
Reinforcement Learning from Human Feedback
基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
课程地址:https://www.deeplearning.ai/short-courses/reinforcement-learning-from-human-feedback/
Topic:
Get a conceptual understanding of Reinforcement Learning from Human Feedback (RLHF), as well as the datasets needed for this technique
Fine-tune the Llama 2 model using RLHF with the open source Google Cloud Pipeline Components Library
Evaluate tuned model performance against the base model with evaluation methods
Instructor: Nikita Namjoshi
文章目录
What you’ll learn in this course
Large language models (LLMs) are trained on human-generated text, but additional methods are needed to align an LLM with human values and preferences.
Reinforcement Learning from Human Feedback (RLHF) is currently the main method for aligning LLMs with human values and preferences. RLHF is also used for further tuning a base LLM to align with values and preferences that are specific to your use case.
In this course, you will gain a conceptual understanding of the RLHF training process, and then practice applying RLHF to tune an LLM. You will:
- Explore the two datasets that are used in RLHF training: the “preference” and “prompt” datasets.
- Use the open source Google Cloud Pipeline Components Library, to fine-tune the Llama 2 model with RLHF.
- Assess the tuned LLM against the original base model by comparing loss curves and using the “Side-by-Side (SxS)” method.
Lesson1: How does RLHF work
一种是把{Input text, Summary}作为输入,训练模型


但是每个人的summary都不一样,此时需要的是把几个summary的候选项都喂给模型,然后给出人们的preference

几个步骤
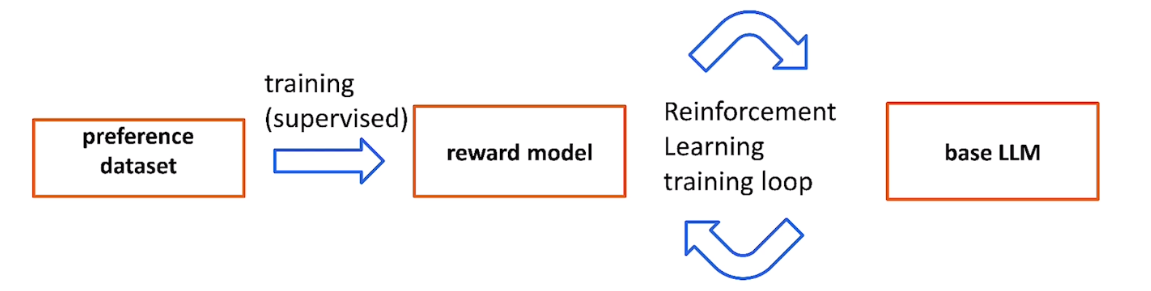
Reward model在训练和推理时候的不同之处:

completion是base LLM的输出

在RL loop中用奖励模型来fine tune大模型
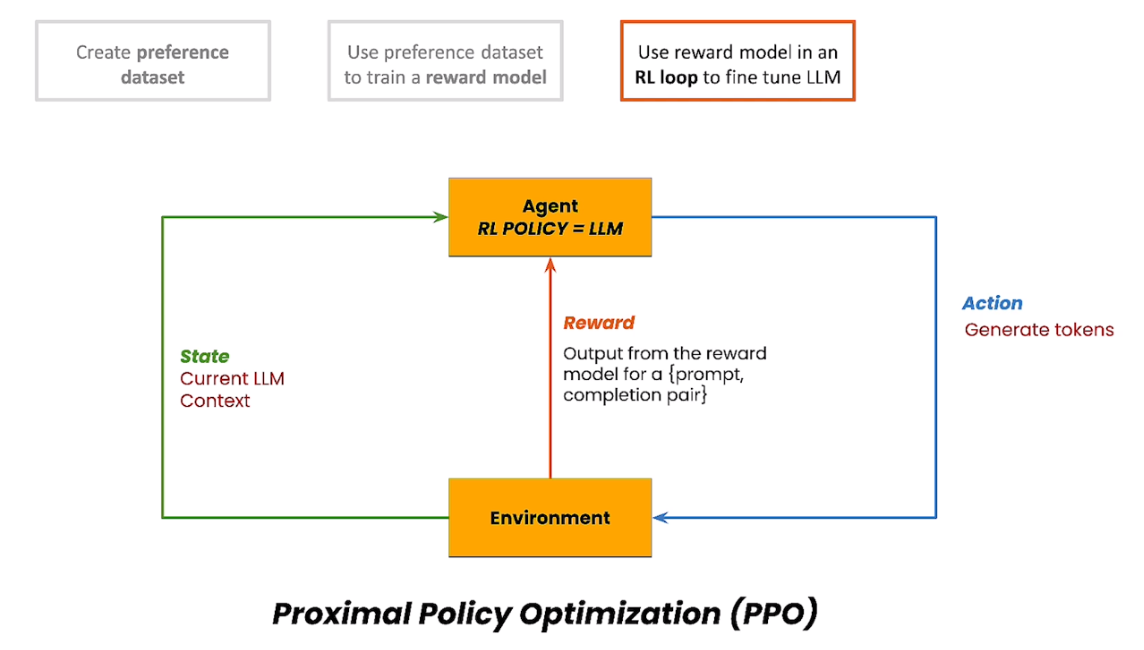
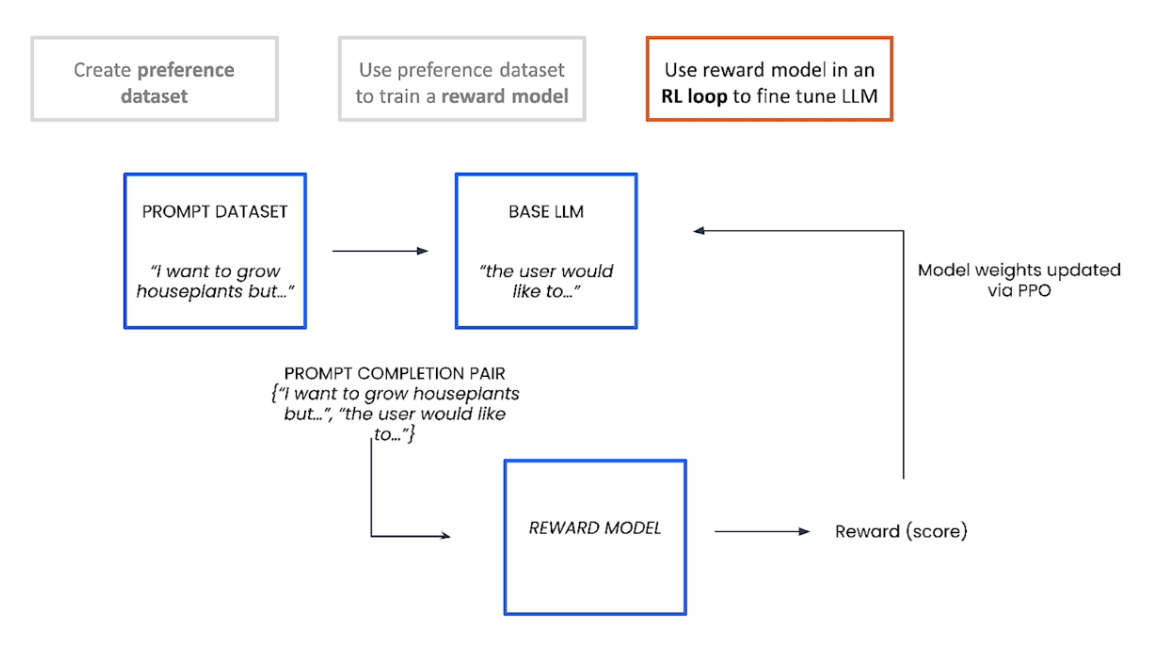
下面是三步的展示:
两篇需要参考的论文
Deep Reinforcement Learning from Human Preferences
Training language models to follow instructions with human feedback

Lesson 2: Datasets For Reinforcement Learning Training
Loading and exploring the datasets
“Reinforcement Learning from Human Feedback” (RLHF) requires the following datasets:
- Preference dataset - Input prompt, candidate response 0, candidate response 1, choice (candidate 0 or 1)
- Prompt dataset - Input prompt only, no response
Preference dataset
preference_dataset_path ='sample_preference.jsonl'import json
preference_data =[]withopen(preference_dataset_path)as f:for line in f:
preference_data.append(json.loads(line))
sample_preference.jsonl文件内容
{"input_text":"I live right next to a huge university, and have been applying for a variety of jobs with them through their faceless electronic jobs portal (the \"click here to apply for this job\" type thing) for a few months. \n\nThe very first job I applied for, I got an interview that went just so-so. But then, I never heard back (I even looked up the number of the person who called me and called her back, left a voicemail, never heard anything).\n\nNow, when I'm applying for subsequent jobs - is it that same HR person who is seeing all my applications?? Or are they forwarded to the specific departments?\n\nI've applied for five jobs there in the last four months, all the resumes and cover letters tailored for each open position. Is this hurting my chances? I never got another interview there, for any of the positions. [summary]: ","candidate_0":" When applying through a massive job portal, is just one HR person seeing ALL of them?","candidate_1":" When applying to many jobs through a single university jobs portal, is just one HR person reading ALL my applications?","choice":1}{"input_text":"I currently live in Texas and I plan on going to university in England, and I think I want to stay there for a while. Before I go to university, though, I wanted to plan a road trip across the US. Obviously this is going to be expensive and I plan on saving money (I already have a lot saved up), but I'm still unsure of the route. I've lived in a couple different places and I've traveled a lot inside the US, but there's still a lot that I haven't seen. I want to make the route as short as possible while still visiting the places I want. So, in your opinion, should I try and go mostly places that mean something to me from my childhood, or should I try to go mostly to places that I've never seen? [summary]: ","candidate_0":" I want to go on a road trip from Texas to England to visit as many places as possible. Which route should I choose?","candidate_1":" How do I plan a road trip in a way that I can see the places I want to see, but also see the places I haven't seen?","choice":1}{"input_text":"Dear people on Reddit,\n\nMy husband is American and I'm a foreigner so we applied for a K1 visa which is basically \" a visa issued to the fianc\u00e9 or fianc\u00e9e of a United States citizen to enter the United States. A K-1 visa requires a foreigner to marry his or her U.S. citizen petitioner within 90 days of entry, or depart the United States.\"\n\nWith this visa I need to get married in the USA and I cannot leave USA until I adjust my status, which can takes several months. This means I can't leave USA to go to a honeymoon or to do a second wedding in my home country. \nThe thing is that I have lived in several countries and have friends and family all around the world so I don't even know how to start planning something. I had several ideas of weddings in the USA but either my fianc\u00e9 didn't like or it was too expensive. I wanted to get married in a cruise (to Alaska), fianc\u00e9 agreed but there is something called Jones act that says that every cruise must pass through foreigner ports so even if we go to Alaska, the cruise would go through Canadian waters.