
🏡博客主页: virobotics的CSDN博客:LabVIEW深度学习、人工智能博主
🎄所属专栏:『LabVIEW深度学习实战』
🍻上期文章: LabVIEW+OpenCV快速搭建人脸识别系统(附源码))
📰如觉得博主文章写的不错或对你有所帮助的话,还望大家多多支持呀! 欢迎大家✌关注、👍点赞、✌收藏、👍订阅专栏
文章目录
前言
从2015 年首次发布以来,You Only Look Once (YOLO) 系列计算机视觉模型一直是该领域最受欢迎的模型之一。其中,YOLO 架构的核心创新是将目标检测任务视为回归问题,从而使模型同时对所有目标边界框和类别概率生成预测。在过去的八年中,这种架构创新催生了一系列 YOLO 模型。之前也给大家介绍了一些YOLO 模型在LabVIEW上的部署。感兴趣的话可以查看专栏【深度学习:物体识别(目标检测)】本文主要想和各位读者分享YOLOv8在LabVIEW中的部署。
一、YOLOv8简介
YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。
YOLOv8是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进,以进一步提高性能和灵活性。YOLOv8 旨在快速、准确且易于使用,这也使其成为对象检测、图像分割和图像分类任务的绝佳选择。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,还支持YOLO以往版本,方便不同版本切换和性能对比。
YOLOv8 有 5 个不同模型大小的预训练模型:n、s、m、l 和 x。关注下面的参数个数和COCO mAP(准确率),可以看到准确率比YOLOv5有了很大的提升。特别是 l 和 x,它们是大模型尺寸,在减少参数数量的同时提高了精度。
每个模型的准确率如下
YOLOv8官方开源地址:https://github.com/ultralytics/ultralytics
二、环境搭建
2.1 部署本项目时所用环境
