
强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体因采取行动导致预期结果而获得奖励,因采取行动导致预期结果而受到惩罚。随着时间的推移,代理学会采取行动,使其预期回报最大化。
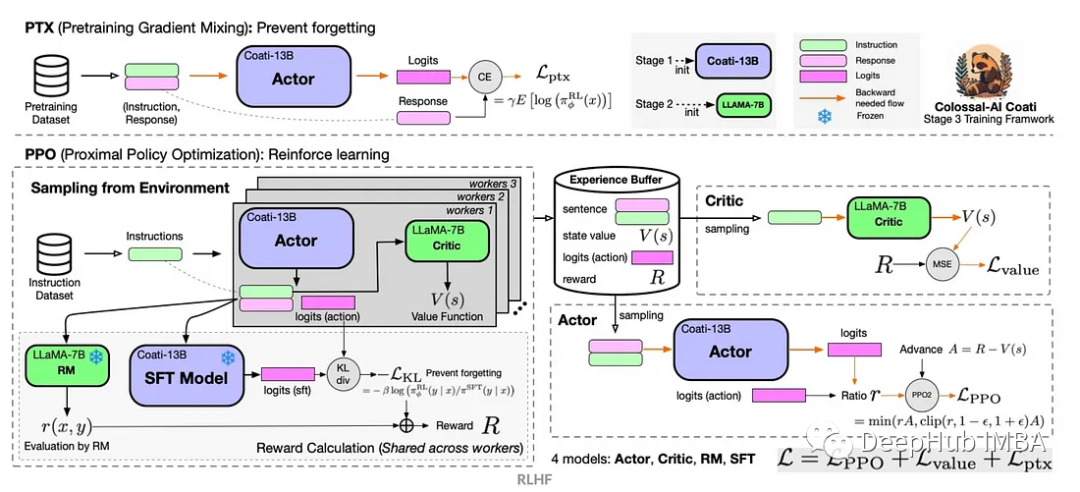
RL代理通常使用马尔可夫决策过程(MDP)进行训练,马尔可夫决策过程是为顺序决策问题建模的数学框架。MDP由四个部分组成:
状态:环境的可能状态的集合。
动作:代理可以采取的一组动作。
转换函数:在给定当前状态和动作的情况下,预测转换到新状态的概率的函数。
奖励函数:为每次转换分配奖励给代理的函数。
代理的目标是学习策略函数,将状态映射到动作。通过策略函数来最大化代理随着时间的预期回报。
Deep Q-learning是一种使用深度神经网络学习策略函数的强化学习算法。深度神经网络将当前状态作为输入,并输出一个值向量,每个值代表一个可能的动作。然后代理采取具有最高值的操作。
Deep Q-learning是一种基于值的强化学习算法,这意味着它学习每个状态-动作对的值。状态-动作对的值是agent在该状态下采取该动作所获得的预期奖励。
Actor-Critic是一种结合了基于值和基于策略的RL算法。有两个组成部分:
Actor:参与者负责选择操作。
Critic:负责评价Actor的行为。
Actor和Critic同时接受训练。Actor被训练去最大化预期奖励,Critic被训练去准确地预测每个状态-动作对的预期奖励。
Actor-Critic算法与其他RL算法相比有几个优点。首先它更稳定,这意味着在训练过程中不太可能出现偏差。其次它更有效率,这意味着它可以更快地学习。第三它更具可扩展性,这意味着它可以应用于具有大型状态和操作空间的问题。
下面的表格总结了Deep Q-learning和Actor-Critic之间的主要区别:

Actor-Critic (A2C)的优势
Actor-Critic是一种流行的强化学习架构,它结合了基于策略和基于价值的方法。它有几个优点,使其成为解决各种强化学习任务的强大选择:
1、低方差
与传统的策略梯度方法相比,A2C 在训练期间通常具有更低的方差。这是因为 A2C 同时使用了策略梯度和值函数,通过值函数来减小梯度的方差。低方差意味着训练过程更加稳定,能够更快地收敛到较好的策略。
2、更快的学习速度
由于低方差的特性,A2C 通常能够以更快的速度学习到一个良好的策略。这对于那些需要进行大量模拟的任务来说尤为重要,因为较快的学习速度可以节省宝贵的时间和计算资源。
3、结合策略和值函数
A2C 的一个显著特点是它同时学习策略和值函数。这种结合使得代理能够更好地理解环境和动作的关联,从而更好地指导策略改进。值函数的存在还有助于减小策略优化中的误差,提高训练的效率。
4、支持连续和离散动作空间
A2C 可以轻松适应不同类型的动作空间,包括连续和离散动作。这种通用性使得 A2C 成为一个广泛适用的强化学习算法,可以应用于各种任务,从机器人控制到游戏玩法优化。
5、并行训练
A2C 可以轻松地并行化,充分利用多核处理器和分布式计算资源。这意味着可以在更短的时间内收集更多的经验数据,从而提高训练效率。
虽然Actor-Critic方法提供了一些优势,但它们也有自己的挑战,例如超参数调优和训练中的潜在不稳定性。但是通过适当的调整和经验回放和目标网络等技术,这些挑战可以在很大程度上得到缓解,使Actor-Critic成为强化学习中有价值的方法。
panda-gym
panda-gym 基于 PyBullet 引擎开发,围绕 panda 机械臂封装了 reach、push、slide、pick&place、stack、flip 等 6 个任务,主要也是受 OpenAI Fetch 启发。
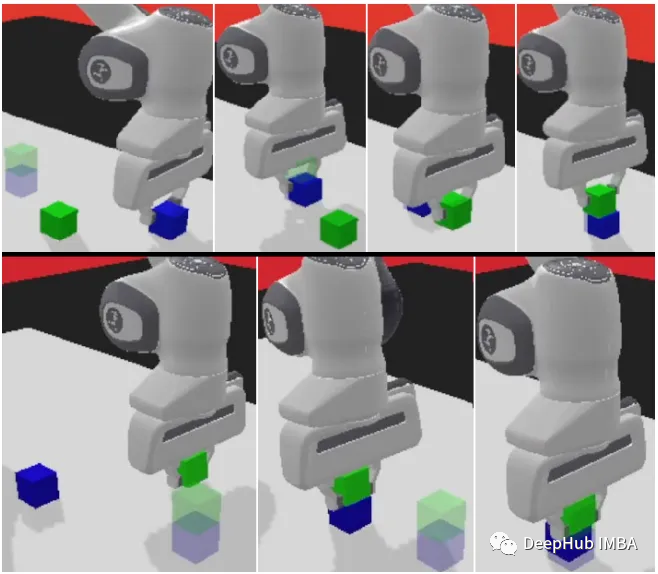
我们下面的代码将使用panda-gym作为示例
1、安装库
代码首先初始化强化学习环境:
!apt-get install -y \
libgl1-mesa-dev \
libgl1-mesa-glx \
libglew-dev \
xvfb \
libosmesa6-dev \
software-properties-common \
patchelf
!pip install \
free-mujoco-py \
