_episodes):
done_n= [Falsefor_inrange(env.n_agents)]
state_n=env.reset()
episode_reward=0
whilenotall(done_n):
actions_n= []
full_state=np.concatenate(state_n)
foragentin [agent0, agent1, agent2, agent3]:
action=agent.act(full_state, epsilon)
actions_n.append(action)
next_state_n, reward_n, done_n, _=env.step(actions_n)
full_next_state=np.concatenate(next_state_n)
# Store the experience in replay buffer
agent0.replay_buffer.push(full_state, actions_n[0], sum(reward_n), full_next_state, all(done_n))
agent1.replay_buffer.push(full_state, actions_n[1], sum(reward_n), full_next_state, all(done_n))
agent2.replay_buffer.push(full_state, actions_n[2], sum(reward_n), full_next_state, all(done_n))
agent3.replay_buffer.push(full_state, actions_n[3], sum(reward_n), full_next_state, all(done_n))
state_n=next_state_n
episode_reward+=sum(reward_n)
# Update the networks
iflen(agent0.replay_buffer) >batch_size:
agent0.train(batch_size)
iflen(agent1.replay_buffer) >batch_size:
agent1.train(batch_size)
iflen(agent2.replay_buffer) >batch_size:
agent2.train(batch_size)
iflen(agent3.replay_buffer) >batch_size:
agent3.train(batch_size)
epsilon=max(epsilon_end, epsilon*epsilon_decay)
moving_rewards.append(episode_reward)
avg_reward=sum(moving_rewards) /len(moving_rewards)
if (episode+1) %10==0:
print(f"Episode {episode+1}, Average Reward over last 10 episodes: {avg_reward:.2f}")
ifavg_reward>=14andepisode_reward>=16:
print(f"Training completed successfully at Episode {episode+1}, with average reward over 10 episodes: {avg_reward:.2f}")
break
运行上面的训练代码,运行了整整3000次后。平均奖励都超过了14。
在上面的实现中,我们还在每个时间步将每个代理的组合奖励保存到重播的缓冲区,这样可以改善代理之间的通信,在训练期间证明了这是更有效和稳定的。
如果代理之间的通信是离线的(特别是在现实世界中)我们应该根据每个代理自己的状态-动作-状态转换来给予奖励。
训练完成后,我们可以通过设置epsilon为零来评估模型的性能,如下所示:
env = gym.make('ma_gym:Switch4-v0', max_steps=100)
num_episodes = 20
delay = 0.1
for _ in range(num_episodes):
done_n = [False for _ in range(env.n_agents)]
ep_reward = 0
state_n = env.reset()
while not all(done_n):
env.render()
actions_n = []
all_states = np.concatenate(state_n)
time.sleep(delay)
for agent in [agent0, agent1,agent2,agent3]:
action = agent.act(all_states, epsilon=0)
actions_n.append(action)
state_n, reward_n, done_n, info = env.step(actions_n)
ep_reward += sum(reward_n)
env.close()

我们可以以满意的结果解决环境,但在评估时奖励=14.1,这说明解决方案可能不是最有效的。每个代理交替穿过小巷而其他三个代理几乎静止不动。
CTDE MADQN
CTDE MADQN的Python类和函数的设置与iMADQN相同。不同之处在于如下所示的训练代码。
# Initialize the gym environment
env=gym.make('ma_gym:Switch4-v0', max_steps=250)
num_agents=env.n_agents
input_dim=env.observation_space[0].shape[0]
output_dim=env.action_space[0].n
# Initialize the agents
agent=DQNAgent(input_dim*4+1, output_dim)
num_episodes=3000
batch_size=128
epsilon_start=1.0
epsilon_end=0.1
epsilon_decay=0.99
epsilon=epsilon_start
moving_rewards=deque(maxlen=10)
forepisodeinrange(num_episodes):
done_n= [Falsefor_inrange(env.n_agents)]
state_n=env.reset()
episode_reward=0
whilenotall(done_n):
full_state_agent_0=np.concatenate([np.concatenate(state_n),np.array([0])])
full_state_agent_1=np.concatenate([np.concatenate(state_n),np.array([1])])
full_state_agent_2=np.concatenate([np.concatenate(state_n),np.array([2])])
full_state_agent_3=np.concatenate([np.concatenate(state_n),np.array([3])])
action_agent_0=agent.act(full_state_agent_0, epsilon)
action_agent_1=agent.act(full_state_agent_1, epsilon)
action_agent_2=agent.act(full_state_agent_2, epsilon)
action_agent_3=agent.act(full_state_agent_3, epsilon)
all_actions= [action_agent_0,action_agent_1,action_agent_2,action_agent_3]
next_state_n, reward_n, done_n, _=env.step(all_actions)
full_next_state_agent_0=np.concatenate([np.concatenate(next_state_n),np.array([0])])
full_next_state_agent_1=np.concatenate([np.concatenate(next_state_n),np.array([1])])