- 操作系统:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- AI视觉工具包:techforce_lib_opencv_cpu-1.0.0.98.vip
- onnx工具包:virobotics_lib_onnx_cuda_tensorrt-1.0.0.16.vip【1.0.0.16及以上版本】或virobotics_lib_onnx_cpu-1.13.1.2.vip
2.2 LabVIEW工具包下载及安装
- AI视觉工具包下载与安装参考: https://blog.csdn.net/virobotics/article/details/123656523
- onnx工具包下载与安装参考: https://blog.csdn.net/virobotics/article/details/124998746
三、yolov8导出onnx
注意:本教程已经为大家提供了YOLOv8的onnx模型,可跳过本步骤,直接进行步骤四-项目实战。若是想要了解YOLOv8的onnx模型如何导出,则可继续阅读本部分内容。
下面我们来介绍onnx模型的导出(以yolov8s为例,想要导出其他模型的方式也一样,只需要修改名字即可)
3.1 安装YOLOv8
YOLOv8的安装有两种方式,pip安装和GitHub安装。
- pip安装
pip install ultralytics -i https://pypi.douban.com/simple/
- GitHub安装
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e '.[dev]'
安装完成后就可以通过yolo命令在命令行进行使用了。
3.2 下载模型权重文件
在官方网站中下载我们所需要的权重文件
注意:这一步其实可以不做,我们在第三步导出模型为onnx的时候如果权重文件不存在,会自动帮我们下载一个权重文件,但速度会较慢,所以个人还是建议先在官网中下载权重文件,再导出为onnx模型
3.3 导出模型为onnx