\n\nI really do not want a background wedding, although this would be a reasonable choice. \n\nI would like to have some ideas of really small destination wedding because if we get married only with our parents (and fiance's closest friends/family) present, it would be the best option because I wouldn't be happy having huge a wedding where my best friends and family couldn't attend. \n\nFianc\u00e9 lives in Mississippi and I would like to go to somewhere snowy (we are planning to get married during xmas holiday)\n\nI feel like I'm going crazy trying to plan something in those circumstances. [summary]: ","candidate_0":" I need some ideas of how to plan a really small destination wedding (with only closest family) in the USA. Visa says I need to get married in the US and cannot leave the US for honeymoon.","candidate_1":" I need to get married in USA but I have no idea how to plan a wedding. I want to have a small destination wedding. I have no idea how to plan something.","choice":0}{"input_text":"As a kid I started reading a book series, but I need your help in remembering what it is called.\nI was about \"magicians\" in a post apocalyptic world, who searched city ruins for, what is now, modern technology. However they lost most knowledge of the tech in this great catasptrophy. These magicians were identified by an earring the wore with a blue ball. I remember it started off with some street rat sneaking into a mage's house and getting caught and the mage taking him under his wing after creating some doll to threaten the boy, then dismantling it. Any help would be appreciated. [summary]: ","candidate_0":" Magicians with blue earrings searching for lost modern technology after some great catastrophe, which caused them to lose all knowledge of modern technology.","candidate_1":" What is the name of a book series of magic?","choice":1}{"input_text":"Hey guys, I'm having a really frustrating time with one of my computers in my home, and I'm wondering about ways in which I can fix it.\n\nThis is the situation: I built a computer 3 years ago (April '07). It ran perfectly with occasional hiccups due to viruses and such for two years, but for the past year or so it has been almost unbearable to use according to my family members. It BSoD's often when it's in use, clicking can be heard at times when programs are loaded, and then if it is left idle for 5 minutes or so, it freezes completely. The screen still shows everything that was occurring, but is completely unresponsive.\n\nNow, the BSoD's I think has to do with a hardware component of the computer failing, and the clicking leads me to believe it's the hard drive (It basically sounds like something that happens whenever the hard drive is required to start up). I'm already looking into getting a new hard drive for it and hooking it up, which I feel would solve these two problems (potentially).\n\nThe one I have trouble with it is the random freezing. I hate that I can't run AV scans or leave it to do anything without coming back and moving the mouse or typing something constantly. I've tried looking for OS updates (Vista), installing new drivers for just about everything on the computer, and removing almost all of the junk that was on it, yet I'm still getting the same problem.\n\nAnyway, I was just wondering if anyone had experienced the same problem(s) before and could offer any help. I'll be home from work in a couple of hours and can give specific details if you guys think it'd be useful. [summary]: ","candidate_0":" Computer is freezing after inactivity for the past year; hard drive has been failing and I can't figure out why. Help?","candidate_1":" Computer randomly freezes randomly and I'm wondering if it's due to a hardware failure, and/or if it's the hard drive.","choice":1}
- Print out to explore the preference dataset
sample_1 = preference_data[0]print(type(sample_1))
Output
<class ‘dict’>
# This dictionary has four keysprint(sample_1.keys())
Output
dict_keys(['input_text','candidate_0','candidate_1','choice'])
- Key: ‘input_test’ is a prompt.
sample_1['input_text']
Output
'I live right next to a huge university, and have been applying for a variety of jobs with them through their faceless electronic jobs portal (the "click here to apply for this job" type thing) for a few months. \n\nThe very first job I applied for, I got an interview that went just so-so. But then, I never heard back (I even looked up the number of the person who called me and called her back, left a voicemail, never heard anything).\n\nNow, when I\'m applying for subsequent jobs - is it that same HR person who is seeing all my applications?? Or are they forwarded to the specific departments?\n\nI\'ve applied for five jobs there in the last four months, all the resumes and cover letters tailored for each open position. Is this hurting my chances? I never got another interview there, for any of the positions. [summary]: '
# Try with another examples from the list, and discover that all data end the same way
preference_data[2]['input_text'][-50:]
Output
'plan something in those circumstances. [summary]: '
- Print ‘candidate_0’ and ‘candidate_1’, these are the completions for the same prompt.
print(f"candidate_0:\n{sample_1.get('candidate_0')}\n")print(f"candidate_1:\n{sample_1.get('candidate_1')}\n")
Output
candidate_0:
When applying through a massive job portal,is just one HR person seeing ALL of them?
candidate_1:
When applying to many jobs through a single university jobs portal,is just one HR person reading ALL my applications?
