
0. 简单总结
Q-learning?
- 最简单的强化学习算法!
- 不需要深度学习网络的算法!
- 带有概率性的穷举特性!(甚至还有一点点动态规划的感觉)
1. Q-learning介绍
Q-learning是一种基于强化学习的算法,用于解决Markov决策过程(MDP)中的问题。
这类问题我们理解为一种可以用有限状态机表示的问题。它具有一些离散的状态state、每一个state可以通过动作action转移到另外一个state。每次采取action,这个action都会带有一些奖励reward(也可以是负数,这样就表示惩罚了)。
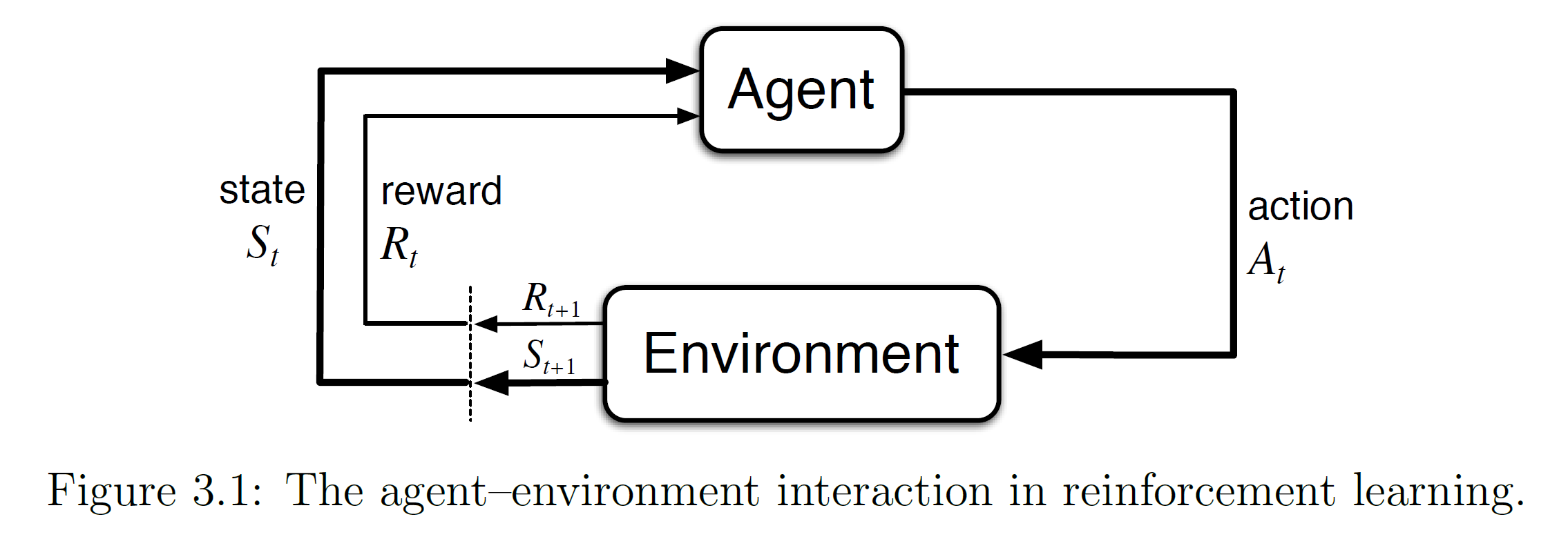
在Q-learning中,我们有一个智能体(Agent)和一个环境(Environment)。智能体可以在环境中执行动作,并从环境中获取奖励作为反馈。智能体的目标是通过与环境的交互来学习如何做出最优的动作,以最大化未来的累积奖励。
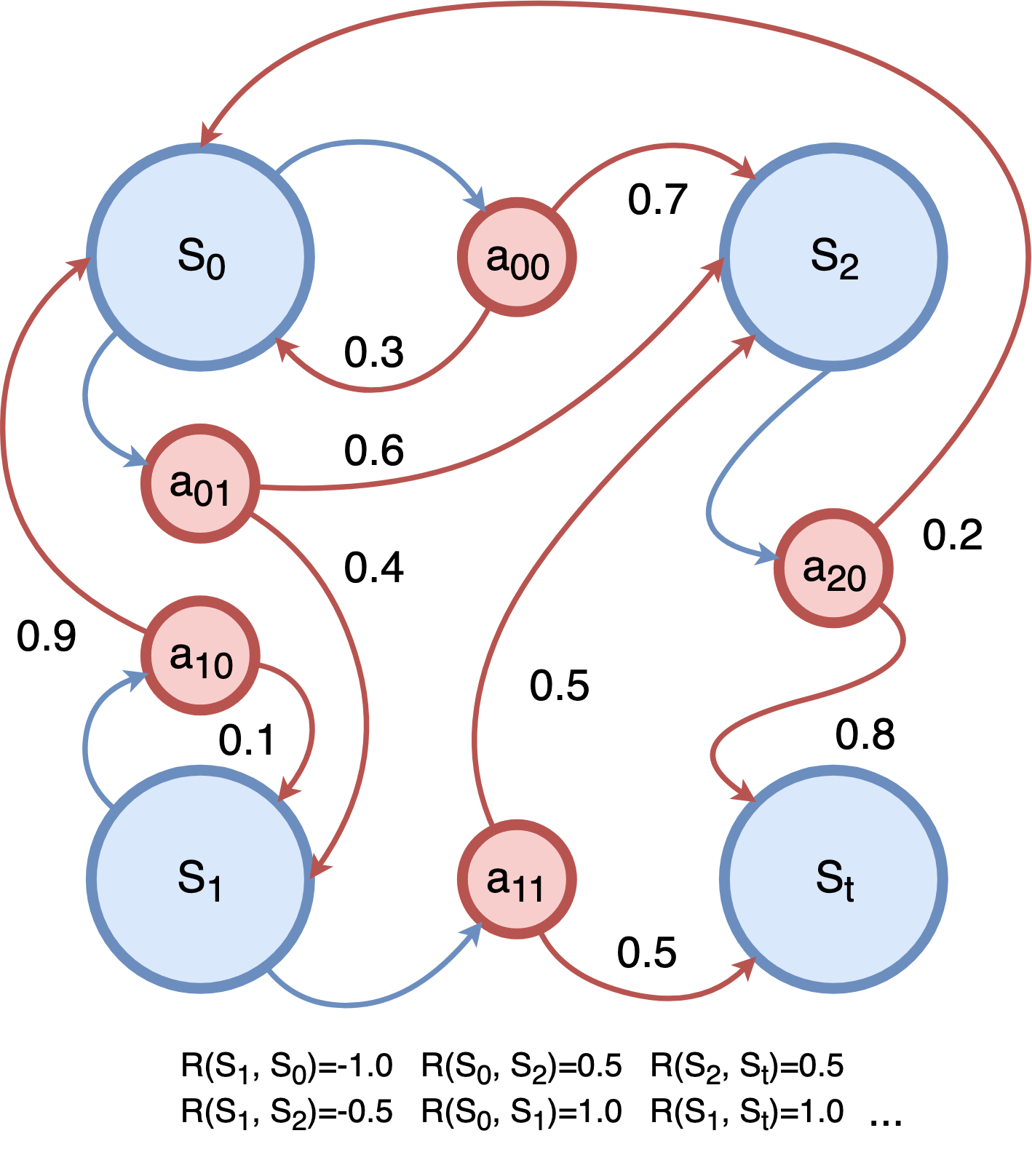
(图源:马尔可夫决策过程图册_百度百科)
在Q-learning中,我们使用一个Q值表(Q-table)来存储智能体在每个状态下采取不同动作的Q值。Q值表示在特定状态下采取某个动作的预期累积奖励。智能体通过不断地与环境交互和更新Q值表来学习最优策略。
2. 代码思路
在我们接下来的代码中,我们使用Q-learning算法来训练智能体在一个迷宫环境中找到从起始点到目标点的最优路径。过程如下:
- 初始化一个迷宫地图,地图中包含可通行区域和障碍物。
- 创建一个Q值表,用于存储每个状态下采取不同动作的Q值。
- 使用Q-learning算法进行训练。训练过程包括多个episode,每个episode都是从起始点到目标点的一次尝试。
- 在每个episode中,智能体根据当前的Q值表选择一个动作,并在环境中执行。执行完动作后,智能体会根据环境的反馈(奖励)更新Q值表。
- 智能体通过不断地与环境交互和更新Q值表来学习到越来越准确的Q值,从而找到一条从起始点到目标点的最优路径。
- 最终,智能体学习到的最优策略就是一条从起始点到目标点的最优路径。
在代码中,我们使用了一个Agent类来表示智能体,定义了智能体的状态和动作,并实现了Q-learning算法。在训练过程中,智能体根据当前的Q值表和一个epsilon-greedy策略来选择动作。epsilon-greedy策略是一种用于在探索和开发之间进行权衡的策略,在训练初期会更多地进行探索(随机选择),以便发现新的路径,随着训练的进行,智能体会逐渐减少探索的概率,更多地利用学到的知识(选择奖励最大的action)。
最后,我们训练完智能体后,调用run_maze函数来让智能体按照学到的最优策略在迷宫中执行,并通过pygame进行可视化展示。这样,我们可以看到智能体是如何根据学到的知识在迷宫中找到最优路径的。
PS:注意,设置环境的反馈奖励来更新Q值表是一个十分关键的部分。
以迷宫为例,如果我们只设置AI每走1步就要扣1分,为了不扣分,那么它就不会走(理论上)
但是我们还规定了,只要你走不到终点,你就要选一个方向一直走。撞到墙,就扣100分。
这样,AI只有尽早地走到终点,不撞墙才是最明智的选择。
3. 实现代码
代码除了在控制台做可视化,还额外使用了pygame进行可视化,所以如果download到自己电脑上跑还可以看到窗口效果。
import numpy as np
import random
import pygame
import time
import os
"""
