
参数
iteration
Batch_Size*iteration=一个epoch的数据总量
episode
常用于强化学习,指一个epoch中跑完一个样本
epoch
一个epoch就是跑一遍完整的训练数据。
epoch的次数过多,容易造成过拟合,次数过少,容易使训练的参数达不到最优
根据Replay中数据数量,成比例地修改更新次数。Don't Decay the Learning Rate, Increase the Batch Size. ICLR. 2018 。,经过验证,DRL也适用。
replay_max = 'the maximum capacity of replay buffer'
replay_len = len(ReplayBuffer)
k = 1 + replay_len / replay_max
batch_size = int(k * basic_batch_size)
epoch = int(k * basic_epoch)
Batch_Size
batch_size为GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优
相对于正常数据集,
如果Batch_Size过小,训练数据就会非常难收敛,从而导致欠拟合。
增大Batch_Size,相对处理速度会变快,同时所需内存容量增加。
一般在Batchsize增加的同时,需要对所有样本的训练次数(epoch)增加,以达到最好的结果。
因此需要寻找一个合适的Batchsize值,在模型总体效率和内存容量之间做到最好的平衡。
我在设置BatchSize的时候,首先选择大点的BatchSize把GPU占满,观察Loss收敛的情况,如果不收敛,或者收敛效果不好则降低BatchSize,一般常用16,32,64等。
Experimence Replay Buffer经验回放缓存
对训练影响较大,通常~
,具体多大需要调参
在简单的任务中(训练步数小于1e6),对于探索能力强的DRL算法,通常在缓存被放满前就训练到收敛了,不需要删除任何记忆。
过大的记忆也会拖慢训练速度,我一般会先从默认值 2 ** 17 ~ 2 ** 20 开始尝试,如果环境的随机因素大,我会同步增加记忆容量 与 batch size、网络更新次数,直到逼近服务器的内存、显存上限(放在显存训练更快)
每轮训练结束后需要通过梯度下降更新参数,更新次数为本轮训练的步数。若希望每轮训练结束后,将记忆中的所有数据都被拿出来训练,则:
记忆容量 memories_size = 本轮训练的步数 * batch_size ~= S * batch_size
max_step = S * 10
Reward
- 使用惩罚项可能导致智能体一动不动,因为不动就不会有惩罚。所以有惩罚项的训练过程可能存在搜索不足的问题
- 模型很多时候会找到作弊的手段。Alex举的一个例子是有一个任务需要把红色的乐高积木放到蓝色的乐高积木上面,奖励函数的值基于红色乐高积木底部的高度而定。结果一个模型直接把红色乐高积木翻了一个底朝天。
- 奖励函数的值太过稀疏。换言之大部分情况下奖励函数在一个状态返回的值都是0。这就和我们人学习也需要鼓励,学太久都没什么回报就容易气馁。
- 奖励函数过于复杂,会引入bias
- 结算reward的0.1倍一定要大于日常reward才能避免被稀释。
【dropout、batch normalization】在DL中得到广泛地使用,可惜不适合DRL。
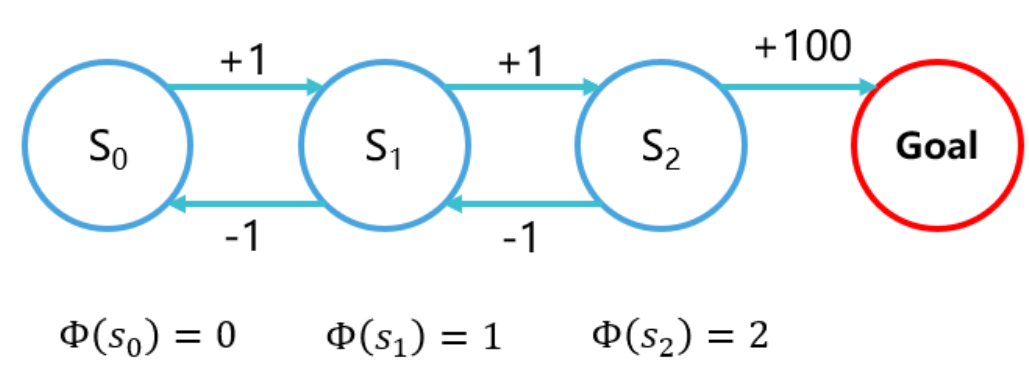
discount factor或gamma折扣因子
希望你的智能体每做出一步,至少需要考虑接下来多少步的reward?
