使用深度强化学习预测股票:DQN 、Double DQN和Dueling Double DQN对比和代码示例
通过DRL,研究人员和投资者可以开发能够分析历史数据的模型,理解复杂的市场动态,并对股票购买、销售或持有做出明智的决策。

通过强化学习策略进行特征选择
在本文中,我们将介绍并实现一种新的通过强化学习策略的特征选择。
基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
基于人类反馈的强化学习(RLHF)实战
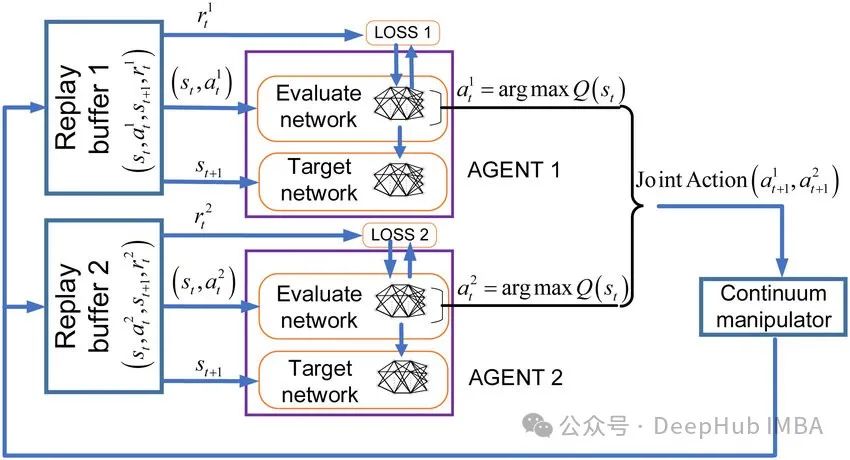
MADQN:多代理合作强化学习
在本文中我们将只关注合作多代理学习的问题,不仅因为它在我们日常生活中更常见,而对于我们学习来说也相对的简单一些。
【强化学习入门】二.强化学习的基本概念:状态、动作、智能体、策略、奖励、状态转移、轨迹、回报、价值函数
自动驾驶中,汽车就是智能体;机器人控制中,机器人就是智能体;超级玛丽游戏中,玛丽就是智能体。当智能体做出一个动作,状态会发生变化(从旧的状态变成新的状态)。我们就可以说状态发生的转移。的含义就是,根据观测到的状态,做出动作的方案,超级玛丽游戏中,观测到的这一帧画面就是一个。强化学习的目标就是尽可能的
强化学习稀疏奖励问题(sparse reward)及解决方法
通常在训练智能体时,我们希望每一步动作都有相应的奖励。但是某些情况下,智能体并不能立刻获得奖励,比如全局奖励的围棋,最终获胜会得到奖励,但是人们很难去设定中间每步的奖励,这会导致学习缓慢甚至无法进行学习的问题。稀疏奖励,奖励塑型,课程学习,好奇心模块,分层强化学习
一分钟秒懂人工智能对齐
事实上,人工智能对齐这一概念和ChatGPT这样的通用大模型的诞生密不可分。对于通用大模型而言,一个模型可以同时完成多种任务,而且不同的任务有着不同的期望:有的任务希望能够更有想象力,有的任务希望能够更尊重事实;有的任务希望能够理性客观,有的任务希望能有细腻丰富的情感。任务的多样性导致了需要对大模型
Python强化学习实战及其AI原理详解
1. 引言2. 时间旅行和平行宇宙3. 强化学习4. 策略梯度算法5. 代码案例6. 推荐阅读与粉丝福利
使用Panda-Gym的机器臂模拟进行Deep Q-learning强化学习
强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体因采取行动导致预期结果而获得奖励,因采取行动导致预期结果而受到惩罚。随着时间的推移,代理学会采取行动,使其预期回报最大化。
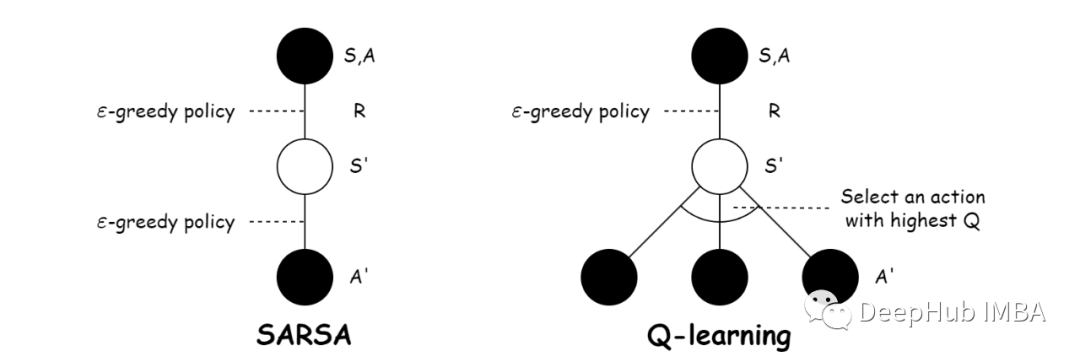
基于时态差分法的强化学习:Sarsa和Q-learning
时态差分法(Temporal Difference, TD)是一类在强化学习中广泛应用的算法,用于学习价值函数或策略。Sarsa和Q-learning都是基于时态差分法的重要算法,用于解决马尔可夫决策过程(Markov Decision Process, MDP)中的强化学习问题。
基于Gym Anytrading 的强化学习简单实例
Gym Anytrading是一个建立在OpenAI Gym之上的开源库,它提供了一系列金融交易环境。它允许我们模拟各种交易场景,并使用RL算法测试不同的交易策略。
通用人工智能之路:什么是强化学习?如何结合深度学习?