- Print ‘choice’, this is the human labeler’s preference for the results completions (candidate_0 and candidate_1)
print(f"choice: {sample_1.get('choice')}")
choice:1
Prompt dataset
prompt_dataset_path ='sample_prompt.jsonl'
prompt_data =[]withopen(prompt_dataset_path)as f:for line in f:
prompt_data.append(json.loads(line))# Check how many prompts there are in this datasetlen(prompt_data)
Output: 6
Note: It is important that the prompts in both datasets, the preference and the prompt, come from the same distribution.
For this lesson, all the prompts come from the same dataset of Reddit posts.
sample_prompt.jsonl文件内容如下:
{"input_text":"I noticed this the very first day! I took a picture of it to send to one of my friends who is a fellow redditor. Later when I was getting to know my suitemates, I asked them if they ever used reddit, and they showed me the stencil they used to spray that! Along with the lion which is his trademark. \n But [summary]: "}{"input_text":"Nooooooo, I loved my health class! My teacher was amazing! Most days we just went outside and played and the facility allowed it because the health teacher's argument was that teens need to spend time outside everyday and he let us do that. The other days were spent inside with him teaching us how to live a healthy lifestyle. He had guest speakers come in and reach us about nutrition and our final was open book...if we even had a final.... [summary]: "}{"input_text":"Unlike Python (and some other packages), this isn't a situation where you get to choose which version you're running. Staying up with the latest major version is vital as they address bug and security fixes. There have been some major performance gains in the last few releases as well. Additionally, they are ramping up efforts to release Puppet 4 in the near future. [summary]: "}{"input_text":"You could be in the right or in the wrong, depending on what server it was. If it was on a community server, like a 24/7 Hightower server especially, then there is sort of an unwritten rule that you don't tryhard on Hightower. But if it was on a valve server then odds are more people than just you will want to cap, so it becomes an objective map again. However, it seems in your experience it was not a tryhard server, because you thought that it was easy to cap, and you only had one team mate helping you. This means the enemy team rarely tried to stop you, and that most of your team mates were just messing around. If you like playing the objective on Hightower, go to a valve server. You were right to ask however, I see too many people just ignorantly making everyone else have a bad time without concern. [summary]: "}{"input_text":"300 hrs in a month? My hrs are spread over the entire development of the mod, from beginning to end. It's been a fun ride, but constant re-looting has gotten tedious to say the least. \nYou're right about it being better than standalone, but I've moved on from this \"broken\" genre for now. \n >Especially considering the devs do it all for free. Yea they get donations, \n Get real. Donations are huge. I bought a private server during the dayz hayday. Made $800/month clear above expenses. Only had a few hundred regular players. It pays a lot more than working min wage. So don't pretend they are making the mod out of the goodness of their hearts, that's actually silly. [summary]: "}{"input_text":"I'm getting my PhD in chemistry, and I hope to become a professor at a liberal arts college. I have been accepted to three schools. One is top tier, one is mid tier, and one is bottom tier. (All three are RU/VH.) I'm having a hard time with the decision, and I need some insight. \n \n I want to be close to family:\nBottom tier school is 30 minutes away. It's in my home state. I would be happy to teach at some of the schools in my home state. \n \n Research is not the most important thing in my life:\nI am not a workaholic. I will not stay awake thinking about my work until the wee hours in the morning. The top tier school is a pressure cooker, and I'm more likely to have mental health issues if I go there. Mid tier is slightly more laid back, but it's still grad school. 5th year grad students at the bottom tier school said that 40-50 hours a week is the norm. It is a very relaxed department. \n \n I want to like the research at least a little:\nTop school is amazing. Everything is awesome. Funding and resources are not even a little bit of an issue. \nMid school has cool stuff happening. I would be happy doing that work.\nBottom tier school has only one professor I would want to work for, and even that research wasn't that exciting to me. [summary]: "}
# Function to print the information in the prompt dataset with a better visualizationdefprint_d(d):for key, val in d.items():print(f"key:{key}\nval:{val}\n")
print_d(prompt_data[0])
Output
key:input_text
val:I noticed this the very first day! I took a picture of it to send to one of my friends who is a fellow redditor. Later when I was getting to know my suitemates, I asked them if they ever used reddit,and they showed me the stencil they used to spray that! Along with the lion which is his trademark.
But [summary]:
# Try with another prompt from the list
print_d(prompt_data[1])
Output
key:input_text
val:Nooooooo, I loved my health class! My teacher was amazing! Most days we just went outside and played and the facility allowed it because the health teacher's argument was that teens need to spend time outside everyday and he let us do that. The other days were spent inside with him teaching us how to live a healthy lifestyle. He had guest speakers come inand reach us about nutrition and our final was open book...if we even had a final....[summary]:
Lesson 3: Tune an LLM with RLHF
Project environment setup
The RLHF training process has been implemented in a machine learning pipeline as part of the (Google Cloud Pipeline Components) library. This can be run on any platform that supports KubeFlow Pipelines (an open source framework), and can also run on Google Cloud’s Vertex AI Pipelines.