如果我希望考虑接下来的t 步,那么我让第t步的reward占现在这一步的Q值的 0.1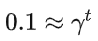
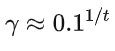 相当于往后考虑100时间步
相当于往后考虑100时间步
gamma绝对不能选择1.0。尽管有时候在入门DRl任务选择gamma=1.0 甚至能训练得更快,但是gamma等于或过于接近1会有“Q值过大”的风险。一般选择0.99,在某些任务上需要调整。详见《Reinforcement Learning An Introduction - Richard S. Sutton》的 Chapter 12 Eligibility Traces。
Agent神经网络
过大、过深的神经网络不适合DRL:
深度学习可以在整个训练结束后再使用训练好的模型。而强化学习需要在几秒钟的训练后马上使用刚训好的模型。这导致DRL只能用比较浅的网络来保证快速拟合(10层以下)
并且强化学习的训练数据不如有监督学习那么稳定,无法划分出训练集测试集去避免过拟合,因此DRL也不能用太宽的网络(超过1024),避免参数过度冗余导致过拟合。
batch normalization批归一化
经过大量实验,DRL绝对不能直接使用批归一化,如果非要用,那么就要修改Batch Normalization的动量项超参数。详见 曾伊言:强化学习需要批归一化(Batch Norm)吗?
dropout随机失活
如果非要用,那么也要选择非常小的 dropout rate(0~0.2),而且要注意在使用的时候关掉dropout。
- 好处:在数据不足的情况下缓解过拟合;像Noisy DQN那样去促进策略网络探索
- 坏处:影响DRL快速拟合的能力;略微增加训练时间
lr(learning rate)学习率/步长
将输出误差反向传播给网络参数,以此来拟合样本的输出。
本质上是最优化的一个过程,逐步趋向于最优解。但是每一次更新参数利用多少误差,就需要lr控制。
学习率越大,输出误差对参数的影响就越大,参数更新的就越快,但同时受到异常数据的影响也就越大,很容易发散。

weight decay权重衰减
可以看出,最理想的学习率不是固定值,而是一个随着训练次数衰减的变化的值,也就是在训练初期,学习率比较大,随着训练的进行,学习率不断减小,直到模型收敛。