full_next_state_agent_2=np.concatenate([np.concatenate(next_state_n),np.array([2])])
full_next_state_agent_3=np.concatenate([np.concatenate(next_state_n),np.array([3])])
full_rewards=sum(reward_n)
# Store the experience in replay buffer
agent.replay_buffer.push(full_state_agent_0, action_agent_0, reward_n[0], full_next_state_agent_0, all(done_n))
agent.replay_buffer.push(full_state_agent_1, action_agent_1, reward_n[1], full_next_state_agent_1, all(done_n))
agent.replay_buffer.push(full_state_agent_2, action_agent_2, reward_n[2], full_next_state_agent_2, all(done_n))
agent.replay_buffer.push(full_state_agent_3, action_agent_3, reward_n[3], full_next_state_agent_3, all(done_n))
state_n=next_state_n
episode_reward+=sum(reward_n)
# Update the networks
iflen(agent.replay_buffer) >batch_size:
agent.train(batch_size)
epsilon=max(epsilon_end, epsilon*epsilon_decay)
moving_rewards.append(episode_reward)
avg_reward=sum(moving_rewards) /len(moving_rewards)
if (episode+1) %10==0:
print(f"Episode {episode+1}, Average Reward over last 10 episodes: {avg_reward:.2f}")
ifavg_reward>=14andepisode_reward>=16:
print(f"Training completed successfully at Episode {episode+1}, with average reward over 10 episodes: {avg_reward:.2f}")
break
每个代理在观察所有代理的连接状态的同时,其状态还包含其唯一的索引,这样就可以区分不同颜色的代理。然后将所有代理的状态、动作、奖励和下一个状态(S,A,R,S’)元组推送到单个重播缓冲区进行集中训练。由于维度高度相似的状态被推到缓冲区中,每个代理的元组可以通过将单个奖励而不是组合奖励推到缓冲区中来更好地区分自己。
这种实现更有效,因为在训练期间,模型同步地从所有代理的经验中学习,而在每次迭代中只执行一次训练,而不是为不同的代理训练不同的dqn。
上述训练代码在1030次时达到了停止条件(奖励16),在评估中得到了最大奖励16.1。可以看每一对代理从小巷的一边一起穿过另一边,从而减少了实现目标所需的时间。
env = gym.make('ma_gym:Switch4-v0', max_steps=100)
num_episodes = 20
delay = 0.1
for _ in range(num_episodes):
done_n = [False for _ in range(env.n_agents)]
ep_reward = 0
state_n = env.reset()
while not all(done_n):
env.render()
time.sleep(delay)
full_state_agent_0 = np.concatenate([np.concatenate(state_n),np.array([0])])
full_state_agent_1 = np.concatenate([np.concatenate(state_n),np.array([1])])
full_state_agent_2 = np.concatenate([np.concatenate(state_n),np.array([2])])
full_state_agent_3 = np.concatenate([np.concatenate(state_n),np.array([3])])
action_agent_0 = agent.act(full_state_agent_0, epsilon=0)
action_agent_1 = agent.act(full_state_agent_1, epsilon=0)
action_agent_2 = agent.act(full_state_agent_2, epsilon=0)
action_agent_3 = agent.act(full_state_agent_3, epsilon=0)
all_actions = [action_agent_0,action_agent_1,action_agent_2,action_agent_3]
state_n, reward_n, done_n, _ = env.step(all_actions)
ep_reward += sum(reward_n)
env.close()

我们在这个例子中看到了2个代理的协作,因为它们能够同时穿过过道,这样节省了操作步数
CTCE MADQN
CTDE MADQN已经获得了“Switch4”环境的最佳策略。我们再看看集中训练集中执行的MADQN。在CTCE MADQN中,训练和动作执行都是由单个中央代理完成的。所有主体的行为都是同时预测的。我们将调整Python类/函数和训练代码如下:
# The DQN network architecture
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, output_dim)
)
def forward(self, x):
return self.fc(x)
# The Replay Buffer
class ReplayBuffer:
def __init__(self, buffer_size):
self.buffer = deque(maxlen=buffer_size)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
states, actions, rewards, next_states, dones = zip(*random.sample(self.buffer, batch_size))
return np.array(states), np.array(actions), np.array(rewards), np.array(next_states), np.array(dones)
def __len__(self):
return len(self.buffer)
class DQNAgent:
def __init__(self, input_dim, output_dim, gamma=0.99, lr=1e-3, tau=0.002):
self.input_dim = input_dim
self.output_dim = output_dim
self.policy_network = DQN(self.input_dim, self.output_dim).float()
self.target_network = DQN(self.input_dim, self.output_dim).float()
self.target_network.load_state_dict(self.policy_network.state_dict())
self.optimizer = optim.Adam(self.policy_network.parameters(), lr=lr)
self.gamma = gamma
self.tau = tau
self.replay_buffer = ReplayBuffer(125000)
