魔改YOLOv5/YOLOv7高阶版——改进之结合解耦头Decoupled_Detect
🚀🚀🚀NEW!!!魔改YOLOv5/YOLOv7目标检测算法来啦 ~💡魔法搭配计算机视觉领域各类创新新颖且行之有效的网络结构,平均精度均值mAP涨点明显,实验效果也俱佳。有需要的小伙伴可以在CSDN后台留言+点赞收藏喔!!!👍👍👍🔥🔥🔥
ORB-SLAM3代码详解----基本框架解析及ORB特征提取
一、ORB-SLAM3结构解析输入【Frame and IMU】:frame可以是单目,双目和RGB-D,外加一个IMU,视觉出来的图像,主要是使用ORB算法进行特征提取,IMU的数据主要是用来做积分。Tracking :和ORB-SLAM2的第一个区别。在跟踪模块Tracking ,之前是只根据图
利用OpenCV把一幅彩色图像转换成灰度图
用Mat存储一幅图像时,若图像在内存中是连续存储的(Mat对象的isContinuous == true),则可以将图像的数据看成是一个一维数组,而其data(uchar*)成员就是指向图像数据的第一个字节的,因此可以用data指针访问图像的数据。彩色图像中的每个像素颜色由R、G、B三个分量来决定,
冲激阶跃与卷积
时移性质:若ƒ1(t)*ƒ2(t)=ƒ(t),则有ƒ1(t-t1)*ƒ2(t-t2)=ƒ(t-t1-t2)。分配律:ƒ1(t)*[ƒ2(t)+ƒ3(t)]=ƒ1(t)*ƒ2(t)+ƒ1(t)*ƒ3(t);f(t)与冲激偶函数的卷积:ƒ(t)*δ’(t)=f’(t)*δ(t)=ƒ’(t);2)反转平移
空间变形网络——STN
CNN 的机理使得 CNN 在处理图像时可以做到 transition invariant,却没法做到 scaling invariant 和 rotation invariant。即使是现在火热的 transformer 搭建的图像模型 (swin transformer, vision tran
基于MindSpore复现UNet—语义分割
U-Net: Convolutional Networks for Biomedical Image Segmentation
Camera-IMU联合标定原理
在VIO系统中,camera-imu间内外参精确与否对整个定位精度起着重要的作用。所以良好的标定结果是定位系统的前提工作。目前标定算法主要分为离线和在线标定,离线标定以kalibr为代表,能够标定camera内参、camera-imu之间位移旋转、时间延时以及imu自身的刻度系数、非正交性等。标定过
53、RK3588测试视频编解码和 POE OAK Camera编码结合开发
这里使用rk3588和oak相结合,存在两个问题,多个usb电流都在1a内,只有一个type-c转usb的电流在2a内,oak的基础电流要求900ma,峰值电流要求在1.5a左右,这就限制了oak的目标检测和推理数据传输,所以需要使用编码方式压缩数据量传输,即使使用usb的线进行数据传输,这个实验使
yolov5模型(.pt)在RK3588(S)上的部署(实时摄像头检测)
yolov5模型(.pt)在RK3588(S)上的部署(实时摄像头检测)
11 OpenCV图像识别之人脸识别
Eigenfaces是一种基于PCA(Principal Component Analysis,主成分分析)的人脸识别方法,属于OpenCV中的特征脸方法之一。该方法将人脸图像转换为低维的特征向量,使用PCA降维的方式提取出训练集中的主成分特征,进而提取出人脸图像的特征向量。在进行识别时,通过比较输