新建一个文件夹名字为“yolov8_onnx”,将刚刚下载的权重文件“yolov8s.pt”放到该文件夹下的models文件夹里
在models文件夹下打开cmd,在cmd中输入以下命令将模型直接导出为onnx模型:
yolo export model=yolov8s.pt format=onnx opset=12
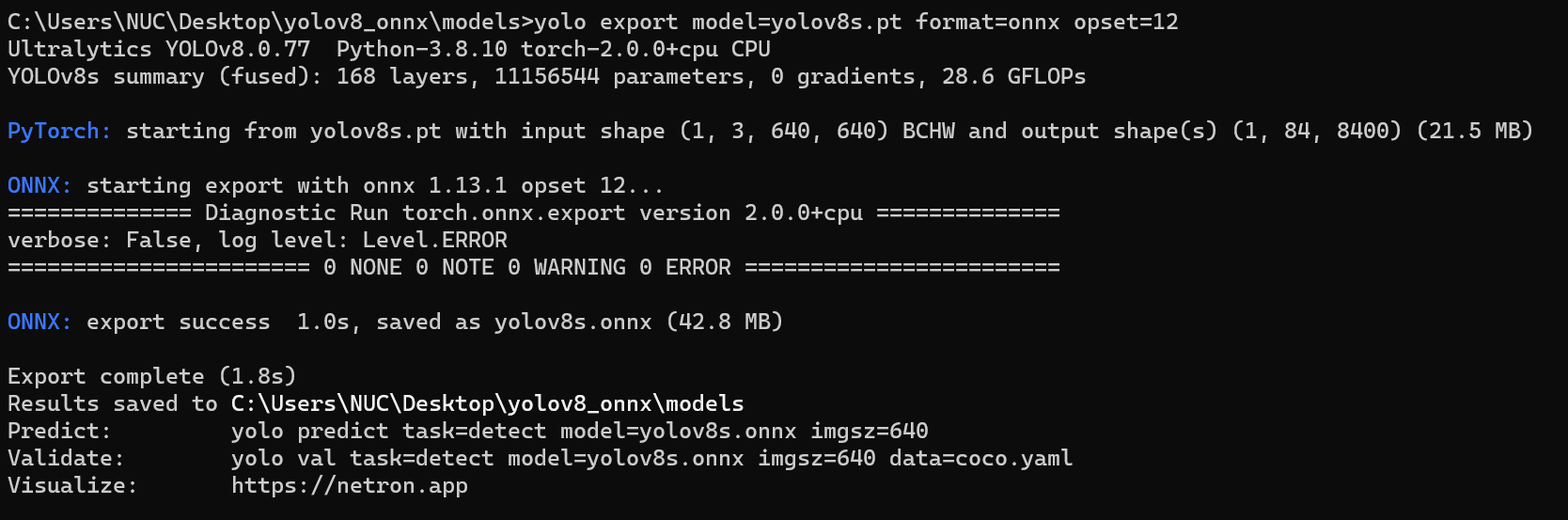
YOLOv8的3个检测头一共有80x80+40x40+20x20=8400个输出单元格,每个单元格包含x,y,w,h这4项再加80个类别的置信度总共84列内容,所以通过上面命令导出的onnx模型的输出维度为1x84x8400。
如果觉得上面方式不方便,那我们也可以写一个python脚本,快速导出yolov8的onnx模型,程序如下:
from ultralytics import YOLO
# Load a model
model = YOLO("\models\yolov8s.pt")# load an official model# Export the model
model.export(format="onnx")
四、项目实践
实现效果:LabVIEW中部署yolov8实现图片推理和视频推理
整个项目工程如下,本次项目以yolov8s为例

- model:yolov8模型文件
- subvi:子vi
- export.py:将yolov8的ptd导出为onnx
- yolov8_camera:yolov8摄像头视频实时推理
- yolov8_img:yolov8图片推理
准备工作
- 放置一张待检测图片和coco.name到yolov8_onnx文件夹下,本项目中放置了一张dog.jpg图片;
- 确保models文件中已经放置了yolov8的onnx模型:yolov8s.onnx;
4.1 YOLOv8在LabVIREW中实现图片推理
1.获取待检测图片、模型文件及类别标签文件路径;
2.模型初始化:加载onnx模型并读取该模型输入和输出的shape;