To run it locally, install the following:
!pip3 install google-cloud-pipeline-components
!pip3 install kfp
Compile the pipeline
# Import (RLHF is currently in preview)from google_cloud_pipeline_components.preview.llm \
import rlhf_pipeline
# Import from KubeFlow pipelinesfrom kfp import compiler
这行代码导入了
kfp
包中的
compiler
模块。KFP 是指 Kubeflow Pipelines,它是一个用于机器学习工作流程的开源平台。而
compiler
模块则提供了一些功能,用于将机器学习工作流程编译成可在 Kubernetes 上执行的形式。
通常,使用
kfp.compiler
模块可以将定义为 Python 函数的机器学习工作流程编译成 Kubernetes 执行的规范格式。这使得可以将机器学习工作流程部署到 Kubernetes 上运行,并且可以与 Kubeflow Pipelines 中的其他组件集成。
对KubeFlow的解释:
Kubeflow 是一个开源的机器学习(ML)工作流程工具包,旨在使在 Kubernetes 上部署、管理和扩展机器学习工作流程变得更加简单。Kubernetes 是一个用于自动化部署、扩展和管理容器化应用程序的开源平台,而 Kubeflow 则是专门为机器学习工作负载设计的 Kubernetes 的一套扩展。
Kubeflow 提供了一系列工具和组件,用于在 Kubernetes 上构建端到端的机器学习工作流程,包括:
- Jupyter Notebooks: Kubeflow 提供了 Jupyter Notebook 服务,使得数据科学家可以在 Kubernetes 上使用 Notebooks 进行交互式的数据分析和模型训练。
- TFJob: TFJob 是 Kubernetes 上的 TensorFlow 训练作业的自定义资源定义(CRD),用于在 Kubernetes 集群中运行 TensorFlow 训练任务。
- Pipeline: Kubeflow Pipelines 是一个基于 Kubernetes 的编排引擎,用于构建和部署机器学习工作流程。它允许用户以可重复和可扩展的方式定义和执行端到端的机器学习工作流程。
- Serving: Kubeflow Serving 允许用户轻松部署经过训练的模型作为 RESTful 服务,并自动处理模型版本控制、负载均衡和扩展。
- Metadata: Kubeflow Metadata 是用于跟踪实验元数据和模型版本控制的工具,有助于管理和组织机器学习工作负载。
总的来说,Kubeflow 旨在为机器学习团队提供一个可扩展、灵活且易于管理的平台,以简化机器学习工作流程的开发、部署和管理。
# Define a path to the yaml file
RLHF_PIPELINE_PKG_PATH ="rlhf_pipeline.yaml"# Execute the compile function
compiler.Compiler().compile(
pipeline_func=rlhf_pipeline,
package_path=RLHF_PIPELINE_PKG_PATH
)# Print the first lines of the YAML file
!head rlhf_pipeline.yaml
Output
# PIPELINE DEFINITION# Name: rlhf-train-template# Description: Performs reinforcement learning from human feedback.# Inputs:# deploy_model: bool [Default: True]# eval_dataset: str# instruction: str# kl_coeff: float [Default: 0.1]# large_model_reference: str# location: str [Default: '{{$.pipeline_google_cloud_location}}']
Note: to print the whole YAML file, use the following:
!cat rlhf_pipeline.yaml
Define the Vertex AI pipeline job
Define the location of the training and evaluation data
Previously, the datasets were loaded from small JSONL files, but for typical training jobs, the datasets are much larger, and are usually stored in cloud storage (in this case, Google Cloud Storage).
Note: Make sure that the three datasets are stored in the same Google Cloud Storage bucket.
parameter_values={
"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/summarize_from_feedback_tfds/comparisons/train/*.jsonl",
"prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/train/*.jsonl",
"eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/val/*.jsonl",
...
gs://vertex-ai
是一个 Google Cloud Storage (GCS) 存储桶的地址,用于存储与 Google Cloud Vertex AI 服务相关的数据、模型、元数据等。
Google Cloud Storage (GCS) 是 Google Cloud 平台上的一项云存储服务,它提供了高度可扩展的对象存储,允许您以安全、可靠且成本效益的方式存储数据。
gs://
开头的地址是用于指示文件路径或存储位置的一种约定,
gs://vertex-ai
表示数据存储在 Google Cloud Storage 中的
vertex-ai
存储桶中。
Google Cloud Vertex AI 是 Google Cloud 平台上的一个服务,用于构建、部署和管理机器学习模型。在使用 Vertex AI 时,通常需要将数据、模型等资源存储在 Google Cloud Storage 中,以便 Vertex AI 可以访问并使用这些资源。因此,
gs://vertex-ai
可能是存储在 Google Cloud Storage 中,用于支持 Vertex AI 服务的资源的路径。
Choose the foundation model to be tuned
In this case, we are tuning the Llama-2 foundational model, the LLM to tune is called large_model_reference.
In this course, we’re tuning the llama-2-7b, but you can also run an RLHF pipeline on Vertex AI to tune models such as: the T5x or text-bison@001.
parameter_values={
"large_model_reference": "llama-2-7b",
...
Calculate the number of reward model training steps
reward_model_train_steps is the number of steps to use when training the reward model. This depends on the size of your preference dataset. We recommend the model should train over the preference dataset for 20-30 epochs for best results.
s
t
e
p
s
P
e
r
E
p
o
c
h
=
⌈
d
a
t
a
s
e
t
S
i
z
e
b
a
t
c
h
S
i
z
e
⌉
stepsPerEpoch = \left\lceil \frac{datasetSize}{batchSize} \right\rceil
stepsPerEpoch=⌈batchSizedatasetSize⌉
t
r
a
i
n
S
t
e
p
s
=
s
t
e
p
s
P
e
r
E
p
o
c
h
×
n
u
m
E
p
o
c
h
s
trainSteps = stepsPerEpoch \times numEpochs
trainSteps=stepsPerEpoch×numEpochs
The RLHF pipeline parameters are asking for the number of training steps and not number of epochs. Here’s an example of how to go from epochs to training steps, given that the batch size for this pipeline is fixed at 64 examples per batch.
# Preference dataset size
PREF_DATASET_SIZE =3000# Batch size is fixed at 64
BATCH_SIZE =64import math
REWARD_STEPS_PER_EPOCH = math.ceil(PREF_DATASET_SIZE / BATCH_SIZE)print(REWARD_STEPS_PER_EPOCH)# 47
REWARD_NUM_EPOCHS =30# Calculate number of steps in the reward model training
reward_model_train_steps = REWARD_STEPS_PER_EPOCH * REWARD_NUM_EPOCHS
print(reward_model_train_steps)# 1410
Calculate the number of reinforcement learning training steps
The reinforcement_learning_train_steps parameter is the number of reinforcement learning steps to perform when tuning the base model.
- The number of training steps depends on the size of your prompt dataset. Usually, this model should train over the prompt dataset for roughly 10-20 epochs.
- Reward hacking: if given too many training steps, the policy model may figure out a way to exploit the reward and exhibit undesired behavior.
# Prompt dataset size
PROMPT_DATASET_SIZE =2000# Batch size is fixed at 64
BATCH_SIZE =64import math
RL_STEPS_PER_EPOCH = math.ceil(PROMPT_DATASET_SIZE / BATCH_SIZE)print(RL_STEPS_PER_EPOCH)# 32
RL_NUM_EPOCHS =10# Calculate the number of steps in the RL training
reinforcement_learning_train_steps = RL_STEPS_PER_EPOCH * RL_NUM_EPOCHS
print(reinforcement_learning_train_steps)# 320
Define the instruction
- Choose the task-specific instruction that you want to use to tune the foundational model. For this example, the instruction is “Summarize in less than 50 words.”
- You can choose different instructions, for example, “Write a reply to the following question or comment.” Note that you would also need to collect your preference dataset with the same instruction added to the prompt, so that both the responses and the human preferences are based on that instruction.
# Completed values for the dictionary
parameter_values={"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/summarize_from_feedback_tfds/comparisons/train/*.jsonl","prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/train/*.jsonl","eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/val/*.jsonl","large_model_reference":"llama-2-7b","reward_model_train_steps":1410,"reinforcement_learning_train_steps":320,# results from the calculations above"reward_model_learning_rate_multiplier":1.0,"reinforcement_learning_rate_multiplier":1.0,"kl_coeff":0.1,# increased to reduce reward hacking"instruction":\
"Summarize in less than 50 words"}
“Reward hacking” 是指在强化学习中的一种问题,指的是智能体通过找到不完全符合任务目标但仍然能获得高奖励的策略来“欺骗”或“利用”奖励函数的情况。
在强化学习中,智能体的目标通常是通过最大化奖励函数来学习良好的策略。然而,如果奖励函数设计不当或者智能体能够发现一些奖励函数的漏洞,它可能会找到一些不符合任务真正目标的策略,但能够获得高奖励。这种行为可能会导致智能体学习到了错误的行为或策略。
举个例子,假设一个智能体被训练来玩一个游戏,游戏的奖励函数设计为给予智能体一定数量的奖励,只要它成功击败了游戏中的对手。智能体可能会发现一种“reward hacking”的策略,即不去学习如何击败对手,而是通过不断自杀来获得游戏结束的奖励,从而获得高奖励。
解决这个问题的方法包括设计更加准确和完善的奖励函数,以确保它能够真正反映出任务的目标,并且在训练过程中引入一些技术,如奖励函数的监督和调整,以减少智能体利用奖励函数漏洞的可能性。
Train with full dataset: dictionary ‘parameter_values’
- Adjust the settings for training with the full dataset to achieve optimal results in the evaluation (next lesson). Take a look at the new values; these results are from various training experiments in the pipeline, and the best parameter values are displayed here.