在这三种方法中,最常用的是指数衰减,实践证明,它也是最有效的。
(例如:随着迭代轮数的增加学习率自动发生衰减,每过5个epochs将学习率乘以0.9998。)
tensorflow中它的数学表达式为:
decayed_lr = lr0*(decay_rate^(global_steps/decay_steps)
参数解释:
decayed_lr:衰减后的学习率,也就是当前训练不使用的真实学习率
lr0: 初始学习率
decay_rate: 衰减率,每次衰减的比例
global_steps:当前训练步数
decay_steps:衰减步数,每隔多少步衰减一次。
刚开始训练时,学习率以 0.01 ~ 0.001 为宜, 接近训练结束的时候,学习速率的衰减应该在100倍以上。按照这个经验去设置相关参数,对于模型的精度会有很大帮助。
如果是 迁移学习 ,由于模型已在原始数据上收敛,此时应设置较小学习率 () 在新数据上进行 微调 。
离散动作探索策略(以epslion-Greedy为例)
如何选择Q值最大以外的动作:
每次都从 已经被强化学习算法加强过的Q值中,选择Q值最大的那个动作去执行。为了探索,有很小的概率 epslion 随机地执行某个动作。
epslion-Greedy保证了Replay可以收集到足够丰富的训练数据。超参数 执行随机动作的概率 epslion我一般选择 0.1,然后根据任务需要什么程度的探索强度再修改。
如果离散动作很多,我会尽可能选择大一点的 epslion
衰减和退火
在离散动作中,探索衰减表现为逐步减小执行随机动作的概率 在连续动作中,探索衰减表现为逐步减小探索噪声的方差,退火同理。
- 衰减就是单调地减小(固定、不固定,比例、定值 ),直至某个限度后停止。在比较简单的环境里,算法可以在前期加强探索,后期减少探索强度,例如在训练前期使用一个比较大的 epslion,多执行随机动作,收集训练数据;训练中期让epslion逐步减小,可以线性减小 或者 乘以衰减系数,完成平缓过渡;训练后期干脆让epslion变为一个极小的数,以方便收敛。我建议适度地使用探索衰减,能不用尽量不用。(我不建议0,这会降低RelapyBuffer中数据的多样性,加大过拟合风险)
- 退火就是减小后,(缓慢、突然)增大,周期循环。比衰减拥有更多的超参数。我不推荐使用,除非万不得已。