pytorch-lightning \
optuna \
pyvirtualdisplay \
PyOpenGL \
PyOpenGL-accelerate\
stable-baselines3[extra] \
gymnasium \
huggingface_sb3 \
huggingface_hub \
panda_gym
2、导入库
import os
import gymnasium as gym
import panda_gym
from huggingface_sb3 import load_from_hub, package_to_hub
from stable_baselines3 import A2C
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
from stable_baselines3.common.env_util import make_vec_env
3、创建运行环境
env_id = "PandaReachDense-v3"
# Create the env
env = gym.make(env_id)
# Get the state space and action space
s_size = env.observation_space.shape
a_size = env.action_space
print("\n _____ACTION SPACE_____ \n")
print("The Action Space is: ", a_size)
print("Action Space Sample", env.action_space.sample()) # Take a random action
4、观察和奖励的规范化
强化学习优化的一个好方法是对输入特征进行归一化。我们通过包装器计算输入特征的运行平均值和标准偏差。同时还通过添加norm_reward = True来规范化奖励
env = make_vec_env(env_id, n_envs=4)
env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
5、创建A2C模型
我们使用Stable-Baselines3团队训练过的官方代理
model = A2C(policy = "MultiInputPolicy",
env = env,
verbose=1)
6、训练A2C
model.learn(1_000_000)
# Save the model and VecNormalize statistics when saving the agent
model.save("a2c-PandaReachDense-v3")
env.save("vec_normalize.pkl")
7、评估代理
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# We need to override the render_mode
eval_env.render_mode = "rgb_array"
# do not update them at test time
eval_env.training = False
# reward normalization is not needed at test time
eval_env.norm_reward = False
# Load the agent
model = A2C.load("a2c-PandaReachDense-v3")
mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
最后我们看看训练的可视化
总结
在“panda-gym”将Panda机械臂和GYM环境有效的结合使得我们可以轻松的在本地进行机械臂的强化学习,
Actor-Critic架构中代理会学会在每个时间步骤中进行渐进式改进,这与稀疏的奖励函数形成对比(在稀疏的奖励函数中结果是二元的),这使得Actor-Critic方法特别适合于此类任务。
通过将策略学习和值估计无缝结合,代理能够熟练地操纵机械臂末端执行器到达指定的目标位置。这不仅为机器人控制等任务提供了实用的解决方案,而且还具有改变各种需要敏捷和明智决策的领域的潜力。
作者:Ankush k Singal