def act(self, full_state, epsilon=0.1):
if np.random.rand() < epsilon:
return [np.random.randint(env.action_space[0].n) for _ in range(4)]
full_state = torch.FloatTensor(full_state).unsqueeze(0)
q_values = self.policy_network(full_state)
q_values = q_values.view(4, -1)
return q_values.argmax(dim=1).tolist()
def soft_update(self):
for target_param, policy_param in zip(self.target_network.parameters(), self.policy_network.parameters()):
target_param.data.copy_(self.tau * policy_param.data + (1 - self.tau) * target_param.data)
def train(self, batch_size=128):
state, action, reward, next_state, done = self.replay_buffer.sample(batch_size)
state = torch.FloatTensor(state)
next_state = torch.FloatTensor(next_state)
reward = torch.FloatTensor(reward).unsqueeze(-1)
done = torch.FloatTensor(done).unsqueeze(-1)
action = torch.LongTensor(action)
q_values = self.policy_network(state).view(batch_size, 4, -1)
next_q_values = self.target_network(next_state).view(batch_size, 4, -1)
q_value = q_values.gather(-1, action.view(batch_size, 4, 1)).squeeze(-1)
next_q_value, _ = next_q_values.max(-1)
q_target = reward + (self.gamma * next_q_value * (1 - done))
loss = nn.functional.mse_loss(q_value, q_target.detach())
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.soft_update()
训练代码
# Initialize the gym environment
env = gym.make('ma_gym:Switch4-v0', max_steps=250)
num_agents = env.n_agents
input_dim = env.observation_space[0].shape[0]
output_dim = env.action_space[0].n
# Initialize the agents
central_agent = DQNAgent(input_dim*4, output_dim*4)
num_episodes = 3000
batch_size = 64
epsilon_start = 1.0
epsilon_end = 0.01
epsilon_decay = 0.99
epsilon = epsilon_start
moving_rewards = deque(maxlen=10)
for episode in range(num_episodes):
done_n = [False for _ in range(env.n_agents)]
state_n = env.reset()
episode_reward = 0
while not all(done_n):
full_state = np.concatenate(state_n)
actions_n = central_agent.act(full_state, epsilon)
next_state_n, reward_n, done_n, _ = env.step(actions_n)
full_next_state = np.concatenate(next_state_n)
full_rewards = sum(reward_n)
# Store the experience in replay buffer
central_agent.replay_buffer.push(full_state, actions_n, full_rewards, full_next_state, all(done_n))
state_n = next_state_n
episode_reward += sum(reward_n)
# Update the networks
if len(central_agent.replay_buffer) > batch_size:
central_agent.train(batch_size)
epsilon = max(epsilon_end, epsilon * epsilon_decay)
moving_rewards.append(episode_reward)
avg_reward = sum(moving_rewards) / len(moving_rewards)
if (episode + 1) % 10 == 0:
print(f"Episode {episode+1}, Average Reward over last 10 episodes: {avg_reward:.2f}")
if avg_reward >= 14 and episode_reward>=16:
print(f"Training completed successfully at Episode {episode+1}, with average reward over 10 episodes: {avg_reward:.2f}")
break
CTCE MADQN没有达到停止条件,总共运行了3000次,有几次平均奖励超过14。
如下图所示,训练后的模型以次优解求解环境,奖励=14.6:
env=gym.make('ma_gym:Switch4-v0', max_steps=100)
num_episodes=20
delay=0.1
for_inrange(num_episodes):
done_n= [Falsefor_inrange(env.n_agents)]
ep_reward=0
state_n=env.reset()
whilenotall(done_n):
env.render()
time.sleep(delay)
full_state=np.concatenate(state_n)
actions_n=central_agent.act(full_state, epsilon=0)
state_n, reward_n, done_n, info=env.step(actions_n)
ep_reward+=sum(reward_n)
env.close()

总结
虽然MADQN的所有3种方法都是有效的模型,但它们在多代理合作方面的性能有所不同。
CTDE MADQN比其他2个MADQN模型显示出更好的结果,这可能是因为通过集中训练,模型从所有4个代理的经验中学习。对于iMADQN,虽然每个代理都知道另一个代理的活动,但每个代理在训练中可能没有利用合作知识。每个代理可能表现得更“自私”。
而CTCE MADQN方法,训练过程可能会受到阻碍,因为在每个时间步,只有一组状态、动作和奖励元组被推入回放缓冲区,而CTDE MADQN实现则有4组。并且CTCE MADQN输出4个动作,这可能会增加预测的误差范围。
这里只是介绍了一个简单环境下的多代理强化学习,为了解决更复杂的环境MADQN可能需要先进的强化学习技术,如Prioritized Experience Replay、学习率衰减和定制奖励等等。学习率衰减一般会对稳定训练过程非常有用,特别是在模型对权重变化高度敏感的后期,引入和调整某些奖励和惩罚会使模型更快地收敛。
作者:Tan Pengshi Alvin