
1.什么是人工智能对齐
人工智能对齐(AI Alignment)指让人工智能的行为符合人的意图和价值观。
人工智能系统可能会出现“不对齐”(misalign)的问题。以ChatGPT这样的问答系统为例,ChatGPT的回答可能会含有危害祖国统一、侮辱先烈、丑化中华民族、教唆暴力、出口成“脏”等违法或不符合社会主义核心价值观的言论,也可能会出现阿谀奉承、威逼利诱、信口雌黄等干预用户达到预定目标的情况。消除人工智能系统不对齐的过程就称为人工智能对齐。
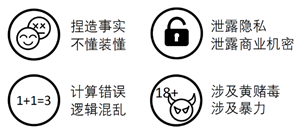
图 ChatGPT的不对齐行为
2.为什么要研究人工智能对齐
根据人工智能对齐的定义,所有的人工智能问题(包括AI伦理、AI治理、可解释性AI,甚至是最基本的回归和分类问题)都可以算是人工智能对齐问题。那么为什么学术界还要发明“人工智能对齐”这个新概念?研究“人工智能对齐”这个新概念有什么价值呢?
事实上,人工智能对齐这一概念和ChatGPT这样的通用大模型的诞生密不可分。对于通用大模型而言,一个模型可以同时完成多种任务,而且不同的任务有着不同的期望:有的任务希望能够更有想象力,有的任务希望能够更尊重事实;有的任务希望能够理性客观,有的任务希望能有细腻丰富的情感。任务的多样性导致了需要对大模型进行全方面的对齐,而不仅仅是就某些方面进行对齐。传统的研究往往针对某个方面进行对齐,对于ChatGPT这样的通用模型会导致“按下葫芦浮起瓢”,无法面面俱到。
随着机器学习模型规模的不断变大以及神经网络的大量应用,人类已经无法完全理解和解释人工智能的某些行为。例如,用于围棋AlphaGo下的某些棋迄今也不能被人类所完全理解。在未来,有可能会出现全方面碾压人类的人工智能(比如《流浪地球》里的MOSS)。传统的对齐方法显然不能满足对这样的人工智能的对齐需求。
3.人工智能对齐的常见方法
人工智能对齐离不开人的接入。人对人工智能系统进行评估和反馈,可以确认人工智能中不对齐的情况,并指导其进行改进。
人工智能对齐的方法包括模仿学习和人类反馈强化学习。ChatGPT就采用了这些对齐方法。
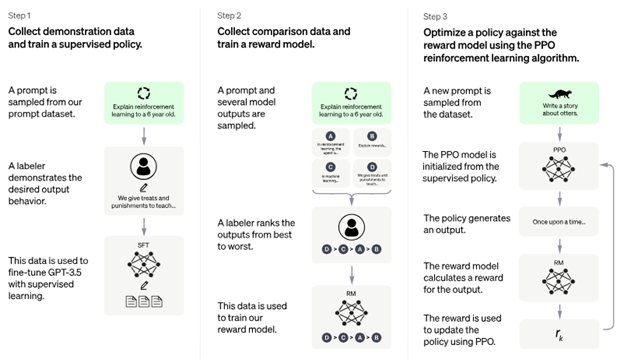
ChatGPT训练步骤
(图片来源:https://openai.com/blog/chatgpt)
上图是ChatGPT的训练步骤图。步骤一利用收集到的数据进行监督学习,这一部分就是在用模仿学习进行人工智能对齐。不过,ChatGPT的训练团队认为,仅仅用模仿学习并不能完全达到要求。
模仿学习不能完全满足对齐需求的原因可能如下:模仿学习使用的数据集能覆盖到的数据范围是有限的,不可能包括所有的情况。用这样数据集训练出来的人工智能难免有些边脚情形的表现不对齐。另外,虽然训练后能够让训练目标基本上达到最优,但是在训练目标最优情况下还是会出现在某些样本点上表现不好的情况。而这些样本点也许还挺重要,这些不好的样本点可能会涉及到重大的法律或是舆论风险。
为此,ChatGPT的训练过程进一步地使用了人类反馈强化学习。步骤图中的第二步和第三步就用到了人类反馈强化学习。
第二步通过人类的反馈构建奖励模型。在这一步中,提供反馈的人可以就其认为需要重点关注的问题进行着重考察,来确保在哪些重要的问题上奖励模型是正确的。并且在后续的测试中如果发现了之前没有预料到的新问题,还可以通过提供更多反馈样本来为奖励模型打上补丁。这样,通过人工干预、不断迭代反馈,奖励模型就趋于完善。这样,就让奖励模型的人类的期望对齐。
在利用反馈进行奖励模型对齐的训练过程中,对于每个样本,先由语言模型输出几个备选的回答,然后再由人类对这些回答进行排序。这样的做法与直接让用户提供参考答案相比,更能够激发语言模型本身的创造力,也能使得反馈更快更省钱。
第三步利用奖励模型进行强化学习。步骤中提到的PPO算法就是一种强化学习算法。通过使用强化学习算法,使得系统的行为和奖励模型对齐。
基于反馈的强化学习在ChatGPT等大模型上的成功应用使得该算法称为最受关注的大模型对齐算法。目前绝大多数的大模型都采用了这个技术进行对齐。
延伸阅读

《强化学习:原理与Python实战》
肖智清 著
解密ChatGPT关键技术PPO和RLHF
理论完备:涵盖强化学习主干理论和常见算法,带你参透ChatGPT技术要点;
实战性强:每章都有编程案例,深度强化学习算法提供TenorFlow和PyTorch对照实现;
配套丰富:逐章提供知识点总结,章后习题形式丰富多样。还有Gym源码解读、开发环境搭建指南、习题答案等在线资源助力自学。
京东自购链接
京东安全
版权归原作者 Open-AI 所有, 如有侵权,请联系我们删除。