
一、TensorFlow简介
TensorFlow 是由 Google 团队开发的深度学习框架之一,它是一个完全基于 Python 语言设计的开源的软件。TensorFlow 的初衷是以最简单的方式实现机器学习和深度学习的概念,它结合了**计算代数**的优化技术,使它便计算许多数学表达式。
TensorFlow 可以训练和运行**深度神经网络**,它能应用在许多场景下,比如,图像识别、手写数字分类、递归神经网络、单词嵌入、自然语言处理、视频检测等等。TensorFlow 可以运行在多个 CPU 或 GPU 上,同时它也可以运行在移动端操作系统上(如安卓、IOS 等),它的架构灵活,具有良好的可扩展性,能够支持各种网络模型(如OSI七层和TCP/IP四层)。
TensorFlow官方网站有两个,访问其中一个就可以,它们分别如下 :
- 关于TensorFlow | TensorFlow中文官网
- https://www.tensorflow.org/
TensorFlow有以下重要功能 -
- 它包含一个叫做张量概念,用来创建多维数组,优化和计算数学表达式。
- 它包括深度神经网络和机器学习技术的编程支持。
- 它包括具有各种数据集的高可扩展计算功能。
二、机器学习与深度学习
2.1 什么是机器学习
通常,为了实现人工智能,我们使用机器学习。我们有几种算法用于机器学习。例如:
Find-S算法,决策树算法(Decision trees),随机森林算法(Random forests),人工神经网络
通常,有3种类型的学习算法:
1,监督机器学习算法用于进行预测。此外,该算法搜索分配给数据点的值标签内的模式。
2,无监督机器学习算法:没有标签与数据点相关联。这些ML算法将数据组织成一组簇。此外,它需要描述其结构,使复杂的数据看起来简单,有条理,便于分析。
3,增强机器学习算法:我们使用这些算法来选择动作。此外,我们可以看到它基于每个数据点。一段时间后,算法改变其策略以更好地学习。
2.2 什么是深度学习
机器学习只关注解决现实问题。它还需要更加智能的一些想法。机器学习通过旨在模仿人类决策能力的神经网络。ML工具和技术是关键的两个深度学习的窄子集,我们需要用他们来解决需要思考的问题。任何深度神经网络都将包含三种类型的图层:
输入层 隐藏层 输出层
我们可以说深度学习是机器学习领域的最新领域。这是实现机器学习的一种方式。
2.3 机器学习和深度学习应用
计算机视觉: 我们将其用于车牌识别和面部识别等不同应用。
信息检索: 我们将ML和DL用于搜索引擎,文本搜索和图像搜索等应用程序。
营销:我们在自动电子邮件营销和目标识别中使用这种学习技术。
医疗诊断:它在医学领域也有广泛的应用。癌症鉴定和异常检测等应用。
自然语言处理:适用于情感分析,照片标签,在线广告等应用。
2.4 趋势
如今,机器学习和数据科学正处于趋势中。在公司中,对它们的需求正在迅速增加。对于希望在其业务中集成机器学习而生存的公司而言,他们的需求尤其大。
深度学习被发现,并证明拥有最先进的表演技术。因此,深度学习让我们感到惊讶,并将在不久的将来继续这样做。
最近,研究人员不断探索机器学习和深度学习。过去,研究人员仅限于学术界。但是,如今,机器学习和深度学习的研究正在两个行业和学术界中占据一席之地。
三、TensorFlow实现递归神经网络
递归神经网络是一种面向深度学习的算法,遵循顺序方法。在神经网络中,我们总是假设每个输入和输出都独立于所有其他层。这些类型的神经网络称为循环,因为它们以顺序方式执行数学计算,考虑以下步骤来训练递归神经网络 -
第1步 - 从数据集输入特定示例。
第2步 - 网络将举例并使用随机初始化变量计算一些计算。
第3步 - 然后计算预测结果。
第4步 - 生成的实际结果与期望值的比较将产生错误。
第5步 - 为了跟踪错误,它通过相同的路径传播,其中也要调整变量。
第6步 - 重复从1到5的步骤,直到声明获得输出的变量正确定义。
第7步 - 通过应用这些变量来获得新的看不见的输入来进行系统预测。
表示递归神经网络的示意方法如下所述 :
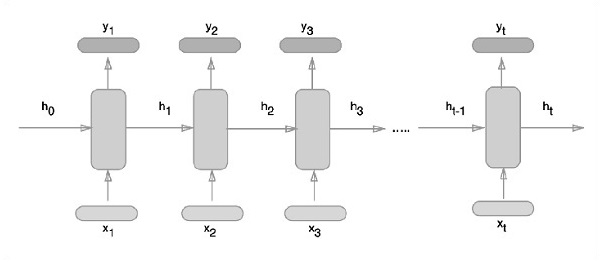
第1步 TensorFlow包括用于循环神经网络模块的特定实现的各种库。
#Import necessary modules
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
第2步 使用递归神经网络对图像进行分类,将每个图像行视为像素序列。MNIST图像形状具体定义为
28 * 28
像素。现在将为所提到的每个样本处理28个序列和28个步骤。定义输入参数以完成顺序模式。
n_input = 28 # MNIST data input with img shape 28*28
n_steps = 28
n_hidden = 128
n_classes = 10
# tf Graph input
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes]
weights = {
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([n_classes]))
}
第3步 使用RNN中定义的函数计算结果以获得最佳结果。这里,将每个数据形状与当前输入形状进行比较,并计算结果以保持准确率。
def RNN(x, weights, biases):
x = tf.unstack(x, n_steps, 1)
# Define a lstm cell with tensorflow
lstm_cell = rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)
# Get lstm cell output
outputs, states = rnn.static_rnn(lstm_cell, x, dtype = tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
pred = RNN(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()
第4步 在此步骤中,将启动图形以获得计算结果。也有助于计算测试结果的准确性。
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print("Iter " + str(step*batch_size) + ", Minibatch Loss {:.6f}".format(loss) + ", Training Accuracy= {:.5f}".format(acc))
step += 1
print("Optimization Finished!")
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={x: test_data, y: test_label}))
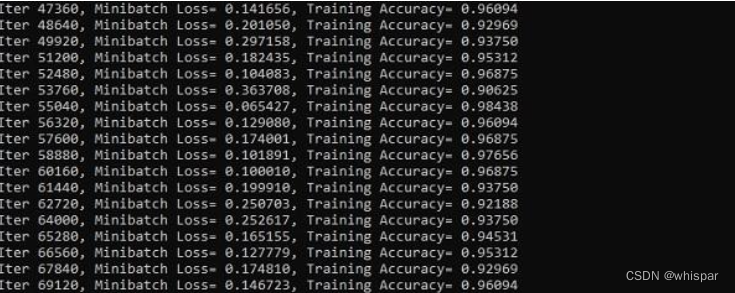
上面的屏幕截图显示了生成的输出 。
毫不夸张得说,TensorFlow的流行让深度学习门槛变得越来越低,只要你有Python和机器学习基础,入门和使用神经网络模型变得非常简单。TensorFlow支持Python和C++两种编程语言,再复杂的多层神经网络模型都可以用Python来实现。
版权归原作者 whispar 所有, 如有侵权,请联系我们删除。