【专栏订阅必读】ChatGPT强大魔力的关键因素之一是应用了强化学习模型,本文系统梳理强化学习中环境、智能体、奖赏、动作、状态等关键概念,并给出深度强化学习框架。
【深度强化学习】(5) DDPG 模型解析,附Pytorch完整代码
深度确定性策略梯度算法 (Deterministic Policy Gradient,DDPG)。DDPG 算法使用演员-评论家(Actor-Critic)算法作为其基本框架,采用深度神经网络作为策略网络和动作值函数的近似,使用随机梯度法训练策略网络和价值网络模型中的参数。DDPG 算法架构中使用双
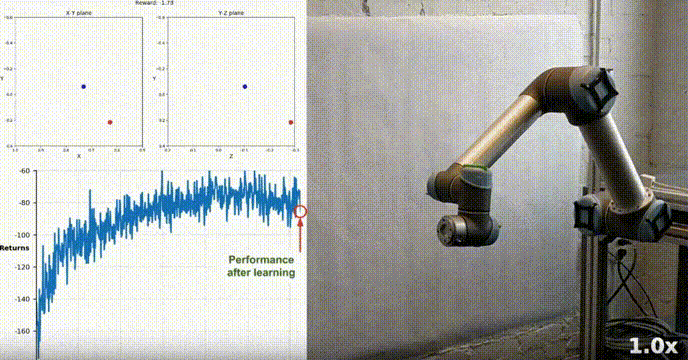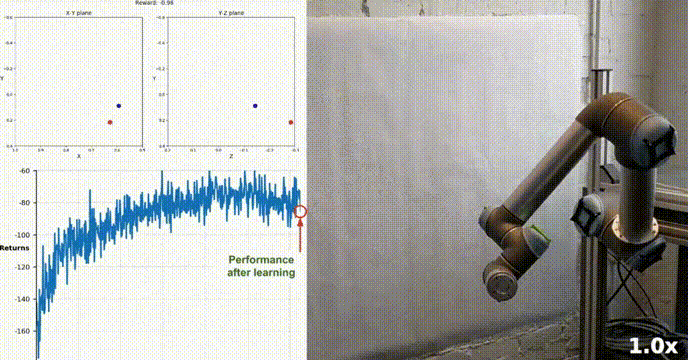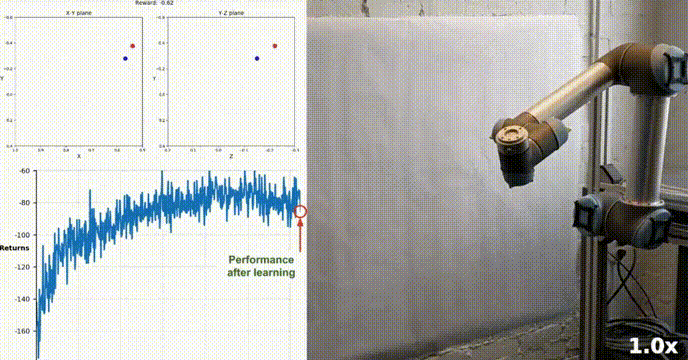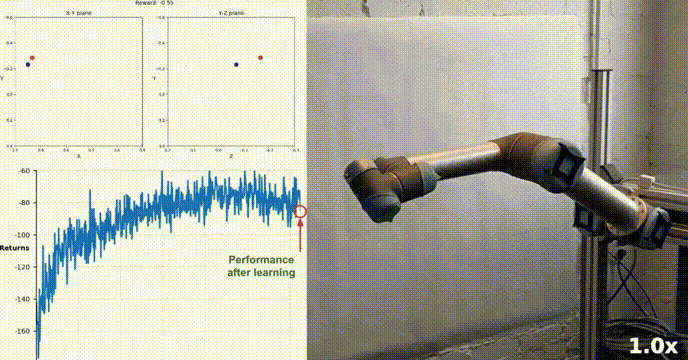
使用Actor-Critic的DDPG强化学习算法控制双关节机械臂
在本文中,我们将介绍在 Reacher 环境中训练智能代理控制双关节机械臂
Webots搭建强化学习二轮避障小车(看看吧 蛮详细的)
此文为使用webots搭建二轮机器人并进行避障设计的全过程,各部分足够详细,对于初学者能起到不少帮助。同时也包含强化学习DQN算法进行避障的尝试。有兴趣可以一看。