探索衰减一定会有很好的效果,但这种“效果好”建立在人肉搜索出衰减超参数的基础之上。成熟的DRL算法会自己去调整自己的探索强度。比较两者的调参总时间,依然是使用成熟的DRL算法耗时更短。
Sample complexity样本复杂性
对于轨迹(trajectory)来说,采集多少样本合适呢?以Q-learning为例子我们分析,每个epoch收集 m mm 个sample, 通过构造经验结构以及强阿虎学习的值函数,得到值函数为: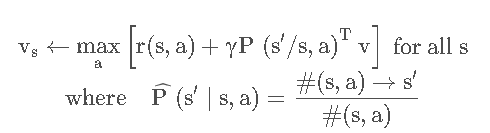
通过先抽样后计算的方式,样本的个数大约为: 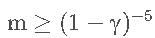
也就是说: 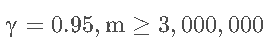
大多数算法还是随着样本增大normalization score也增大
** Deep RL之所以受欢迎,是因为它是机器学习ML中唯一可以用测试集训练的领域。**
强化学习
问题
- 样本利用率非常低。换言之为了让模型的表现达到一定高度需要极为大量的训练样本。
- 最终表现很多时候不够好。在很多任务上用非强化学习甚至非学习的其它方法,如基于模型的控制(model based control),线性二次型调节器(Linear Quadratic Regulator)等等可以获得好得多的表现。最气人的是这些模型很多时候样本利用率还高。
- DRL成功的关键离不开一个好的奖励函数(reward function),然而这种奖励函数往往很难设计。在Deep Reinforcement Learning That Matters作者提到有时候把奖励乘以一个常数模型表现就会有天和地的区别。
- 对环境的过拟合。DRL少有在多个环境上玩得转的。
- 不稳定性。
好用的算法标准
- 没有很多需要调整的超参数。D3QN、SAC超参数较少,且SAC可自行调整超参数 α
- 超参数很容易调整或确定。SAC的 reward scaling 可以在训练前直接推算出来。PPO超参数的细微改变不会极大地影响训练
- 训练快,收敛稳、得分高。
- 图片截取自 Ape-X 与 SAC 论文
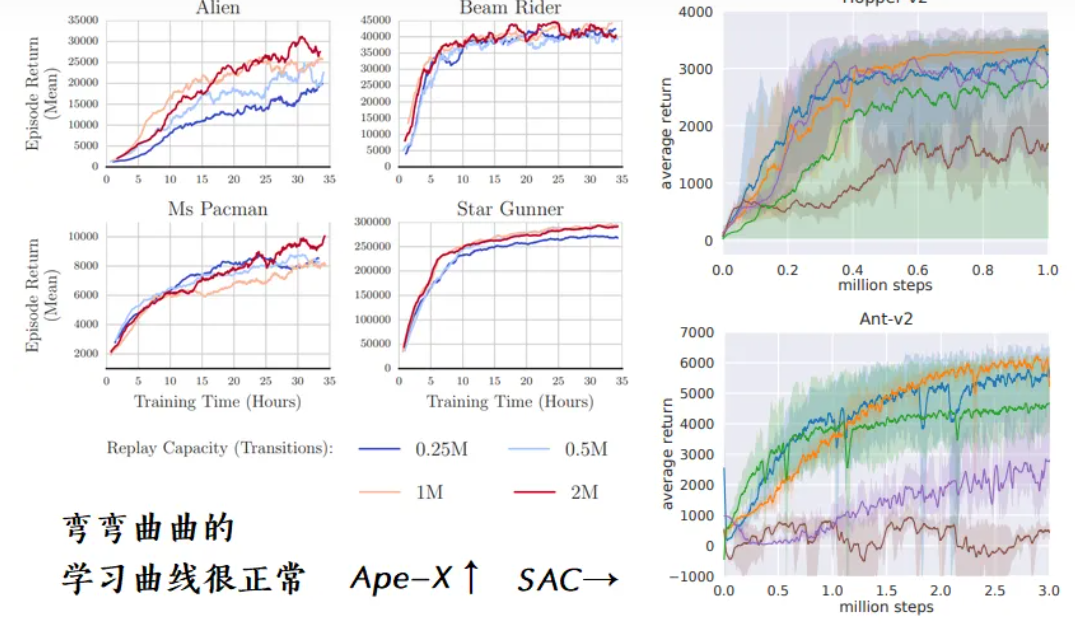
表现好
- 训练快,曲线越快达到某个目标分数 target reward (需要多测几次的结果才有说服力)
- 收敛稳,曲线后期不抖动(曲线在前期剧烈抖动是可以接受的)
