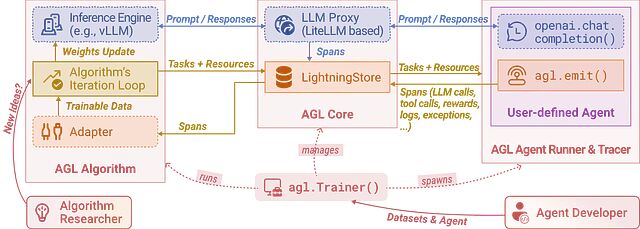
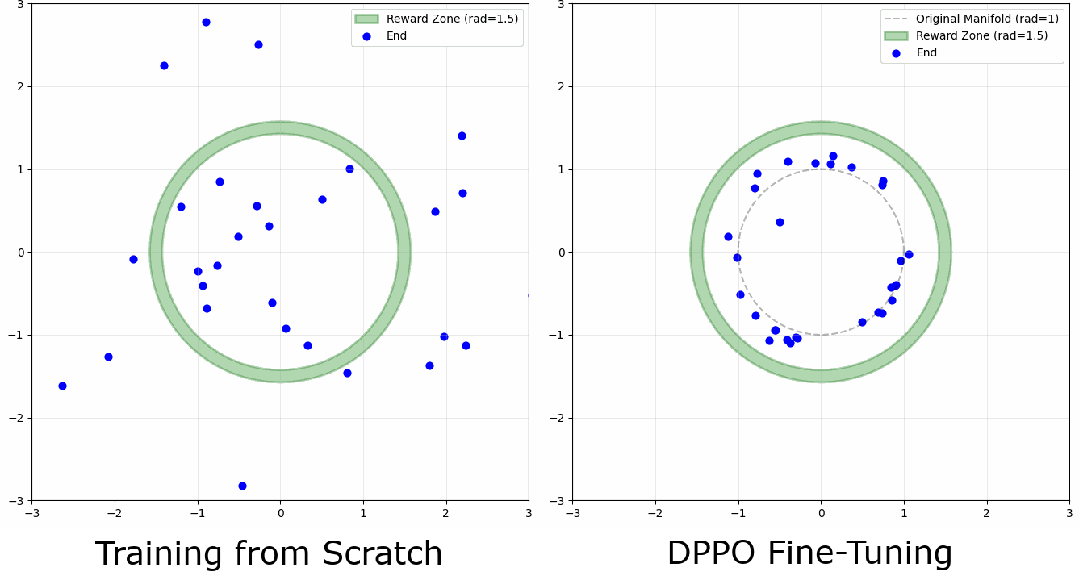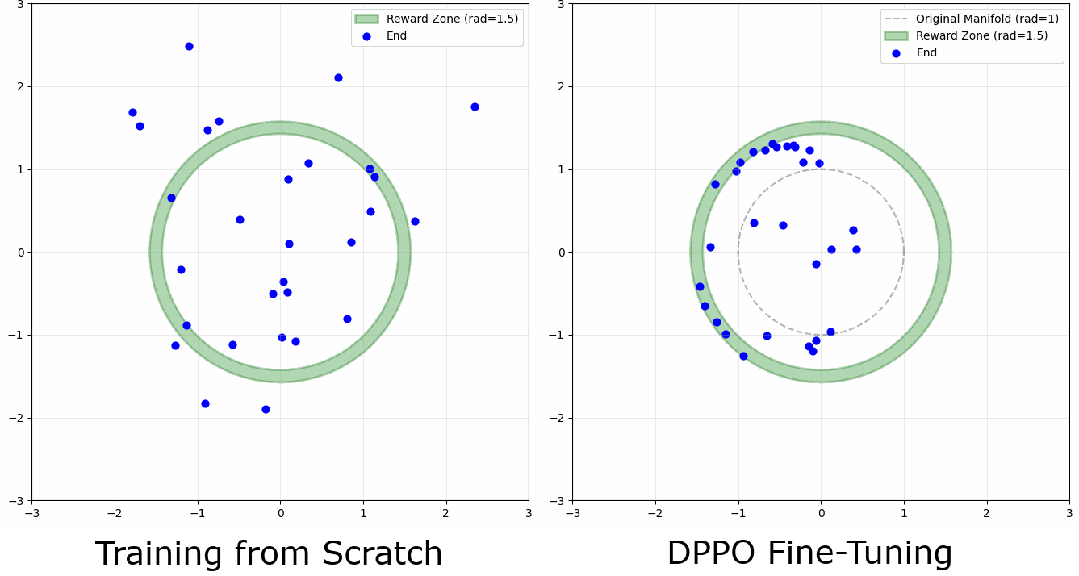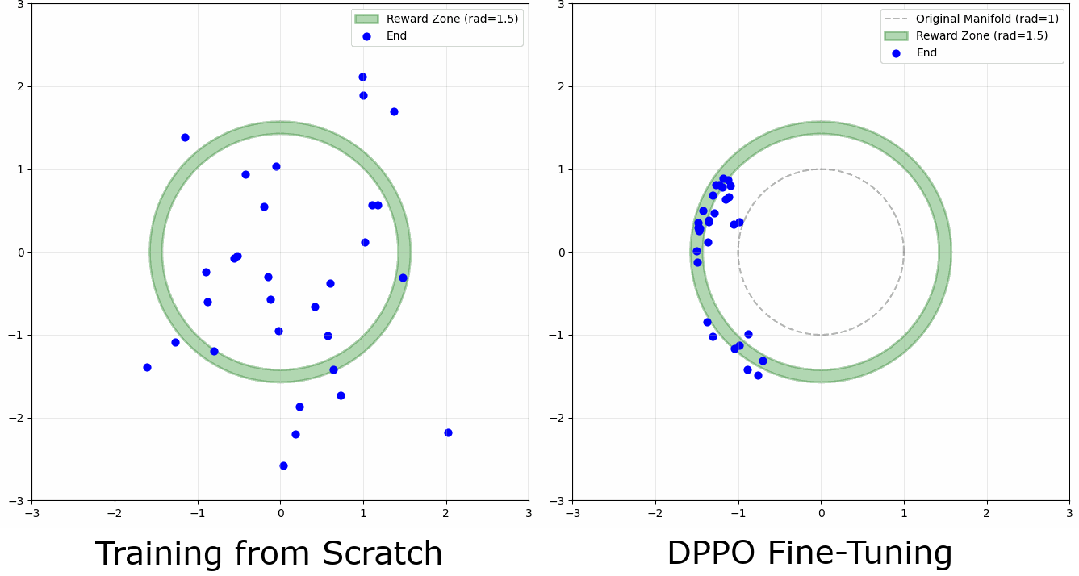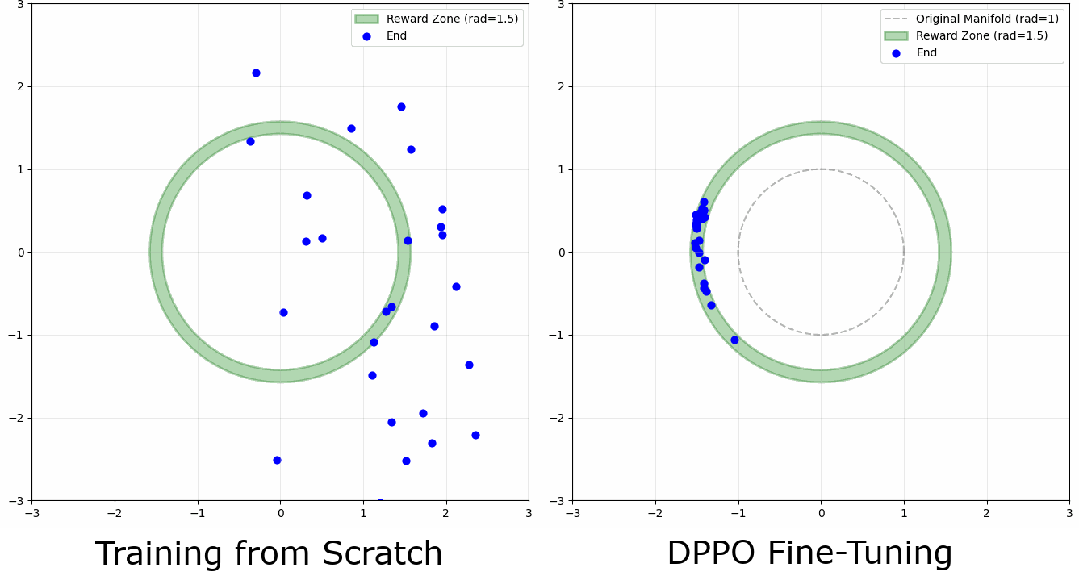
一分钟训练搞懂 DPPO:把扩散过程建模为 MDP 的强化学习方法
这篇文章解释了如何为单步环境中的扩散模型实现 DPPO,希望能提供一个比典型机器人环境更容易理解训练动态的平台。
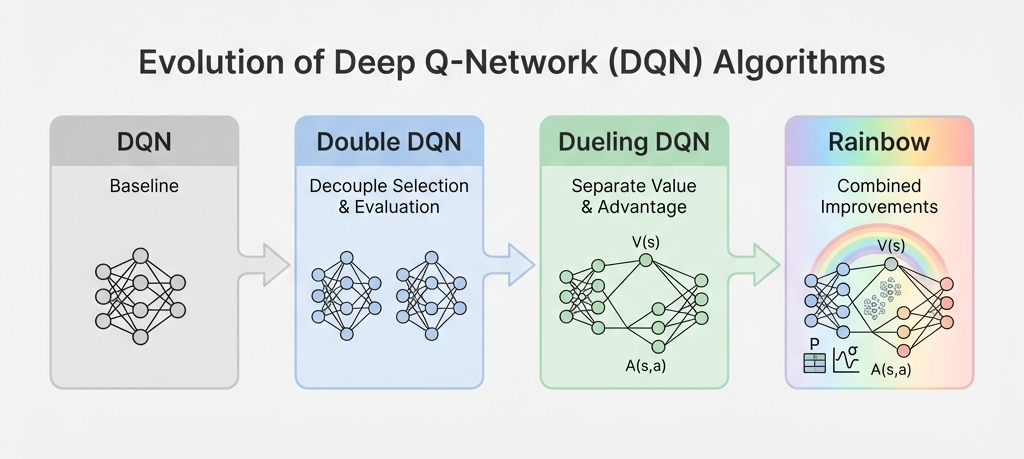
让 Q 值估计更准确:从 DQN 到 Double DQN 的改进方案
