Stable Diffusion XL:更快,更强
总的来说,新模型并没有给我留下深刻印象。MidJourney、Leonardo AI 和 Microsoft Image Generator 仍然有更好看的生成效果。尽管 Stable Diffusion XL 与之前的 AI 模型相比似乎没有显着进步,但它仍然向前迈进了一步,并且肯定还有进一步改进
大咖齐聚CCIG论坛——文档图像智能分析的产业前沿
2023年5月13日,中国图象图形学学会文档图像分析与识别专业委员会与上海合合信息科技有限公司联合打造《文档图像智能分析与处理》高峰论坛。欢迎感兴趣的同学们参加
分割常用损失函数
交叉熵损失公式:其中表示真实标签,表表示预测结果。优点:交叉熵Loss可以用在大多数语义分割场景中。缺点:对于只分割前景和背景的时候,当前景像素的数量远远小于背景像素的数量时,即y=0的数量远远大于y=1的数量,损失函数中y=0的成分就会占据主导,使得模型严重偏向背景,导致效果不好。(该缺点对二分类
【YOLOv8】实战一:手把手教你使用YOLOv8实现实时目标检测
YOLOv8导出为onnx模型,YOLOv8在LabVIEW中的部署,实现实时目标检测!在CPU和GPU上实现加速
目标检测算法——YOLOv5/YOLOv7改进之结合SOCA(单幅图像超分辨率)
CVPR19 单幅图像超分辨率来了!!!基于CNN的超分辨方法虽然取得了最好的结果,但此类方法关注更宽或更深的结构设计,忽略了中间层特征之间的关系。基于此,本文提出了二阶注意力机制(SOCA)更好的学习特征之间的联系,此模块通过利用二阶特征的分布自适应的学习特征的内部依赖关系,SOCA的机制是网
yolov5算法-学习过程
这张图是在找工作前,回忆yolo系列的发展历程,进行梳理的图。内容可能有一些不准确的地方,请指出。
【Metashape精品教程2】创建工程
Metashape工程的创建,包括导入照片、pos、相机参数、控制点,坐标系的选择
SPWM波调制度原理
SPWM波调制度原理
深入了解目标检测技术--从基本概念到算法入门
Hello大家好,我是Dream。 众所周知,目标检测是计算机视觉领域中的重要任务之一,其目的是识别图像或视频中包含的物体实例并将其定位。实现目标检测可以帮助人们在自动驾驶、机器人导航、安防监控等领域中更好地理解和应用图像信息。接下来Dream将带大家一起介绍目标检测的基本概念和常见方法,并详细讲解
SAM - 分割一切图像【AI大模型】
如果你认为 AI 领域已经通过 ChatGPT、GPT4 和 Stable Diffusion 快速发展,那么请系好安全带,为 AI 的下一个突破性创新做好准备。推荐:用快速搭建3D场景。Meta 的 FAIR 实验室刚刚发布了 Segment Anything Model (SAM),这是一种最先
(新SOTA)UNETR++:轻量级的、高效、准确的共享权重的3D医学图像分割
UNETR++:轻量级的、高效、准确的共享权重的3D医学图像分割高效配对注意(EPA)块,该块使用一对基于空间和通道注意的相互依赖的分支来有效地学习空间和通道方面的判别特征
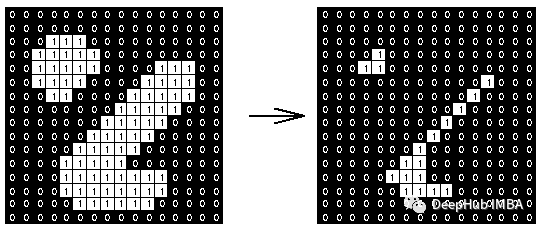
形态学运算与仿真:图像处理中形态学操作的简单解释
形态学是图像处理领域的一个分支,主要用于描述和处理图像中的形状和结构。形态学可以用于提取图像中的特征、消除噪声、改变图像的形状等。其中形态学的核心操作是形态学运算。
YOLOv5/v7 更换骨干网络之 SwinTransformer
提供 YOLOv5 / YOLOv7 / YOLOv7-tiny 模型 YAML
OpenCV中读取、显示、保存摄像头视频讲解与实战(附Python源码)
OpenCV中读取、显示、保存摄像头视频讲解与实战(附Python源码)
深度学习——卷积层的输入输出多通道(笔记)+代码
每组卷积核提取的特征不一样。我的猜测是,比如有一个图片,加上一个滤镜(一组卷积核),是朦胧的。通过一组卷积核,把输入的三个通道的信息对应像素进行加权和,得到一个输出通道。不管输入的是多个通道,每个通道都有对应的卷积核,输出通道的结果是所有卷积核的和。②把输出的6个通道传入,此刻的输入通道识别并组合输
2022.07.25 C++下使用opencv部署yolov7模型(五)
opencv下部署yolov7
YOLOV7 目标检测模型调试记录
YOLO系列在目标检测领域可谓名声赫赫,其性能表现不俗,如今其已经更新到了YOLOV7版本,今天便来一睹其风采。博主之前只是对YOLO算法的原理一知半解,并未实验,因此并不熟练,因此,借此机会来进行实验以为日后的论文撰写做好准备。
字节跳动CVPR 2023论文精选来啦(内含一批图像生成新研究)
计算机视觉领域三大顶会之一的 CVPR 今年已经开奖啦。今年的 CVPR 将于六月在加拿大温哥华举办,和往年一样,字节跳动技术团队的同学们收获了不少中选论文,覆盖文本生成图像、语义分割、目标检测、自监督学习等多个领域,其中不少成果在所属领域达到了 SOTA(当前最高水平)。一起来看看这些成果吧~
RealSense D435i深度相机介绍
D435i硬件结构及各个组件原理详解
OpenCV图像处理学习十,图像的形态学操作——膨胀腐蚀
图像的形态学操作——膨胀腐蚀