- 得分高,曲线的最高点可以达到很高(即便曲线后期下降地很厉害也没关系,因为我们可以保存整个训练期间“平均得分”最高的模型)
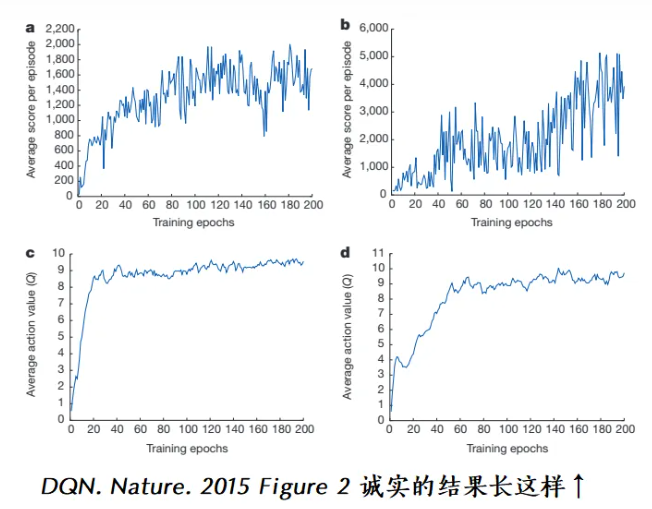
大部分情况下,算法越训练越差能避免,但也可以不理会。因为DRL只需要根据学习曲线保存性能最好的策略即可(前提是对每个策略的实际性能评估足够准确)
表现差
减小学习曲线的波动
如下图,波动过大的曲线,不利于我们评估DRL算法。
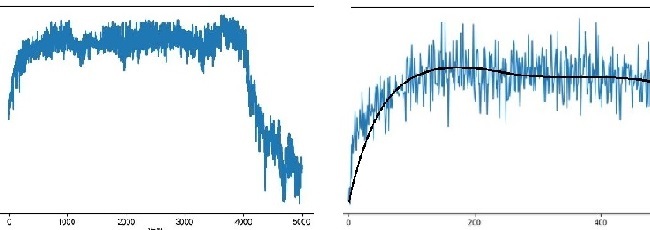
先弄清楚造成波动的原因,然后采用对应的解决方案:
- 如果在策略网络没有更新的情况下,Agent在环境中得到的分数差异过大。那么这是环境发生改变造成的:1. 每一轮训练都需要 env.reset(),然而,有时候重置环境会改变难度,这种情况下造成的波动无法消除。2. 有时候是因为DRL算法的泛化性不够好。此时我们需要调大相关参数增加探索,以训练出泛化性更好的策略。
- 如果在策略网络没有更新的情况下,Agent在环境中得到的分数差异较小。等到更新后,相邻两次的分数差异很大。那么这是环境发生改变造成的: 1. 把 learning rate 调小一点。2. 有时候是因为算法过度鼓励探索而导致的,调小相关参数即可。
loss震荡不下降(以深度学习DL为参考)
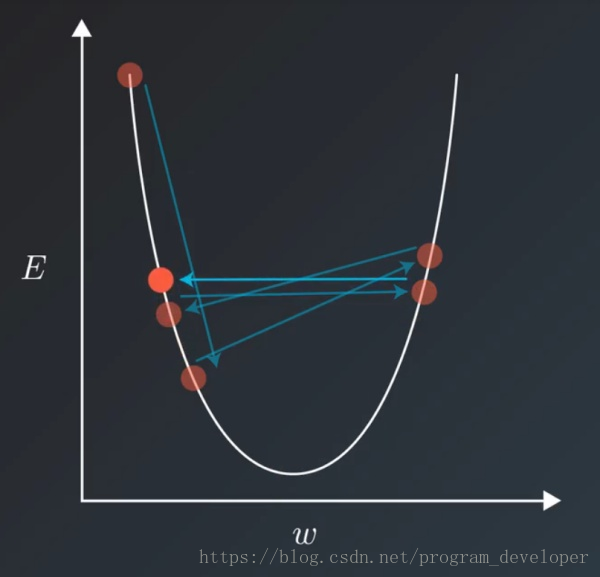
可以通过适当降低学习率(learning rate)来实现。但是,降低学习率又会延长训练所需的时间。
理想情况下 曲线 应该是 滑梯式下降
[绿线]
:
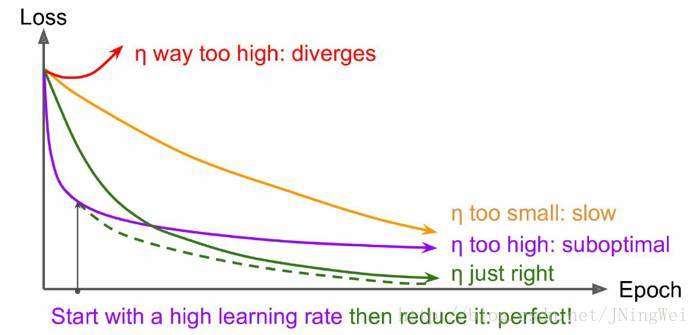
- 曲线 初始时 上扬
[红线]: Solution:初始 学习率过大 导致 振荡,应减小学习率,并 从头 开始训练 。 - 曲线 初始时 强势下降 没多久 归于水平
[紫线]: Solution:后期 学习率过大 导致 无法拟合,应减小学习率,并 重新训练 后几轮 。 - 曲线 全程缓慢
[黄线]: Solution:初始 学习率过小 导致 收敛慢,应增大学习率,并 从头 开始训练 。
On-Policy和off-Policy区别
学习方式