这篇文章要内容包括:DQN 为什么会过估计、Double DQN 怎么把动作选择和评估拆开、Dueling DQN 怎么分离状态值和动作优势、优先经验回放如何让采样更聪明,

多智能体强化学习(MARL)核心概念与算法概览
单智能体 RL 适合系统只有一个"大脑"的情况,而MARL 则出现在世界有多个"大脑"的时候。

BipedalWalker实战:SAC算法如何让机器人学会稳定行走
这篇文章用Soft Actor-Critic(SAC)算法解决BipedalWalker-v3环境。但这不只是跑个游戏demo那么简单,更重要的是从生物工程视角解读整个问题:把神经网络对应到神经系统,把奖励函数对应到代谢效率。
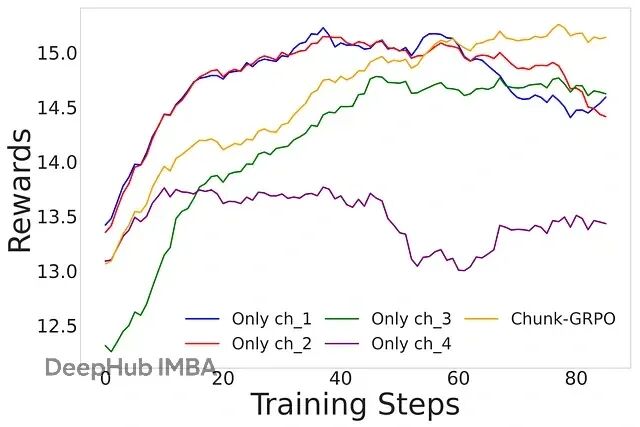
