如何利用CloudCompare软件进行点云数据标注
目录一、CloudComparer软件介绍二、如何进行点云数据的人工“打标签”一、CloudComparer软件介绍CloudCompare是一个三维点云(网格)编辑和处理软件。最初,它被设计用来对稠密的三维点云进行直接比较。它依赖于一种特定的八叉树结构,在进行点云对比这类任务时具有出色的性能【1】
Torch not compiled with CUDA enabled 解决办法
解决Torch not compiled with CUDA enabled 版本不兼容问题
yolov5 代码内容解析
122122<div id="MathJax_Message" style="display: none;"></div><div id="MathJax_Message" style="display: none;"></div>离开了122
标准化与归一化
Standardization & Nomalisation
yolov7开源代码讲解--训练代码
以前看CNN训练代码的时候,往往代码比较易懂,基本很快就能知道各个模块功能,但到了后面很多出来的网络中,由于加入了大量的trick,导致很多人看不懂代码,代码下载以后无从下手。训练参数和利用yaml定义网络详细过程可以看我另外的文章,都有写清楚。其实不管什么网络,训练部分大体都分几个部分:1.网络的
解决module ‘tensorflow‘ has no attribute ‘...‘系列
针对:TensorFlow版本1到2的代码不同
CVPR2022 多目标跟踪(MOT)汇总
CVPR2022 MOT文章汇总
模型部署入门教程(三):PyTorch 转 ONNX 详解
OpenMMLab:模型部署系列教程(一):模型部署简介OpenMMLab:模型部署系列教程(二):解决模型部署中的难题知道你们在催更,这不,模型部署入门系列教程来啦~在前二期的教程中,我们带领大家成功部署了第一个模型,解决了一些在模型部署中可能会碰到的困难。今天开始,我们将由浅入深地介绍 ONNX
Bert+LSTM+CRF命名实体识别pytorch代码详解
Bert+LSTM+CRF命名实体识别从0开始解析源代码。理解原代码的逻辑,具体了解为什么使用预训练的bert,bert有什么作用,网络的搭建是怎么样的,训练过程是怎么训练的,输出是什么调试运行源代码NER目标NER是named entity recognized的简写,对人名、地名、机构名、日期时
windows下CUDA的卸载以及安装
一、缘由对于CUDA新手来说,安装问题里面有很多需要注意的细节,很多自定义的选项,如果漏选就会出现一些莫名奇妙的问题。为此,会经常出现卸载CUDA,再安装CUDA的问题,下面总结。二、卸载前的准备(1)卸载工具:①windows自带的控制面板,用来卸载主程序②腾讯电脑管家等类似杀毒软件,用来清除卸载
目标检测指标mAP详解
相信刚刚接触目标检测的小伙伴也是有点疑惑吧,目标检测的知识点和模型属实有点多,想要工作找CV的话,目标检测是必须掌握的方向了。我记得在找实习的时候,面试官就问到了我目标检测的指标是什么,答:mAP!问:mAP是什么?我:.......!☺所以在本文中我也是详细说一下mAP 的含义,有什么不对的或者不
周志华《机器学习》第三章课后习题
目录3.1 试析在什么情形下式(3.2) 中不必考虑偏置项 b.3.2、试证明,对于参数w,对率回归的目标函数(3.18)是非凸的,但其对数似然函数(3.27)是凸的. 3.3、编程实现对率回归,并给出西瓜数据集3.0α上的结果.3.4 选择两个 UCI 数据集,比较 10 折交叉验证法和留一法所估
学习率设置
本篇主要学习神经网络超参数学习率的设置,包括人工调整和策略调整学习率。在模型优化中,常用到的几种学习率衰减方法有:分段常数衰减、多项式衰减、指数衰减、自然指数衰减、余弦衰减、线性余弦衰减、噪声线性余弦衰减。......