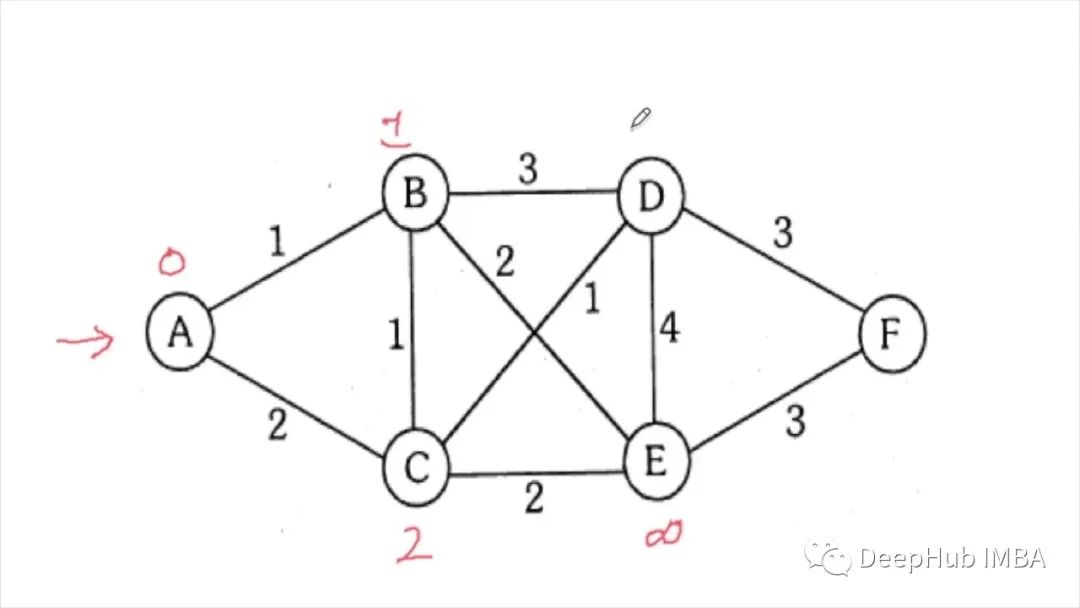
利用强化学习Q-Learning实现最短路径算法
本文中我们将尝试找出一种方法,在从目的地a移动到目的地B时尽可能减少遍历路径。我们使用自己的创建虚拟数据来提供演示,下面代码将创建虚拟的交通网格:
深度强化学习DRL训练指南和现存问题(D3QN(Dueling Double DQN))
深度强化学习DRL现存问题和训练指南(D3QN(Dueling Double DQN))
多智能体强化学习之MAPPO理论解读
多智能体强化学习之MAPPO算法MAPPO训练过程本文主要是结合文章Joint Optimization of Handover Control and Power Allocation Based on Multi-Agent Deep Reinforcement Learning对MAPPO算法
【深度强化学习】(4) Actor-Critic 模型解析,附Pytorch完整代码
行动者评论家方法是由行动者和评论家两个部分构成。行动者用于选择动作,评论家评论选择动作的好坏。Critic 是评判网络,当输入为环境状态时,它可以评估当前状态的价值,当输入为环境状态和采取的动作时,它可以评估当前状态下采取该动作的价值。Actor 为策略网络,以当前的状态作为输入,输出为动作的概率分
【深度强化学习】多智能体算法汇总
本文收纳了常见的多智能体强化学习方法,并简单介绍各个算法。