当然我们也可以在netron中直接查看模型的输入输出并手动创建模型输入输出shape数组
在netron中我们可以看到模型的输入输出如下:
所以这部分程序也可以改为如下图所示: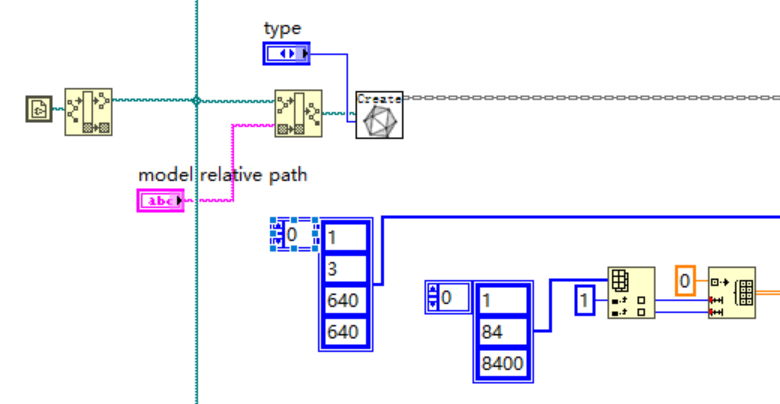
3.图像预处理:创建所需Mat并读取图片,对图片进行预处理
cvtColor:颜色空间转换把采集的BGR图像转为RGB
letterbox:深度学习模型输入图片的尺寸为正方形,而数据集中的图片一般为长方形,粗暴的resize会使得图片失真,采用letterbox可以较好的解决这个问题。该方法可以保持图片的长宽比例,剩下的部分采用灰色填充。blobFromImage的作用:
- size:640x640(图像resize为640x640)
- Scale=1/255,
- Means=[0,0,0](图像归一化至0~1之间)
最后,要将图片数据HWC转换(transpose)为神经网络容易识别的NCHW格式
- H:图片的高度:640
- W:图片的宽度:640
- C:图片的通道数:3
- N:图片的数量,通常为1

4.模型推理:推荐使用数据指针作为输入给到Run_one_input.vi,数据的大小为1x3x640x640;

5.获取推理结果:循环外初始化一个84x8400的二维数组,此数组作为Get_Result的输入,另一个输入为index=0,输出为84x8400的二维数组结果,推理之后,将推理结果由84x8400 transpose为8400x84,以便于输入到后处理;

6.后处理

范例中yolov5_post_process 的输入8400x84,84的排列顺序:
- 第0列代表物体中心x在图中的位置
- 第1列表示物体中心y在图中的位置
- 第2列表示物体的宽度
- 第3列表示物体的高度
- 第4~83列为基于COCO数据集的80分类的标记权重,最大的为输出分类。
8400的含义是:YOLOv8的3个检测头一共有80x80+40x40+20x20=8400个输出单元格