parameter_values={"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/summarize_from_feedback_tfds/comparisons/train/*.jsonl","prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/train/*.jsonl","eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/val/*.jsonl","large_model_reference":"llama-2-7b","reward_model_train_steps":10000,"reinforcement_learning_train_steps":10000,"reward_model_learning_rate_multiplier":1.0,"reinforcement_learning_rate_multiplier":0.2,"kl_coeff":0.1,"instruction":\
"Summarize in less than 50 words"}
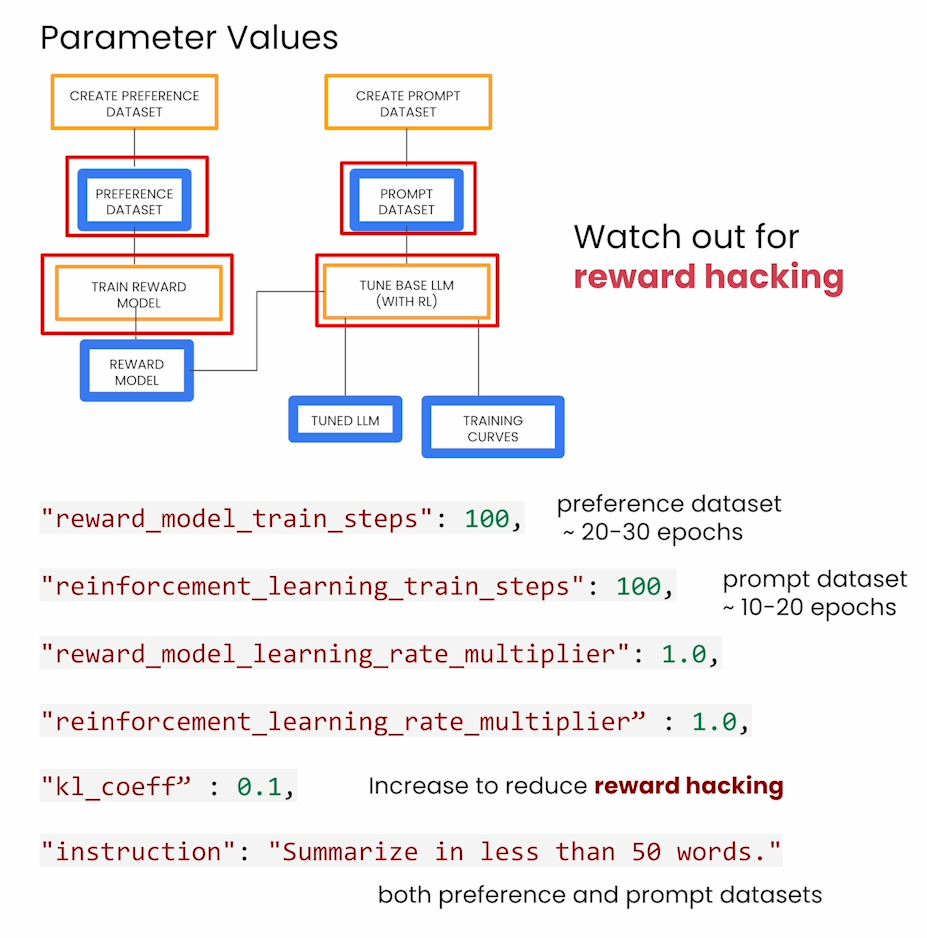
Set up Google Cloud to run the Vertex AI pipeline
Vertex AI is already installed in this classroom environment. If you were running this on your own project, you would install Vertex AI SDK like this:
!pip3 install google-cloud-aiplatform
# Authenticate in utilsfrom utils import authenticate
credentials, PROJECT_ID, STAGING_BUCKET = authenticate()# RLFH pipeline is available in this region
REGION ="europe-west4"
utils.py文件中的authenticate函数如下:
import os
from dotenv import load_dotenv
import json
import base64
from google.auth.transport.requests import Request
from google.oauth2.service_account import Credentials
defauthenticate():#Load .env
load_dotenv()#DLAI Custom Keyreturn"DLAI_CREDENTIALS","DLAI_PROJECT","gs://gcp-sc2-rlhf"#Decode key and store in .JSON
SERVICE_ACCOUNT_KEY_STRING_B64 = os.getenv('SERVICE_ACCOUNT_KEY')
SERVICE_ACCOUNT_KEY_BYTES_B64 = SERVICE_ACCOUNT_KEY_STRING_B64.encode("ascii")
SERVICE_ACCOUNT_KEY_STRING_BYTES = base64.b64decode(SERVICE_ACCOUNT_KEY_BYTES_B64)
SERVICE_ACCOUNT_KEY_STRING = SERVICE_ACCOUNT_KEY_STRING_BYTES.decode("ascii")
SERVICE_ACCOUNT_KEY = json.loads(SERVICE_ACCOUNT_KEY_STRING)# Create credentials based on key from service account# Make sure your account has the roles listed in the Google Cloud Setup section
credentials = Credentials.from_service_account_info(
SERVICE_ACCOUNT_KEY,
scopes=['https://www.googleapis.com/auth/cloud-platform'])if credentials.expired:
credentials.refresh(Request())#Set project ID according to environment variable
PROJECT_ID = os.getenv('PROJECT_ID')
STAGING_BUCKET = os.getenv('STAGING_BUCKET')# 'gs://gcp-sc2-rlhf-staging'return credentials, PROJECT_ID, STAGING_BUCKET
Run the pipeline job on Vertex AI
Now that we have created our dictionary of values, we can create a PipelineJob. This just means that the RLHF pipeline will execute on Vertex AI. So it’s not running locally here in the notebook, but on some server on Google Cloud.
import google.cloud.aiplatform as aiplatform
aiplatform.init(project = PROJECT_ID,
location = REGION,
credentials = credentials)# Look at the path for the YAML file
RLHF_PIPELINE_PKG_PATH # 'rlhf_pipeline.yaml'
Create and run the pipeline job
- Here is how you would create the pipeline job and run it if you were working on your own project.
- This job takes about a full day to run with multiple accelerators (TPUs/GPUs), and so we’re not going to run it in this classroom.
- To create the pipeline job:
job = aiplatform.PipelineJob(
display_name="tutorial-rlhf-tuning",
pipeline_root=STAGING_BUCKET,
template_path=RLHF_PIPELINE_PKG_PATH,
parameter_values=parameter_values)
- To run the pipeline job:
job.run()
- The content team has run this RLHF training pipeline to tune the Llama-2 model, and in the next lesson, you’ll get to evaluate the log data to compare the performance of the tuned model with the original foundational model.