解决GRPO优势归因错误,Chunk-GRPO让文生图模型更懂"节奏"
Chunk-GRPO的解决办法是把连续时间步分组成"块",把这些块作为整体单元来优化,让训练信号更平滑,过程更稳定。
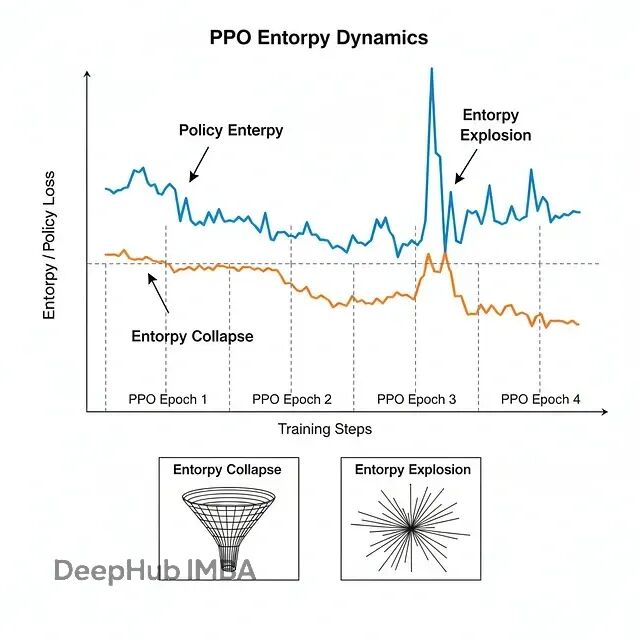
大模型强化学习的熵控制:CE-GPPO、EPO与AsyPPO技术方案对比详解
三篇新论文给出了不同角度的解法:CE-GPPO、EPO和AsyPPO。虽然切入点各有不同,但合在一起就能发现它们正在重塑大规模推理模型的训练方法论。下面详细说说这三个工作到底做了什么。
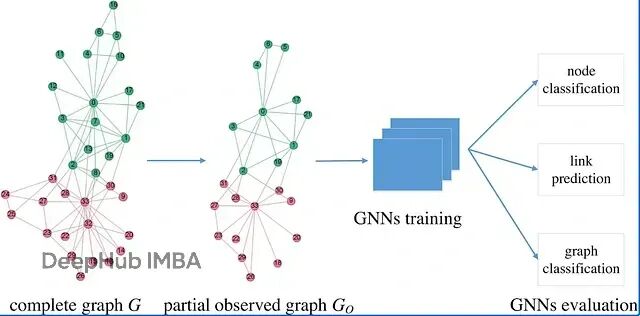
打造自主学习的AI Agent:强化学习+LangGraph代码示例
本文会从RL的数学基础讲起,然后深入到知识图谱的多跳推理,最后在LangGraph框架里搭建一个RL驱动的智能系统。