安装Pytorch-gpu版本(第一次安装 或 已经安装Pytorch-cpu版本后)
由于已经安装了cpu版本了,如果再在该环境下安装gpu版本会造成环境污染.因此,再安装gpu版本时,需要再新建一个虚拟环境才能安装成功。然后去官网下载所适配的版本。 安装完cuda和cudnn后,开始安装pytorch的gpu版本。1.安装cude首先查看windows电脑之前是否成功安装了CUDA
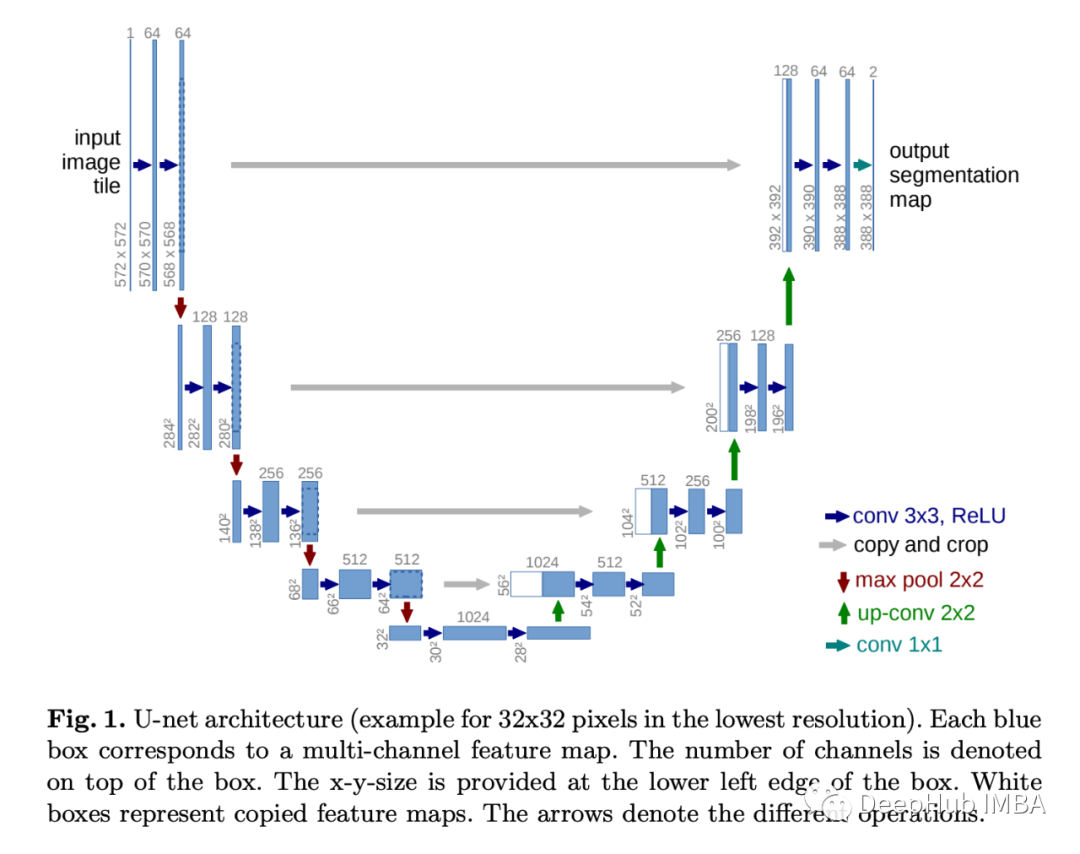
U-Net在2022年相关研究的论文推荐
UNet 可以算是 FCN 的一种变体,是最常用、最简单的一种分割模型,简单、高效、易懂、容易构建,且可以从小数据集中训练。2015 年,UNet 在论文 U-Net: Convolutional Networks for Biomedical Image Segmentation 中被提出 。
电力系统的常用仿真模块MATLAB/SIMULINK(1)
在进行电力系统的仿真时,先要了解构成电力系统的各元件。本章描述了相关的电力系统模块在MATLAB/SIMULINK里面的使用。其中包括:1. 同步发电机模块 2. 电力变压器 3. 输电线路 4. 负荷1. 同步发电机模块1.1 简化的同步电机模块简化的同步电机模块忽略了电枢反应电感、励磁和阻尼绕组
python+neo4j构建基于知识图谱的电影知识智能问答系统
~~~~~~~~ 最近,课程设计要求做关于知识图谱的调研工作。调研过程中,在网络上发现诸多同学自行构建知识图谱的相关内容,就考虑自己自行搭建一个。经过调研和基于自己技术的考量,最终还是打算做基于知识图谱的电影知识智能问答系统(主要是数据集比较好构建)。虽然比较
Deformable DETR源码解读
Deformable DETR源码解读
PointNet解读
PointNet解决的问题:如上图所示:1.点云图像的分类(整片点云是什么物体)2.点云图像的部件分割(整片点云所代表的物体能拆分的结构)3.点云图像的语义分割(将三维点云环境中不同的物体用不同的颜色区分开)论文中展示的输入输出效果:1.部件分割的效果(左边是输入不完整的点云,右边是输入完整的点云)
pytorch-lightning安装
一般pytorch-lightning 需要torch版本≥1.8.0。在安装pytorch-lightning时一定注意自己的torch是pip安装还是conda安装,两者要保持一致,不然会导致安装pytorch-lightning时会直接卸载掉你的torch,安装cpu版本的torch。http