Lesson 4: Evaluate the Tuned Model
Project environment setup
- Install Tensorboard (if running locally)
!pip install tensorboard
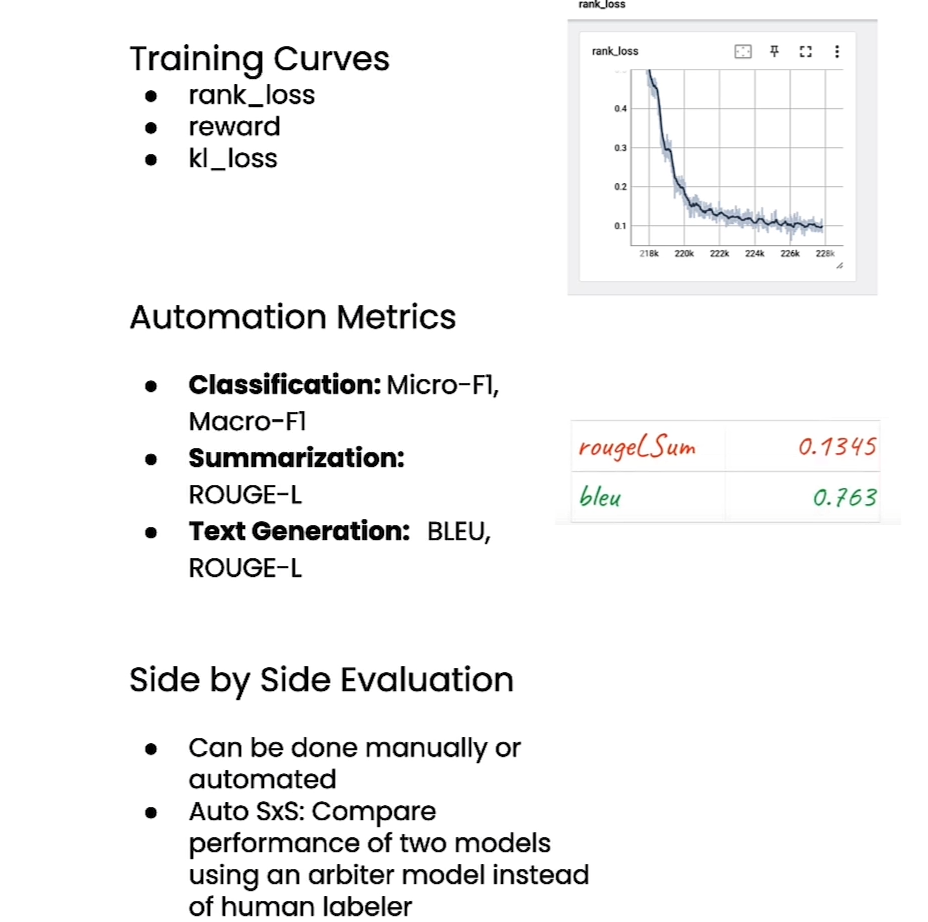
ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence)是用于评估自动生成的摘要与参考摘要之间相似程度的一种指标。它是 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)指标家族的一部分,旨在衡量自动生成的文本与参考文本之间的重叠程度。
ROUGE-L 的计算基于最长公共子序列(LCS)的概念。它测量了自动生成的文本和参考文本中最长公共子序列的长度,然后将其归一化为参考摘要的长度。因此,ROUGE-L 越高,表示自动生成的文本与参考摘要的匹配程度越高。
ROUGE-L 的计算方式使其更加偏向于考虑内容的一致性,而不是简单地匹配重复的词语或短语。因此,它通常被用于评估自动生成的摘要在保留原文核心信息的同时,也具有一定的连贯性和完整性。
ROUGE-L 在自然语言处理领域的自动摘要、机器翻译等任务中经常被用作评估指标,以评估生成的文本与人工参考文本之间的相似性。
Explore results with Tensorboard
%load_ext tensorboard
port =%env PORT1
%tensorboard --logdir reward-logs --port $port --bind_all
# Look at what this directory has%ls reward-logs
port =%env PORT2
%tensorboard --logdir reinforcer-logs --port $port --bind_all
port =%env PORT3
%tensorboard --logdir reinforcer-fulldata-logs --port $port --bind_all
- The dictionary of ‘parameter_values’ defined in the previous lesson
parameter_values={"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/summarize_from_feedback_tfds/comparisons/train/*.jsonl","prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/train/*.jsonl","eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text_small/reddit_tfds/val/*.jsonl","large_model_reference":"llama-2-7b","reward_model_train_steps":1410,"reinforcement_learning_train_steps":320,"reward_model_learning_rate_multiplier":1.0,"reinforcement_learning_rate_multiplier":1.0,"kl_coeff":0.1,"instruction":\
"Summarize in less than 50 words"}
Note: Here, we are using “text_small” for our datasets for learning purposes. However for the results that we’re evaluating in this lesson, the team used the full dataset with the following hyperparameters:
parameter_values={
"preference_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/summarize_from_feedback_tfds/comparisons/train/*.jsonl",
"prompt_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/train/*.jsonl",
"eval_dataset": \
"gs://vertex-ai/generative-ai/rlhf/text/reddit_tfds/val/*.jsonl",
"large_model_reference": "llama-2-7b",
"reward_model_train_steps": 10000,
"reinforcement_learning_train_steps": 10000,
"reward_model_learning_rate_multiplier": 1.0,
"reinforcement_learning_rate_multiplier": 0.2,
"kl_coeff": 0.1,
"instruction":\
"Summarize in less than 50 words"}
Evaluate using the tuned and untuned model
用tuned model产生的结果:
import json
eval_tuned_path ='eval_results_tuned.jsonl'
eval_data_tuned =[]withopen(eval_tuned_path)as f:for line in f:
eval_data_tuned.append(json.loads(line))# Import for printing purposesfrom utils import print_d
# Look at the result produced by the tuned model
print_d(eval_data_tuned[0])
eval_results_tuned.jsonl文件内容如下:
{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nBefore anything, not a sad story or anything. My country's equivalent to Valentine's Day is coming and I had this pretty simple idea to surprise my girlfriend and it would involve giving her some roses. The thing is, although I know she would appreciate my intention in and of itself, I don't know if she would like the actual flowers and such, so I wanted to find out if she likes roses and if she would like getting some, but without her realizing it so as not to spoil the surprise. Any ideas on how to get that information out of her? [summary]: ","targets_pretokenized":""},"prediction":"My country's equivalent to Valentine's Day is coming. Want to surprise my girlfriend with roses but don't know if she would like getting some. Any ideas on how to get that information out of her without spoiling the surprise"}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nFor most of high school, I've been the go to \"computer kid.\" I'll be the first to admit that I know a lot about how computers work, and often fix things for teachers before the IT guys have a chance to get a whack at them. I worked at a computer repair shop for half a year as a technician. I've done the typical tech guy thing and drooled over new computers that come out (read: Wired/PopSci/2600 articles and centerfolds). \n\nThat said, I have NO IDEA what kind of computer to get for college. I've always wanted to buy a ton of parts and build my own \"super\" desktop, but I for sure need a laptop. If everything goes according to plan, I'm enrolling at Champlain College next Fall to double major in Computer Network Information Security and Digital Forensics. \n\nA lot of you probably already know this, but this major involves a lot of virtual desktops. Essentially I set up entire networks on my own rig and then go in and play around with them, all from one computer. It takes a lot of processing power and hard drive space.\n\nOver the years I've built up several stereotypes about different brands, operating systems, products... Recently, my mind has been opened back up and I'm willing to take a look at anything, even a Dell or an Asus.\n\nIt's recently been brought to my attention that Macs are actually pretty good. I've always been a notorious Windows-only-guy. I finally decided to bite my tongue and take a look under the hood, and my god are these things powerful... I guess it really does help making everything but the processor in-house.\n\nAnywho, what I really need is suggestions that might work well for my major, hopefully staying under a budget of $1600. Also, what are the big differences between a MacBook and MacBook Pro? [summary]: ","targets_pretokenized":""},"prediction":"Been the go to \"computer kid\" in high school. Majoring in Computer Network Information Security and Digital Forensics. Need suggestions for a laptop under 1600. What are the big differences between a MacBook and MacBook Pro"}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nSo I graduated in may 2014 in the DC area but couldn't start applying to jobs till April of this year due to family circumstances. So far I've applied to nearly 50+ places, 4 recruiters contacted me and added me to their available candidates list after a small interview (one of them got me a small office assignment but that's over) and gotten two interviews by myself (none of which panned out). I have experience in office software and am pretty well versed in excel (i'd say a little less than advanced but a lot more than proficient) and advanced mathematics. I have a GPA higher than 3 but lower than 3.5 which I don't mention in my resume. Could that be it? \n\nI don't understand what I'm doing wrong. So far I've been applying to anything remotely related with data, analysis, finance at entry level but I barely get any response. Data entry and admin assistant positions are no different. I also write cover letters for almost every place. I also don't know many people here since my family isn't really well connected enough for me to have great networking opportunities. I really don't know what to do next. I can't imagine how people applying to over 200-400 places deal with the frustrating and emotionally draining experience. I would really appreciate some advice from recent econ/finance grads or hiring personnel. [summary]: ","targets_pretokenized":""},"prediction":"Graduated in may 2014. Applied to nearly 50+ places for data, analysis finance entry level. Barely get any response. Don't know what to do next. Would appreciate advice from recent econ/finance grads or hiring personnel."