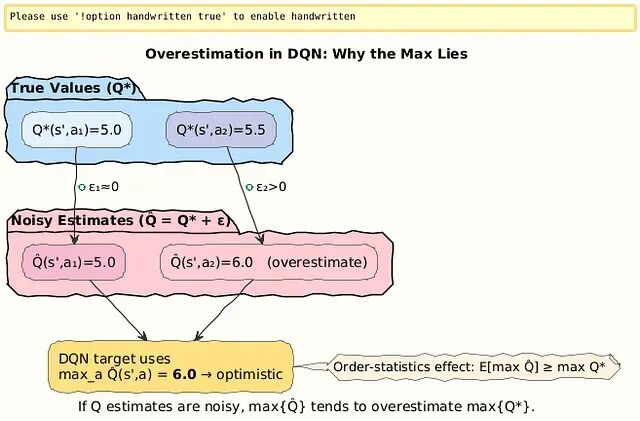
从DQN到Double DQN:分离动作选择与价值评估,解决强化学习中的Q值过估计问题
DQN的过估计源于max操作符偏好噪声中的高值。Double DQN把动作选择(在线网络θ)和价值评估(目标网络θ^−)分开处理,
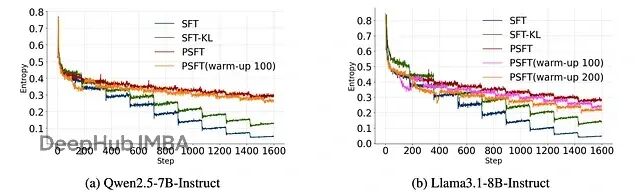
Proximal SFT:用PPO强化学习机制优化SFT,让大模型训练更稳定
这篇论文提出了 Proximal Supervised Fine-Tuning (PSFT),本质上是把 PPO 的思路引入到 SFT 中。这个想法挺巧妙的:既然 PPO 能够稳定策略更新,那为什么不用类似的机制来稳定监督学习的参数更新呢?
