
如果你认为 AI 领域已经通过 ChatGPT、GPT4 和 Stable Diffusion 快速发展,那么请系好安全带,为 AI 的下一个突破性创新做好准备。

推荐:用 NSDT场景设计器 快速搭建3D场景。
Meta 的 FAIR 实验室刚刚发布了 Segment Anything Model (SAM),这是一种最先进的图像分割模型,旨在改变计算机视觉领域。
SAM 基于对自然语言处理 (NLP) 产生重大影响的基础模型。 它专注于可提示的分割任务,使用提示工程来适应不同的下游分割问题。
为什么我们对 SAM 如此兴奋?
经过一天的测试,我们可以看到以下令人难以置信的进步:
- SAM 可以通过简单地单击或交互地选择点来分割对象以包括或排除对象。 你还可以通过使用多边形工具绘制边界框或分割区域来创建分割,它会捕捉到对象。
- 当在识别要分割的对象时遇到不确定性时,SAM 能够生成多个有效掩码。
- SAM 能够为图像中存在的所有对象自动识别和生成蒙版。
- 在预计算图像嵌入后,SAM 可以立即为任何提示提供分割掩码,从而实现与模型的实时交互。
在这篇博文中,我们将了解什么是 SAM 以及它为何能改变游戏规则,了解它与之前模型相比的表现如何,查看 SAM 的内部结构、网络架构、设计和实施,并了解 SAM 在 AI 辅助标记方面的潜在用途。
1、SAM vs. 之前的分割模型
SAM 是 AI 向前迈出的一大步,因为它建立在早期模型奠定的基础之上。 SAM 可以从其他系统获取输入提示,例如,在未来,从 AR/VR 耳机获取用户的目光来选择对象,使用输出掩码进行视频编辑,将 2D 对象抽象为 3D 模型,甚至流行的谷歌 照片任务,如创建拼贴画。
它可以通过在提示不清楚的情况下生成多个有效掩码来处理棘手的情况。 以用户提示寻找 Waldo 为例:

SAM 结果具有开创性的原因之一是分割掩码与 ViTDet 等其他技术相比有多好。 下图显示了两种技术的比较:
这篇研究论文更详细地比较了这两种技术的结果。
2、SAM 的网络架构和设计
SAM 的设计取决于三个主要组件:
- 可提示的分割任务可实现零样本泛化。
- 模型架构。
- 为任务和模型提供支持的数据集。
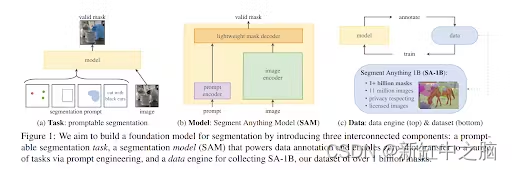
2.1 任务
SAM 接受了数百万张图像和超过十亿个掩码的训练,可为任何提示返回有效的分割掩码。 在这种情况下,提示是分割任务,可以是前景/背景点、粗框或遮罩、点击、文本,或者一般来说,指示图像中要分割的内容的任何信息。 该任务也用作模型的预训练目标。
2.2 模型
SAM 的架构包含三个组件,它们协同工作以返回有效的分割掩码:
- 图像编码器,用于生成一次性图像嵌入。
- 提示编码器,用于生成提示嵌入,提示可以是点、框或文本。
- 结合了提示和图像编码器的嵌入的轻量级掩码解码器。
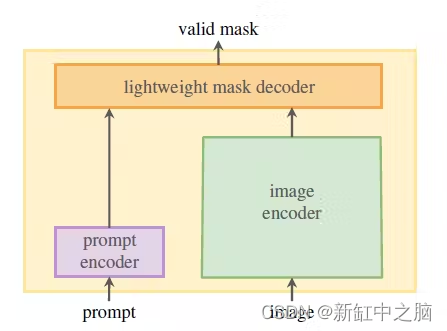
我们将在下一节中更深入地研究架构,但现在,让我们看一下数据集。
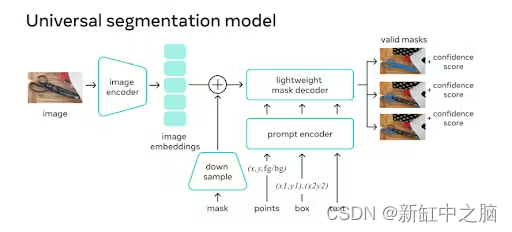
2.3 数据引擎和数据集
需要数据引擎来支持任务并改进数据集和模型。 数据引擎分为三个阶段:
- 辅助手动,其中 SAM 协助标注者对掩码进行标注,类似于经典的交互式分割设置。
- 半自动,其中 SAM 可以通过提示可能的对象位置来自动为对象子集生成掩码,标注者专注于剩余对象的标注,从而有助于增加掩码多样性。
- 全自动,人工标注者使用规则的前景点网格提示 SAM,平均每张图像生成 100 个高质量掩码。
数据引擎构建大段任何 10 亿掩码数据集 Meta AI 发布。
3、SAM模型的内幕
3.1 图像编码器
在最高级别,图像编码器(掩码自动编码器、MAE、预训练视觉变换器、ViT)生成一次性图像嵌入,可以在提示模型之前应用。
3.2 提示编码器
提示编码器将背景点、遮罩、边界框或文本实时编码到嵌入向量中。 该研究考虑了两组提示:稀疏(点、框、文本)和密集(掩码)。
点和框由位置编码表示,并为每种提示类型添加学习嵌入。 自由格式的文本提示由来自 CLIP 的现成文本编码器表示。 密集提示,如蒙版,嵌入卷积并与图像嵌入逐元素求和。
3.3 掩码解码器
轻量级掩码解码器根据来自图像和提示编码器的嵌入预测分割掩码。 它将图像嵌入、提示嵌入和输出标记映射到掩码。 所有嵌入都由解码器块更新,解码器块在两个方向(从提示到图像嵌入和返回)使用提示自我注意和交叉注意。
掩码被注释并用于更新模型权重。 这种布局增强了数据集,并允许模型随着时间的推移学习和改进,使其高效灵活。
3.4 10 亿掩码数据集
Segment Anything 10 亿掩码 (SA-1B) 数据集是迄今为止最大的标记分割数据集。 它专为高级分割模型的开发和评估而设计。
我们认为数据集将成为训练和微调未来通用模型的重要组成部分。 这将使他们能够在不同的分割任务中取得卓越的表现。 目前,该数据集仅在研究许可下可用。
SA-1B 数据集的独特之处在于:
- 数据的多样性
数据集经过精心策划,涵盖广泛的领域、对象和场景,确保模型可以很好地泛化到不同的任务。 它包括来自各种来源的图像,例如自然场景、城市环境、医学图像、卫星图像等。这种多样性有助于模型学习分割具有不同复杂性、规模和上下文的对象和场景。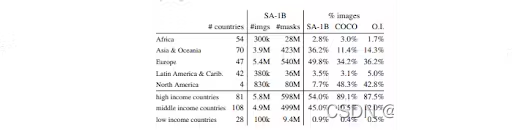
- 数据规模
SA-1B 数据集包含超过 10 亿张高质量注释图像,为模型提供了充足的训练数据。 庞大的数据量有助于模型学习复杂的模式和表示,使其能够在不同的分割任务上实现最先进的性能。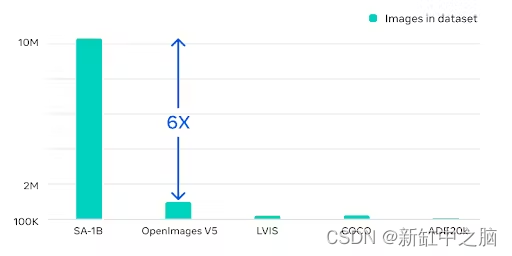
- 高质量的注释
数据集已经用高质量的掩码仔细注释,导致更准确和详细的分割结果。 在 SA-1B 数据集的 Responsible AI (RAI) 分析中,调查了地理和收入分配中潜在的公平问题和偏见。
研究论文表明,与其他开源数据集相比,SA-1B 中来自欧洲、亚洲和大洋洲以及中等收入国家的图像比例要高得多。 值得注意的是,SA-1B 数据集包含至少 2800 万个所有地区的掩码,包括非洲。 这是之前任何数据集中掩码总数的 10 倍。
我们认为 SA-1B 数据集将进入计算机视觉名人堂(与 COCO、ImageNet 和 MNIST 等著名数据集一起)作为未来计算机视觉分割模型开发的资源。
4、SAM是开源的吗?