}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nHello /r/jobs, I graduated a few months ago and had no luck so far to get a job in marketing/sales. \n\nThere's a small local company (perhaps 30 employees) but they are actually pretty successful in what they're doing (known worldwide). I checked their website and it's awful. Looks like a website from the early 2000's. So I guess they are not pretty good in (online-)marketing. \n\nI would like to do a cold application (not sure if they are looking for a marketing guy) but I had no luck with this kind of application in the past. That's why I thought I try something different. I have good skills in photoshop, indesign and illustrator. As a teenager I also built websites using HTML, so I thought I build a dummy website fitted to their company and attach some screenshots to my application.\n\nWhat do you think? I this a feasible idea or will they be offended?\n\nThank you very much in advance. [summary]: ","targets_pretokenized":""},"prediction":"Graduated a few months ago. No luck so far to get a job in marketing/sales. Thought to build a dummy website fitted to the company and attach some screenshots to my application. What do you think?"}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nHello!\n\nI hope that someone can lend me some advice for a situation that I find myself in. Here's my situation:\n\nAbout 10 years ago as I was traveling, I applied for my first credit card which was an AMEX delta card. For the years after, I traveled often, and got benefits from this card.\n\nNow, after I have recently graduated college, and landed a full time job, I no longer have time to travel as much, and therefore have no need to use the Delta card. Last year I paid off my balance with the card, and haven't used it since.\n\nRecently, I had to pay the $95 annual fee, and realized that I should perhaps consider another credit card. I thought about closing this account and applying for a cash rewards card.\n\nNow my issue is that this is my ONLY and OLDEST credit card account. I would like to close the account and apply for a Bank of America cash rewards card as my checking/savings accounts are with them. However, I am concerned with how this will affect my credit report.\n\nWill closing this account greatly affect my credit score?\n\nI even spoke with the reps at AMEX about downgrading to a cash rewards card with no annual fee, and apparently I cannot do this as my AMEX card is linked with the Delta account. I do not want this card, I'm stuck in a pickle...\n\nAny advice would be appreciated! [summary]: ","targets_pretokenized":""},"prediction":"About 10 years ago applied for my first credit card AMEX delta card. No longer have time to travel as much. Thinking of closing the account and apply for a cash rewards card. Any advice would be appreciated."}
Output
--------------------------------------------------
key:inputs
val
--------------------------------------------------
key:inputs_pretokenized
val:Summarize in less than 50 words.
Before anything,not a sad story or anything. My country's equivalent to Valentine's Day is coming and I had this pretty simple idea to surprise my girlfriend and it would involve giving her some roses. The thing is, although I know she would appreciate my intention inand of itself, I don't know if she would like the actual flowers and such, so I wanted to find out if she likes roses andif she would like getting some, but without her realizing it so asnot to spoil the surprise. Any ideas on how to get that information out of her? [summary]:--------------------------------------------------
key:targets_pretokenized
val:--------------------------------------------------
key:prediction
val:My country's equivalent to Valentine's Day is coming. Want to surprise my girlfriend with roses but don't know if she would like getting some. Any ideas on how to get that information out of her without spoiling the surprise
用base model产生的结果
eval_untuned_path ='eval_results_untuned.jsonl'
eval_data_untuned =[]withopen(eval_untuned_path)as f:for line in f:
eval_data_untuned.append(json.loads(line))# Look at the result produced by the untuned model
print_d(eval_data_untuned[0])
eval_results_untuned.jsonl文件如下:
{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nBefore anything, not a sad story or anything. My country's equivalent to Valentine's Day is coming and I had this pretty simple idea to surprise my girlfriend and it would involve giving her some roses. The thing is, although I know she would appreciate my intention in and of itself, I don't know if she would like the actual flowers and such, so I wanted to find out if she likes roses and if she would like getting some, but without her realizing it so as not to spoil the surprise. Any ideas on how to get that information out of her? [summary]: ","targets_pretokenized":""},"prediction":"The author wants to surprise his girlfriend with roses on Valentine's Day but he doesn't know if she likes roses. He wants to find out without spoiling the surprise."}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nFor most of high school, I've been the go to \"computer kid.\" I'll be the first to admit that I know a lot about how computers work, and often fix things for teachers before the IT guys have a chance to get a whack at them. I worked at a computer repair shop for half a year as a technician. I've done the typical tech guy thing and drooled over new computers that come out (read: Wired/PopSci/2600 articles and centerfolds). \n\nThat said, I have NO IDEA what kind of computer to get for college. I've always wanted to buy a ton of parts and build my own \"super\" desktop, but I for sure need a laptop. If everything goes according to plan, I'm enrolling at Champlain College next Fall to double major in Computer Network Information Security and Digital Forensics. \n\nA lot of you probably already know this, but this major involves a lot of virtual desktops. Essentially I set up entire networks on my own rig and then go in and play around with them, all from one computer. It takes a lot of processing power and hard drive space.\n\nOver the years I've built up several stereotypes about different brands, operating systems, products... Recently, my mind has been opened back up and I'm willing to take a look at anything, even a Dell or an Asus.\n\nIt's recently been brought to my attention that Macs are actually pretty good. I've always been a notorious Windows-only-guy. I finally decided to bite my tongue and take a look under the hood, and my god are these things powerful... I guess it really does help making everything but the processor in-house.