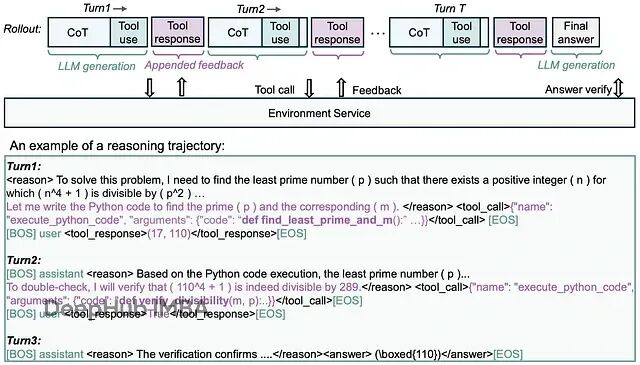
微软rStar2-Agent:新的GRPO-RoC算法让14B模型在复杂推理时超越了前沿大模型
Microsoft Research最近发布的rStar2-Agent展示了一个令人瞩目的结果:一个仅有14B参数的模型在AIME24数学基准测试上达到了80.6%的准确率,超越了671B参数的DeepSeek-R1(79.8%)。
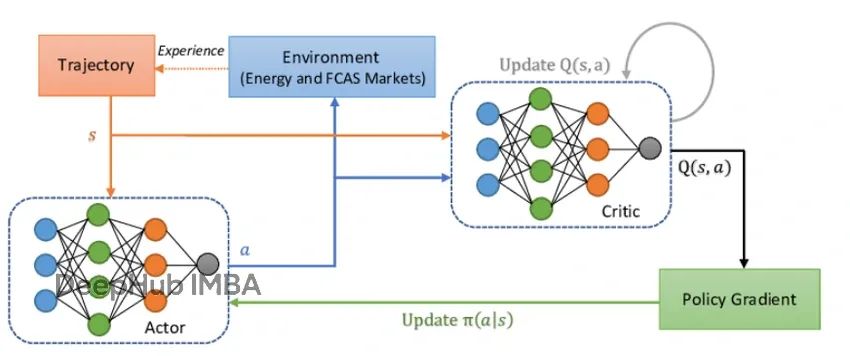
近端策略优化算法PPO的核心概念和PyTorch实现详解
本文提供了PPO算法的完整PyTorch实现方案,涵盖了从理论基础到实际应用的全流程。
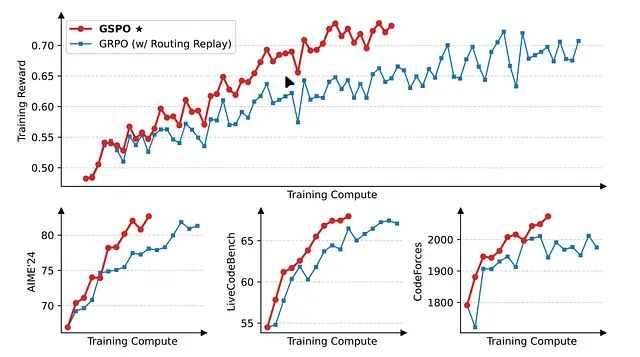
GSPO:Qwen让大模型强化学习训练告别崩溃,解决序列级强化学习中的稳定性问题
这是7月份的一篇论文,Qwen团队提出的群组序列策略优化算法及其在大规模语言模型强化学习训练中的技术突破
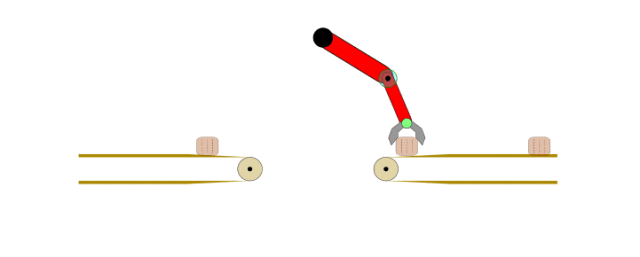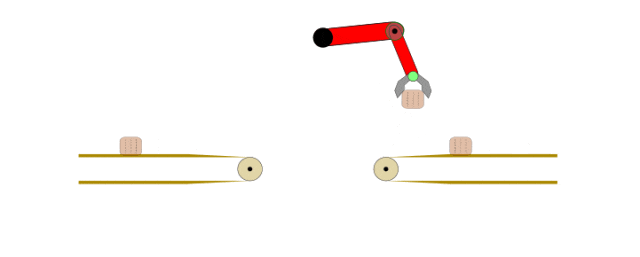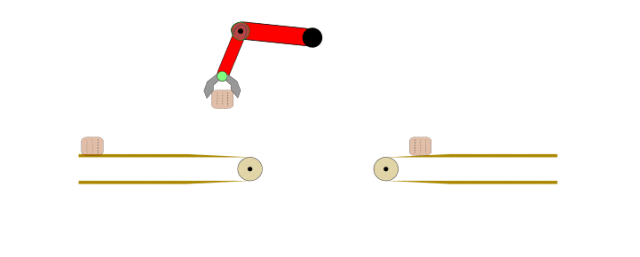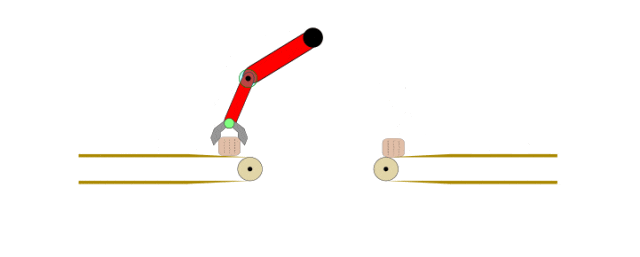