若agent与环境互动,则为On-policy(此时因为agent亲身参与,所以互动时的policy和目标的policy一致);若agent看别的agent与环境互动,自己不参与互动,则为Off-policy(此时因为互动的和目标优化的是两个agent,所以他们的policy不一致)。
采样数据利用
On-policy:采样所用的policy和目标policy一致,采样后进行学习,学习后目标policy更新,此时需要把采样的policy同步更新以保持和目标policy一致,这也就导致了需要重新采样。
Off-policy:采样的policy和目标的policy不一样,所以你目标的policy随便更新,采样后的数据可以用很多次也可以参考。
学习本质
监督学习中通常利用已知(已标记)的数据进行学习,其本质是从数据中总结规律,这和人从学1+1=2基本原理一致,强化学习的过程也是如此,仍然是从数据中学习,只不过强化学习中学习的数据是一系列的轨迹{< s 0 , a 0 , r 0 , s 1 > < s 1 , a 1 , r 1 , s 2 > , . . . , < s n − 1 , a n − 1 , r n − 1 , s n >
优缺点
on-policy直接了当,速度快,但不一定找到最优策略。
off-policy曲折,收敛慢,但采样效率高,是更为强大和通用。
DQN
DQN时序差分离线控制算法,off-line 训练的话不会考虑终止状态这种东西。每轮学习都是从memory里抽取记录来学的。
是第一个将深度学习模型与强化学习结合在一起从而成功地直接从高维的输入学习控制策略。
创新点
- 基于Q-Learning构造Loss Function(不算很新,过往使用线性和非线性函数拟合Q-Table时就是这样做)。
- 通过experience replay(经验池)解决相关性及非静态分布问题;
- 使用TargetNet解决稳定性问题。
优点
- 算法通用性,可玩不同游戏;
- End-to-End 训练方式;
- 可生产大量样本供监督学习。
缺点
- 无法应用于连续动作控制;
- Loss函数比较复杂
- CNN不一定收敛,需精良调参。(用ImageNet训练过的模型作为作为前置网络初始化参数,收敛不太难)
- 只能处理只需短时记忆问题,无法处理需长时记忆问题(DQN+LSTM改进方法(DRQN)论文见参考链接);