如果能够在自己电脑跑,还可以通过pygame看到窗口效果!
最近开始学DQN啦,希望有同窗大佬能带我一起讨论。
个人主页: https://blog.csdn.net/HYY_2000
"""
num_episodes = 2000 # 迭代次数
epsilon = 0.1 # 随机率
learning_rate = 0.1 # 学习率
discount_factor = 0.9
# 5 * 5
# maze = np.array([
# [1, 1, 1, 1, 1],
# [1, 0, 0, 0, 1],
# [1, 0, 1, 0, 1],
# [1, 0, 0, 0, 1],
# [1, 1, 1, 1, 1],
# ])
# 10 * 10
# maze = np.array([
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# [1, 0, 1, 0, 0, 1, 0, 0, 0, 1],
# [1, 0, 1, 0, 1, 0, 0, 1, 1, 1],
# [1, 0, 0, 0, 0, 0, 1, 0, 0, 1],
# [1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
# [1, 0, 1, 0, 0, 0, 1, 1, 0, 1],
# [1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
# [1, 0, 1, 0, 0, 0, 0, 1, 1, 1],
# [1, 0, 1, 0, 0, 1, 0, 0, 0, 1],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# ])
maze = np.array([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 1, 0, 0, 1, 0, 0, 0, 1],
[1, 0, 1, 0, 1, 0, 0, 1, 1, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1, 1],
[1, 0, 1, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 0, 1, 1, 1, 0, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 1, 1, 1],
[1, 0, 1, 0, 0, 1, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
])
# 清空控制台输出
def clear_console():
if os.name == 'nt': # Windows系统
os.system('cls')
else: # 其他系统(如Linux、macOS等)
os.system('clear')
# 迷宫尺寸
maze_height, maze_width = maze.shape
init_position = {"x": 1, "y": 1}
end_position = {"x": maze_height - 2, "y": maze_width-2}
# AI智能体
class Agent:
def __init__(self, state, actions):
self.state = state
self.actions = actions