最大熵逆强化学习:理论基础、数学推导与工程实现
本文重点讨论逆强化学习(Inverse Reinforcement Learning, IRL),这是模仿学习的重要分支,其核心目标是基于演示数据学习能够最大化期望奖励的最优策略。
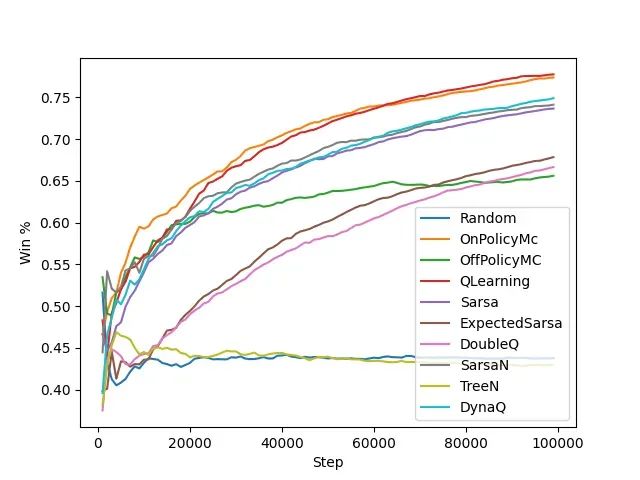
强化学习算法基准测试:6种算法在多智能体环境中的表现实测
本文构建了多智能体强化学习的系统性评估框架,选择井字棋和连珠四子这两个具有代表性的双人博弈游戏作为基准测试环境。通过引入模型动物园策略和自我对战机制,研究探索了各种表格方法在动态对抗环境中的学习能力和收敛特性。
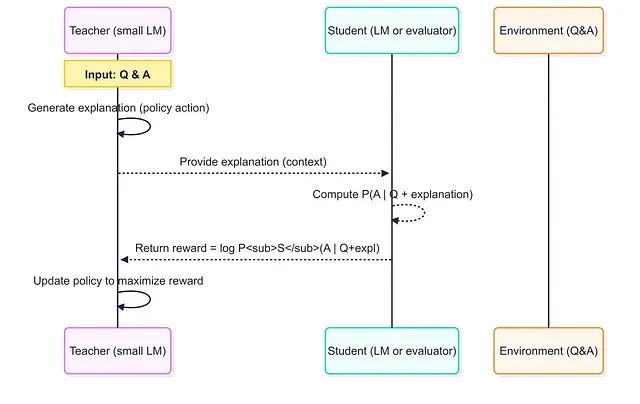
小模型当老师效果更好:借助RLTs方法7B参数击败671B,训练成本暴降99%
强化学习教师模型代表了训练推理语言模型的范式转变。通过从答案开始并专注于解释生成,RLT将训练过程转化为师生协作游戏,实现多方共赢:教师学会有效教学,学生从定制化课程中受益,工程师获得性能更好且成本更低的模型解决方案。