简短的回答是,YES! SA-1B 数据集已作为研究目的开源发布。 此外,遵循 FAIR 对开放研究的承诺,Meta AI 发布了预训练模型(大小约为 2.4 GB)和 Apache 2.0(宽松许可)下的代码。 它可以在 GitHub 上免费访问。 还提供了训练数据集以及交互式演示 Web UI。
所有链接都来自项目网页:
5、基于SAM的 AI 辅助标记
我们将 Segment Anything Model (SAM) 视为 AI 辅助标记的游戏规则改变者。 它基本上消除了使用多边形绘图工具分割图像的痛苦,并允许你专注于对您的模型更重要的数据任务。
这些其他数据任务包括映射不同对象之间的关系,赋予它们描述它们如何行为的属性,以及评估训练数据以确保它是平衡的、多样化的和没有偏见的。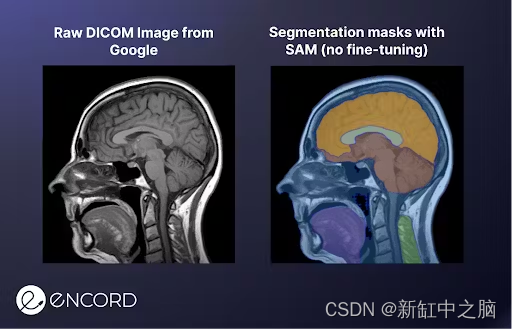
6、使用 AI 增强手动标记
SAM 可用于创建 AI 辅助的工作流程增强功能并提高标注者的工作效率。 以下是我们认为 SAM 可以做出的一些改进:
- 提高准确性:标注者可以获得更精确和准确的标签,减少错误并提高注释数据的整体质量。
- 更快的标注:毫无疑问,SAM 将加快标记过程,与合适的图像标注工具结合使用时,使标注者能够更快、更高效地完成任务。
- 一致性:让所有标注者都使用一个版本的 SAM 将确保标注之间的一致性,这在多个注释者处理同一个项目时尤为重要。
- 减少工作量:通过自动分割复杂和复杂的结构,SAM 显着减少了标注者的手动工作量,使他们能够专注于更具挑战性和更复杂的任务。
- 持续学习:随着标注者改进和纠正 SAM 的辅助标记,我们可以实施它,使模型不断学习和改进,从而随着时间的推移获得更好的性能并进一步简化标注过程。
因此,将 SAM 集成到注释工作流程中对我们来说是轻而易举的事,这将使我们当前和未来的客户能够加速尖端计算机视觉应用程序的开发。
7、SAM 如何为 AI 辅助标记做出贡献
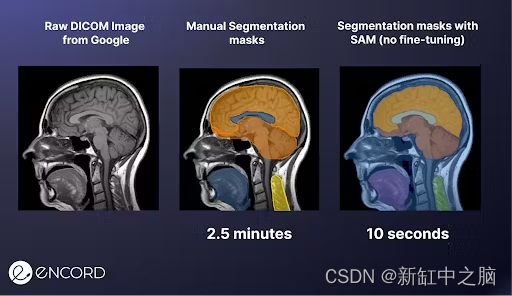
要举例说明 SAM 如何有助于 AI 辅助标记,请考虑之前的医学图像示例。 我们将 DICOM 图像上传到SAM的演示 Web UI,并花了 10 秒钟单击图像以分割不同的兴趣区域。
之后,我们使用多边形标注工具进行了手动标记,耗时 2.5 分钟。 SAM标注速度提高 15 倍!
8、真实世界的用例和应用程序
SAM 几乎可以用于你能想到的每一个分割任务,从实例分割到全景分割。 让我们感到兴奋的是,在你的专家审阅者将本体添加到顶部之前,SAM 可以多快地帮助你使用几乎像素完美的分割蒙版预先标记对象。
从农业和零售到医学图像和地理空间图像,使用 SAM 可以实现的 AI 辅助标记是无穷无尽的。 这就是为什么我们 对这项新技术感到非常兴奋。
9、SAM会给我们留下什么?
Segment Anything Model (SAM) 真正代表了计算机视觉领域的突破性发展。 通过利用可提示的分割任务,SAM 可以使用提示工程来适应各种下游分割问题。
这种创新方法与迄今为止最大的标记分割数据集 (SA-1B) 相结合,使 SAM 能够在各种分割任务中实现最先进的性能。
凭借显着增强 AI 辅助标记并减少图像分割任务中的人工劳动的潜力,SAM 可以为农业、零售、医学影像和地理空间影像等行业铺平道路。
作为一个开源模型,SAM 将激发计算机视觉的进一步研究和开发,鼓励 AI 社区在这个快速发展的领域突破可能性的界限。
最终,SAM 标志着计算机视觉故事的新篇章,展示了基础模型在改变我们感知和理解周围世界的方式方面的力量。
原文链接:SAM:分割任意图像 — BimAnt
版权归原作者 新缸中之脑 所有, 如有侵权,请联系我们删除。