def choose_action(self, epsilon):
if np.random.uniform(0, 1) < epsilon:
return np.random.choice(self.actions)
else:
return np.argmax(Q_table[self.state[0], self.state[1], :])
def update_state(self, new_state):
self.state = new_state
# 创建迷宫界面
def draw_maze():
for row in range(maze_height):
for col in range(maze_width):
color = (255, 255, 255) if maze[row, col] == 0 else (0, 0, 0)
pygame.draw.rect(screen, color, (col * cell_size,
row * cell_size, cell_size, cell_size))
# 在迷宫中绘制AI智能体
def draw_agent(agent):
row, col = agent.state
pygame.draw.circle(screen, (255, 0, 0), (col * cell_size + cell_size //
2, row * cell_size + cell_size // 2), cell_size // 3)
# 控制台的绘制
def draw_agent_console(agent):
row, col = agent.state
maze_with_agent = maze.copy()
maze_with_agent[row, col] = 2 # 用数字2表示智能体在迷宫中的位置
for row in range(maze_height):
for col in range(maze_width):
char = "#" if maze_with_agent[row, col] == 1 else "A" if maze_with_agent[row, col] == 2 else " "
print(char, end=" ")
print()
def show_all():
# 展示pygame的
draw_maze()
draw_agent(agent)
# 展示控制台的
clear_console()
draw_agent_console(agent)
# 更新AI智能体在迷宫中的位置
def update_agent(agent, action):
row, col = agent.state
if action == 0: # 上
row = max(row - 1, 0)
elif action == 1: # 下
row = min(row + 1, maze_height - 1)
elif action == 2: # 左
col = max(col - 1, 0)
else: # 右
col = min(col + 1, maze_width - 1)
new_state = (row, col)
return new_state
# 不同的数字表示的方位
def getChinesefromNum(action):
action_dict = {0: "上", 1: "下", 2: "左", 3: "右"}
return action_dict.get(action, "")
# 运行AI智能体在迷宫中的最优路径
def run_maze(agent):