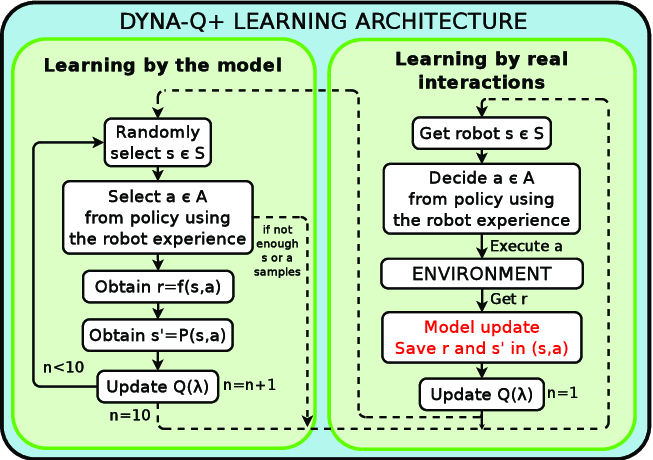
基于Dyna-Q强化学习的智能营销系统:融合贝叶斯生存模型与Transformer注意力机制的电商客户重参与策略优化
本文提出了一个集成三种核心技术的下一代智能优惠券分发系统:基于贝叶斯生存模型的重购概率预测、采用注意力机制的Transformer利润预测模型,以及用于策略持续优化的Dyna-Q强化学习代理。

ProRL:基于长期强化学习让1.5B小模型推理能力超越7B大模型
这个研究挑战了强化学习仅能放大现有模型输出能力的传统观点,通过实验证明长期强化学习训练(ProRL)能够使基础模型发现全新的推理策略。
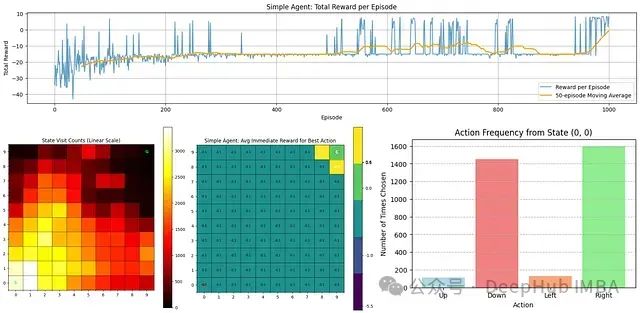
18个常用的强化学习算法整理:从基础方法到高级模型的理论技术与代码实现
本文系统讲解从基本强化学习方法到高级技术(如PPO、A3C、PlaNet等)的实现原理与编码过程,旨在通过理论结合代码的方式,构建对强化学习算法的全面理解。
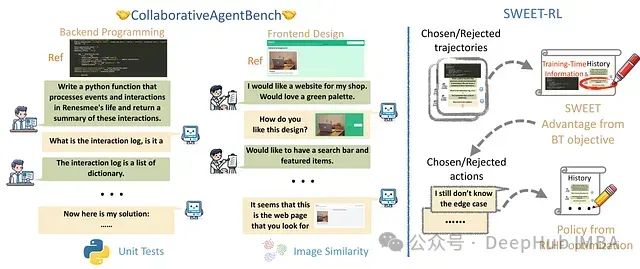
SWEET-RL:基于训练时信息的多轮LLM代理强化学习框架
本文将深入分析SWEET-RL如何改进AI代理在复杂协作任务中的训练方法。