注:如果用户训练自己的数据集,则列数将根据用户定义的类别数改变。如果用户的数据集中有2类,那么输入数据的大小将为8400x6。前4列意义和之前相同,后2列为每一个分类的标记权重。
7.绘制检测结果;

8.完整源码;
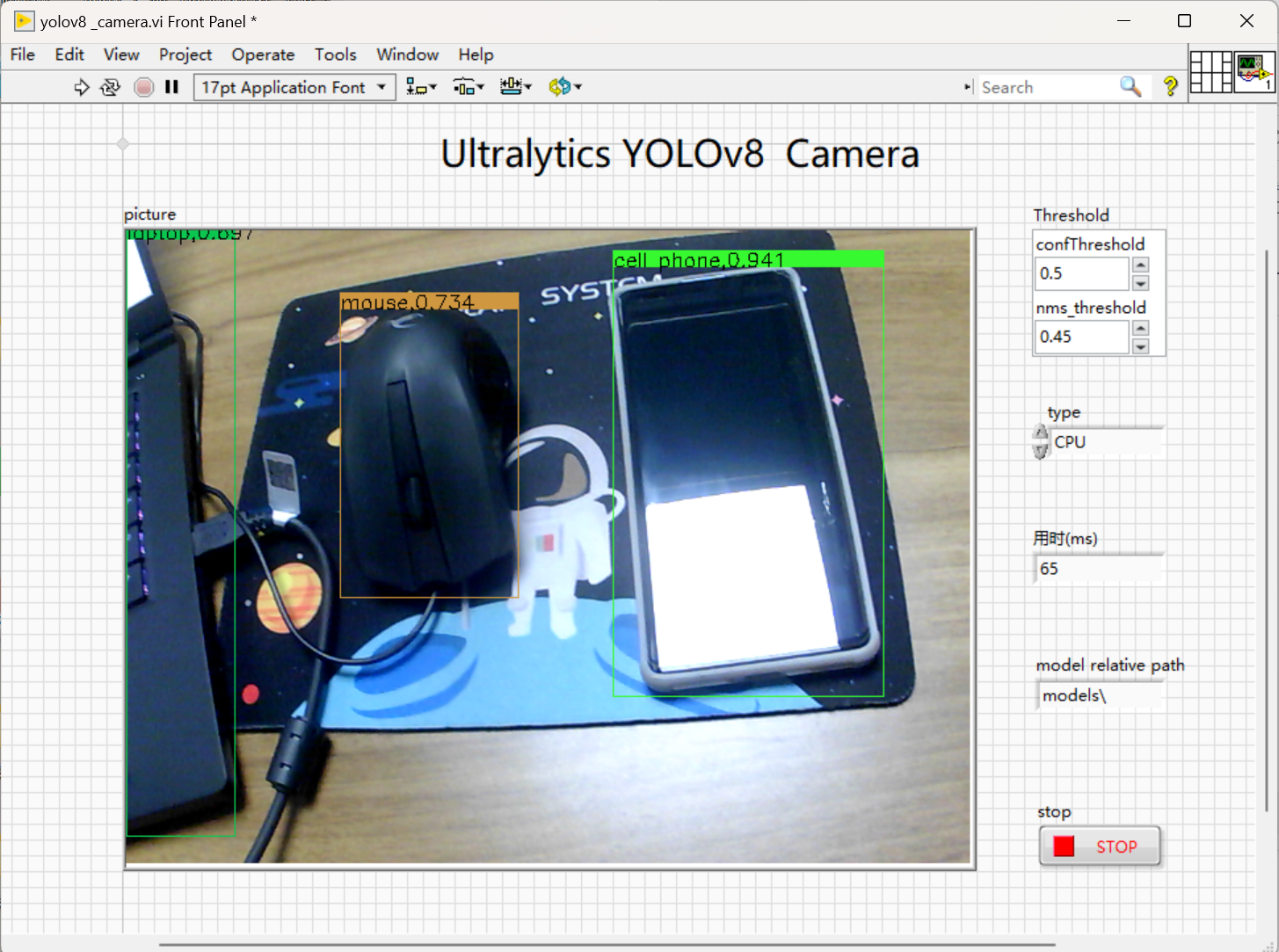
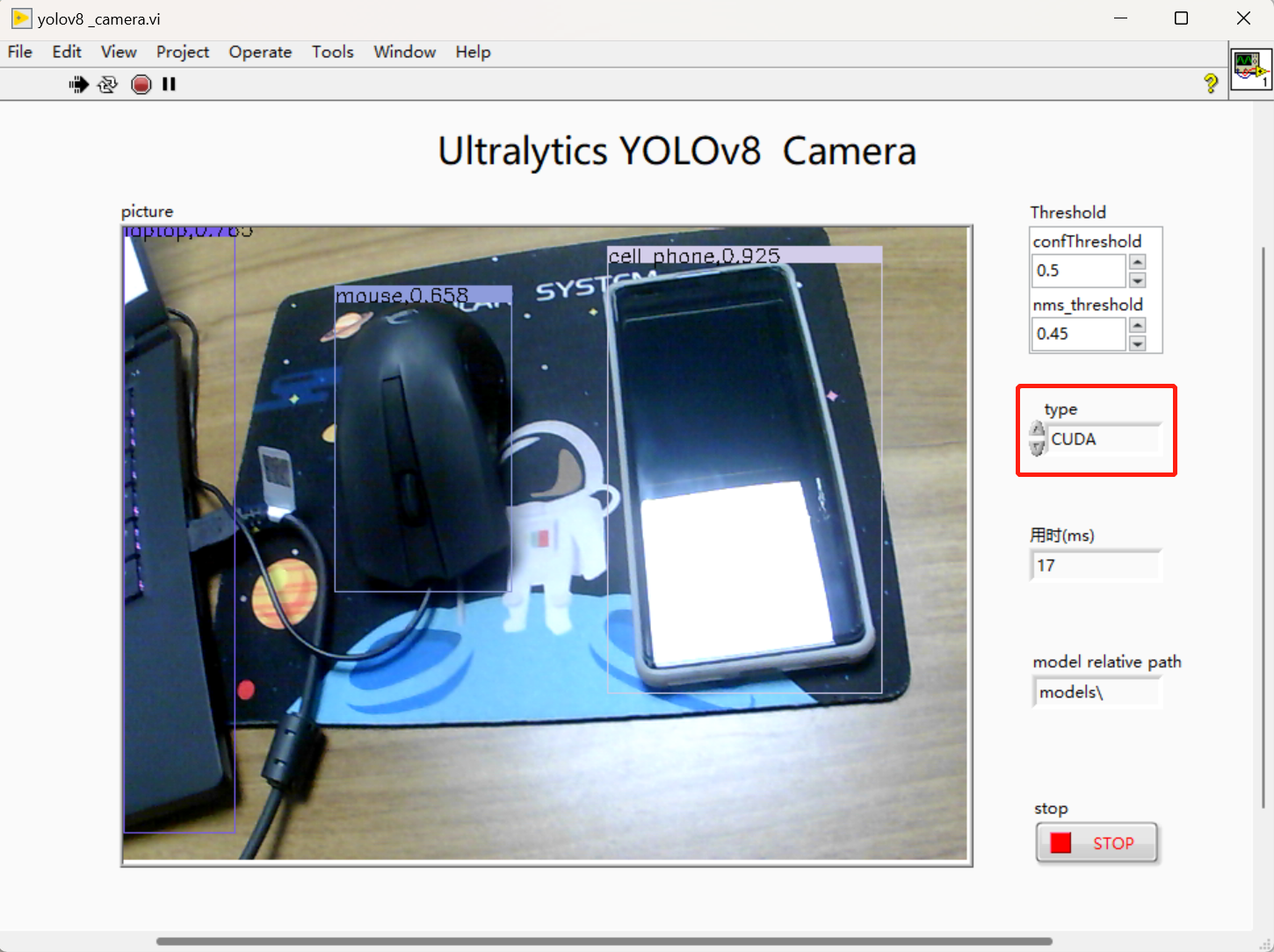
9.运行效果(运行电脑独显为笔记本RTX 3060)
- CPU加速:

- GPU加速:

4.2 YOLOv8在LabVIREW中实现视频推理
视频推理和推片推理实现方式基本一致,唯一的不同在于,摄像头实时推理过程中对视频流进行推理且耗时部分包括预处理、推理及后处理三部分。
1.完整程序;
2.实现效果(运行电脑独显为笔记本RTX 3060)
- CPU加速:
- GPU加速:
五、项目源码
如需源码,请在订阅本专栏后评论区留下邮箱
总结
以上就是今天要给大家分享的内容,希望对大家有用。之后会继续给大家更新使用OpenVINO以及TensorRT来部署加速YOLOv8实现目标检测,我们下篇文章见~
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏
推荐阅读
LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛
LabVIEW图形化的AI视觉开发平台(非NI Vision)VI简介
LabVIEW AI视觉工具包OpenCV Mat基本用法和属性
手把手教你使用LabVIEW人工智能视觉工具包快速实现图像读取与采集
LabVIEW开放神经网络交互工具包(ONNX)下载与超详细安装教程
【YOLOv5】手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别(含源码)
👇技术交流 · 一起学习 · 咨询分享,请联系👇
版权归原作者 virobotics 所有, 如有侵权,请联系我们删除。