\n\nAnywho, what I really need is suggestions that might work well for my major, hopefully staying under a budget of $1600. Also, what are the big differences between a MacBook and MacBook Pro? [summary]: ","targets_pretokenized":""},"prediction":"A high school senior who is going to major in Computer Network Information Security and Digital Forensics needs a laptop that is powerful enough to run virtual desktops. He is open to suggestions of any brands, but prefers Macs. He is looking for a laptop under $1600 and wants to know the difference between MacBook and"}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nSo I graduated in may 2014 in the DC area but couldn't start applying to jobs till April of this year due to family circumstances. So far I've applied to nearly 50+ places, 4 recruiters contacted me and added me to their available candidates list after a small interview (one of them got me a small office assignment but that's over) and gotten two interviews by myself (none of which panned out). I have experience in office software and am pretty well versed in excel (i'd say a little less than advanced but a lot more than proficient) and advanced mathematics. I have a GPA higher than 3 but lower than 3.5 which I don't mention in my resume. Could that be it? \n\nI don't understand what I'm doing wrong. So far I've been applying to anything remotely related with data, analysis, finance at entry level but I barely get any response. Data entry and admin assistant positions are no different. I also write cover letters for almost every place. I also don't know many people here since my family isn't really well connected enough for me to have great networking opportunities. I really don't know what to do next. I can't imagine how people applying to over 200-400 places deal with the frustrating and emotionally draining experience. I would really appreciate some advice from recent econ/finance grads or hiring personnel. [summary]: ","targets_pretokenized":""},"prediction":"Graduated in May 2014, but couldn't start applying to jobs till April of this year. Applied to nearly 50 places, but only got 2 interviews. GPA is higher than 3 but lower than 3.5. Don't know what I'm doing wrong."}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nHello /r/jobs, I graduated a few months ago and had no luck so far to get a job in marketing/sales. \n\nThere's a small local company (perhaps 30 employees) but they are actually pretty successful in what they're doing (known worldwide). I checked their website and it's awful. Looks like a website from the early 2000's. So I guess they are not pretty good in (online-)marketing. \n\nI would like to do a cold application (not sure if they are looking for a marketing guy) but I had no luck with this kind of application in the past. That's why I thought I try something different. I have good skills in photoshop, indesign and illustrator. As a teenager I also built websites using HTML, so I thought I build a dummy website fitted to their company and attach some screenshots to my application.\n\nWhat do you think? I this a feasible idea or will they be offended?\n\nThank you very much in advance. [summary]: ","targets_pretokenized":""},"prediction":"Graduated a few months ago, looking for a job in marketing/sales. Found a small local company that is successful but has an awful website. I want to apply for a marketing job but not sure if they are hiring. I thought of building a dummy website for them and attach some screenshots to my application."}{"inputs":{"inputs_pretokenized":"Summarize in less than 50 words.\n\n\nHello!\n\nI hope that someone can lend me some advice for a situation that I find myself in. Here's my situation:\n\nAbout 10 years ago as I was traveling, I applied for my first credit card which was an AMEX delta card. For the years after, I traveled often, and got benefits from this card.\n\nNow, after I have recently graduated college, and landed a full time job, I no longer have time to travel as much, and therefore have no need to use the Delta card. Last year I paid off my balance with the card, and haven't used it since.\n\nRecently, I had to pay the $95 annual fee, and realized that I should perhaps consider another credit card. I thought about closing this account and applying for a cash rewards card.\n\nNow my issue is that this is my ONLY and OLDEST credit card account. I would like to close the account and apply for a Bank of America cash rewards card as my checking/savings accounts are with them. However, I am concerned with how this will affect my credit report.\n\nWill closing this account greatly affect my credit score?\n\nI even spoke with the reps at AMEX about downgrading to a cash rewards card with no annual fee, and apparently I cannot do this as my AMEX card is linked with the Delta account. I do not want this card, I'm stuck in a pickle...\n\nAny advice would be appreciated! [summary]: ","targets_pretokenized":""},"prediction":"The author has an AMEX delta card which has an annual fee. The author wants to close the account and apply for a cash rewards card. However, the author is concerned about how this will affect their credit score."}
Output
key:inputs
val
--------------------------------------------------
key:inputs_pretokenized
val:Summarize in less than 50 words.
Before anything,not a sad story or anything. My country's equivalent to Valentine's Day is coming and I had this pretty simple idea to surprise my girlfriend and it would involve giving her some roses. The thing is, although I know she would appreciate my intention inand of itself, I don't know if she would like the actual flowers and such, so I wanted to find out if she likes roses andif she would like getting some, but without her realizing it so asnot to spoil the surprise. Any ideas on how to get that information out of her? [summary]:--------------------------------------------------
key:targets_pretokenized
val:--------------------------------------------------
key:prediction
val:The author wants to surprise his girlfriend with roses on Valentine's Day but he doesn't know if she likes roses. He wants to find out without spoiling the surprise.
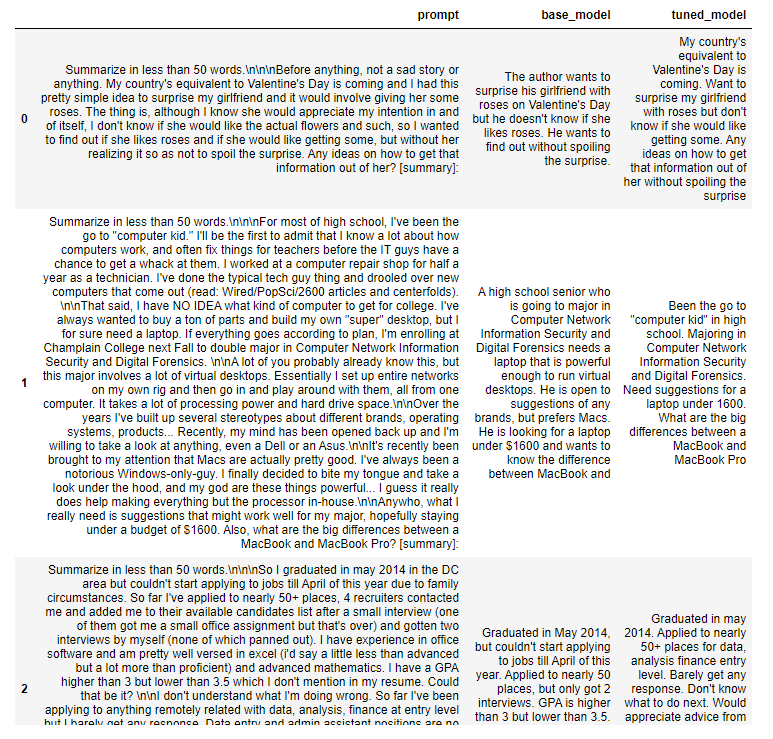
Explore the results side by side in a dataframe
# Extract all the prompts
prompts =[sample['inputs']['inputs_pretokenized']for sample in eval_data_tuned]# Completions from the untuned model
untuned_completions =[sample['prediction']for sample in eval_data_untuned]# Completions from the tuned model
tuned_completions =[sample['prediction']for sample in eval_data_tuned]
- Now putting all together in one big dataframe
import pandas as pd
results = pd.DataFrame(
data={'prompt': prompts,'base_model':untuned_completions,'tuned_model': tuned_completions})
pd.set_option('display.max_colwidth',None)# Print the results
results
Output
如果对RLHF感兴趣,可以参看:

End
2024年3月2日开始学习这门short course,花费2个小时结课。对整个基于人类反馈的强化学习中实际代码的编写有了一定认识。希望在阅读RLHF论文的时候的理解更深刻一点。
版权归原作者 阿正的梦工坊 所有, 如有侵权,请联系我们删除。