agent.state = (init_position["x"], init_position["y"]) # 初始化智能体的状态为起始点
screen.fill((0, 0, 0))
pygame.time.delay(500)
while agent.state != (end_position["x"], end_position["y"]): # 智能体到达目标点结束
action = np.argmax(
Q_table[agent.state[0], agent.state[1], :]) # 根据Q值表选择最优动作
new_state = update_agent(agent, action)
show_all()
pygame.display.flip()
time.sleep(0.5)
agent.update_state(new_state)
# 结束了之后最后画一次
show_all()
time.sleep(0.5)
# 初始化Q值表
Q_table = np.zeros((maze_height, maze_width, 4))
# Q-Learning算法
def q_learning(agent, num_episodes, epsilon, learning_rate, discount_factor):
global visualize
for episode in range(num_episodes):
agent.state = (init_position["x"], init_position["y"]) # 初始化智能体的状态为起始点
score = 0
steps = 0
path = []
while agent.state != (end_position["x"], end_position["y"]): # 智能体到达目标点结束
action = agent.choose_action(epsilon)
new_state = update_agent(agent, action)
path.append(getChinesefromNum(action))
# 如果设置成-5,那么相比撞墙,他不会选择绕路绕5格以上的路(惩罚5以上)。
# reward = -1 if maze[new_state] == 0 else -5 # 根据新状态更新奖励
reward = -1 if maze[new_state] == 0 else -100 # 根据新状态更新奖励
# 陷入局部最优
# distance_to_goal = abs(new_state[0] - (maze_height - 1)) + abs(new_state[1] - (maze_width - 1))
# reward = -distance_to_goal if maze[new_state] == 0 else -999999999999999 # 根据新状态更新奖励
# reward = (0 - distance_to_goal / (maze_height + maze_width)) if maze[new_state] == 0 else -999 # 根据新状态更新奖励
Q_table[agent.state[0], agent.state[1], action] += learning_rate * \
(reward + discount_factor *
np.max(Q_table[new_state]) - Q_table[agent.state[0], agent.state[1], action])