在实践中,DQN将最近的四帧画面当作输入进行训练,因此DQN无法记住四帧之前的内容。换言之,任何需要超过四帧记忆的游戏都将表现为非MDP问题,因为游戏未来的状态(和奖励)不仅仅取决于DQN当前的输入。游戏不再是MDP问题,而是部分可观察的MDP。现实世界中,任务往往不具有完整的信息,且有噪声,因此是部分可观察的。
MDP和POMDP
MDP:Markov decision process
Fully Observable Environments全部可观
又被称之为“无后效性”,即系统的下个状态只与当前状态信息有关,而与更早之前的状态无关
POMDP:partially observable Markov decision process
Partially Observable Environments部分可观
比如在扑克游戏中,只能看到公开的牌面,看不到其他人隐藏的牌。
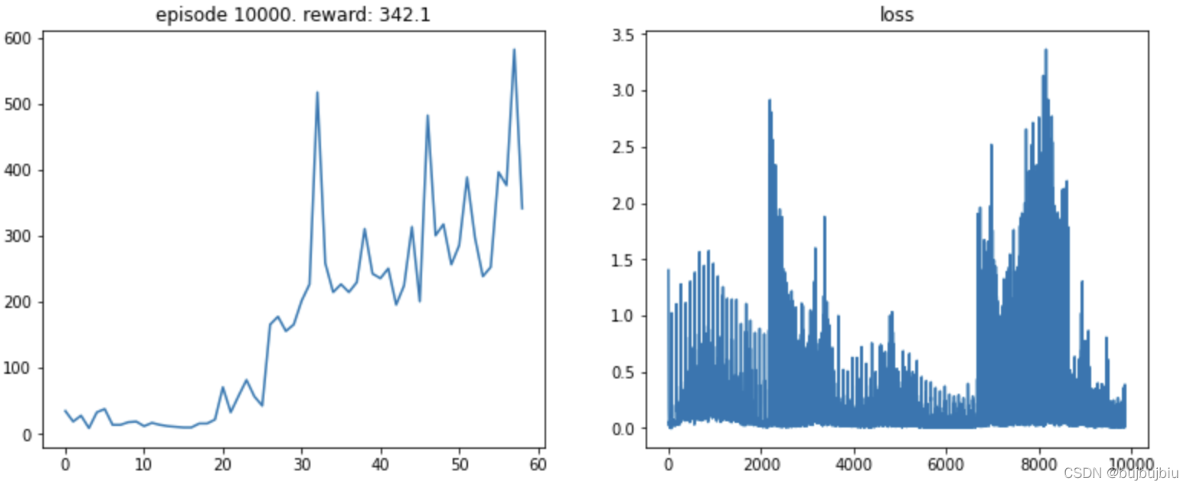
结果图
DQN
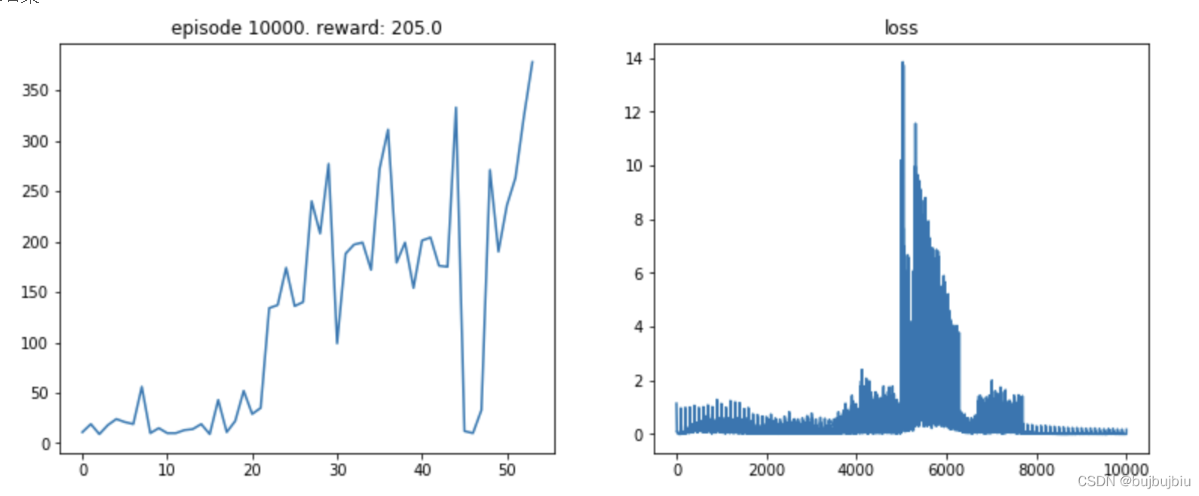
DDQN
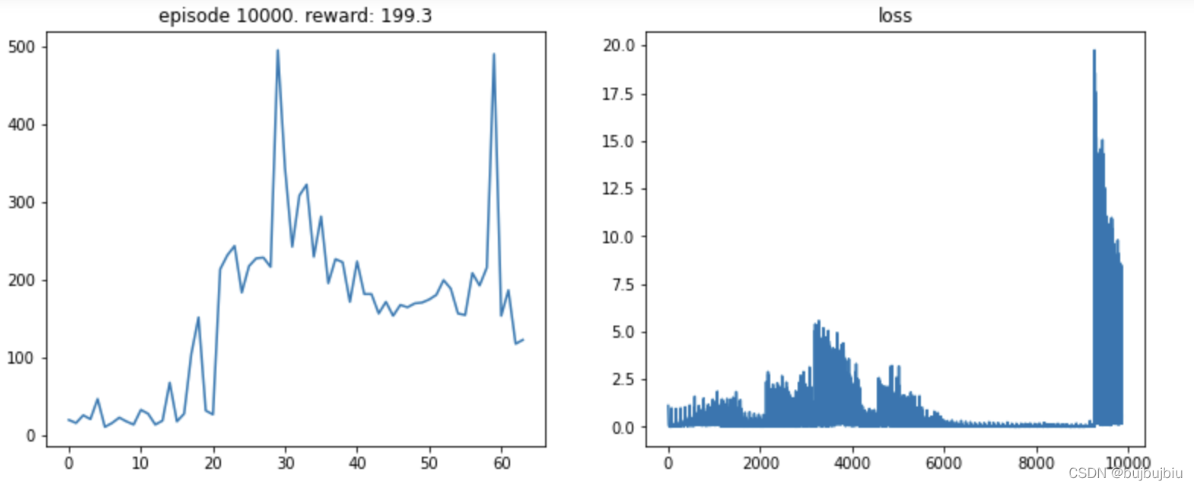
Dueling DQN
参考链接
深度强化学习——DQN_草帽B-O-Y的博客-CSDN博客_dqn
DRQN论文解读_greenmoss的博客-CSDN博客_drqn
[伏羲讲堂]奖励设计相关论文介绍 - 知乎
强化学习目前存在的问题-知乎
深度强化学习调参技巧- 知乎
离线强化学习(Offline RL)系列1:离线强化学习原理入门_旺财搬砖记的博客-CSDN博客_离线强化学习
离线强化学习(Offline RL)系列4:(数据集) 经验样本复杂度(Sample Complexity)对模型收敛的影响分析_旺财搬砖记的博客-CSDN博客_distribution shift
DQN及其变种(DDQN,Dueling DQN,优先回放)代码实现及结果_bujbujbiu的博客-CSDN博客_ddqn代码
3.1 学习率(learning rate)的选择_追蜗牛的coder的博客-CSDN博客_learning rate
权重衰减(weight decay)与学习率衰减(learning rate decay)_Microstrong0305的博客-CSDN博客_weight decay
深度学习:学习率learning rate 的设定规律_SunnyFish-ty的博客-CSDN博客
版权归原作者 参宿7 所有, 如有侵权,请联系我们删除。