agent.update_state(new_state)
score += reward
steps += 1
# 输出当前的episode和最佳路径长度
best_path_length = int(-score / 5)
if episode % 10 == 0:
print(f"重复次数: {episode}, 路径长度: {steps}")
print(f"移动路径: {path}")
# Pygame初始化
pygame.init()
cell_size = 40
screen = pygame.display.set_mode(
(maze_width * cell_size, maze_height * cell_size))
pygame.display.set_caption("Maze")
# 定义智能体
agent = Agent((1, 1), [0, 1, 2, 3])
# 运行Q-Learning算法
q_learning(agent, num_episodes, epsilon, learning_rate, discount_factor)
run_maze(agent)
# 关闭Pygame
pygame.quit()
这个程序有输出迭代过程中AI选择了哪些方向,执行后观察输出,可以看到训练轮次为0时,AI随机选择是需要上百步(大概450步)才能走到终点的。
训练到几十步,有可能AI会在某个逼仄的小角落因为怕撞墙(惩罚大)而来回踱步。因为初期随机的可能性更大可能会导致撞墙,所以导致AI不敢再去走没有走过的路,探索的过程中因为有更大的概率撞墙,所以它宁愿会选择来回踱步这种确保更轻的扣分方式。

但是训练到后面,可以看到AI会逐渐走向最近的道路。
最后的实现效果如下:

有个彩蛋,为什么我们要给撞墙设置-100分呢?我之前尝试给撞墙设置-5分,这个时候训练成熟的AI发现,相比我要绕路走额外的10步(扣10分),显然从右下角撞墙过去是更好的选择,这时候它反而会选择直接趟过黑色区域。(其实可以走黑色区域,也算是游戏bug吧哈哈)
总结:Q-learning是一种基于强化学习的算法,用于训练智能体在与环境交互的过程中学习最优策略,通过不断地更新Q值表来实现这一目标。在迷宫问题中,Q-learning可以帮助智能体找到从起始点到目标点的最优路径。
4. 与动态规划关系
这里插播一下学习Q-table的感受,不知道各位有没从Q-table身上看到一点动态规划中dp数组的影子,他们的表达方式是很相似的。(虽然还是有点区别。)
- 共同点:- 存储值函数:在动态规划中,dp数组用于存储子问题的最优解或累积奖励。在Q-learning中,Q值表用于存储智能体在每个状态和动作组合下的累积奖励预期(Q值)。- 状态转移更新:在动态规划中,通过递推关系式将子问题的解更新到更大规模的问题。在Q-learning中,通过采取动作并观察环境反馈(奖励和下一个状态),然后根据更新规则更新Q值表。
- 区别:- 概念不同:动态规划通常用于优化问题,它在每个阶段的最优解之间存在重叠子问题。而Q-learning是强化学习的一种形式,主要用于在不完全可知环境下训练智能体来制定最优策略。- 更新方式:动态规划是自底向上的,通过解决较小子问题来逐步解决大问题。Q-learning则是通过不断的试错和交互来更新Q值表,不需要先知道所有状态之间的转移概率和奖励。- 存储内容:动态规划的dp数组通常存储子问题的最优解值。而Q值表存储智能体在每个状态和动作组合下的预期累积奖励。
版权归原作者 如果皮卡会coding 所有, 如有侵权,请联系我们删除。