FDG-PET成像(氟脱氧葡萄糖-正电子体层扫描成像)简介与原理
PET全称为:正电子发射型计算机断层显像(Positron Emission Computed Tomography),是核医学领域比较先进的临床检查影像技术。PET的大致方法是:将某种物质,一般是生物生命代谢中必须的物质,如:葡萄糖、蛋白质、核酸、脂肪酸等标记上短寿命的放射性核素(如18F,11C
VS2022 永久配置OpenCV4.7.0开发环境
1.打开已有的VS项目,在左下角-属性管理器-DeBug|X64中右键-添加新项目属性表。每次新建一个OpenCV 项目都要重新配置一下环境,真的很麻烦,现在教大家一个方法,以后不用重复配置。7.如果再新建工程的时候,在属性添加现有属性把我们建的opencv属性添加一下就可以啦,3.在“通用属性-
python实现人脸识别(face_recognition)
本项目是世界上最强大、简洁的人脸识别库,你可以使用Python和命令行工具提取、识别、操作人脸。本项目的人脸识别是基于业内领先的C++开源库dlib中的深度学习模型,用Labeled Faces in the Wild人脸数据集进行测试,有高达99.38%的准确率。但对小孩和亚洲人脸的识别准确率尚待
AIGC图像生成的原理综述与落地畅想
AIGC,这个当前的现象级词语。本文尝试从文生图的发展、对其当前主流的 Stable Diffusion 做一个综述。以下为实验按要求生成的不同场景、风格控制下的生成作品。概述▐技术演进一:昙花初现 GAN 家族GAN 系列算法开启了图片生成的新起点。GAN的主要灵感来源于博弈论中零和博弈的思想,通
Segment anything(SAM)论文及demo使用保姆级教程
解读segment anything(SAM)论文并提供SAM模型demo的保姆级使用教程
基于深度强化学习的目标驱动型视觉导航泛化模型
目标是仅使用视觉输入就能导航并到达用户指定目标的机器人,对于此类问题的解决办法一般有两种。基于地图的导航算法或者SLAM系统与最先进的物体检测或图像识别模型的局限性深度卷积神经网络(cnn)与强化学习(RL)相结合的方法优势 深度强化学习(DRL)确实允许以自然的方式管理视觉和运动之间的关系,
文生图关键问题探索:个性化定制和效果评价
文生图模型是当前人工智能领域最具潜力和前景的研究方向之一。未来,随着计算能力的提高和技术的进一步发展,文生图模型的应用前景将会更加广泛和深远。然而,针对其应用过程中存在的一些问题,如模型评价缺乏一致性、控制生成过程效率低下、定制个性化模型困难以及高质量文图数据集缺乏等,需要我们进一步研究探索解决方案
指纹识别综述(2): 指纹传感器
指纹识别技术在众多领域的普及离不开指纹传感技术的创新和进步。
【目标检测】YOLOV8实战入门(五)模型预测
预测模式可以为各种任务生成预测,在使用流模式时返回结果对象列表或结果对象的内存高效生成器。文件加载,用户可以提供图像或视频来执行推理。模型预测输入图像或视频中对象的类别和位置。的流媒体模式应用于长视频或大型预测源,否则结果将在内存中累积并最终导致内存不足错误。函数在图像对象中绘制结果。它绘制在结果对
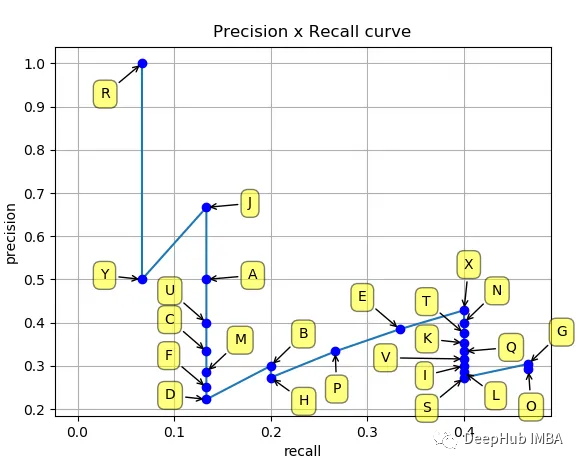
深入了解平均精度(mAP):通过精确率-召回率曲线评估目标检测性能
平均精度(Average Precision,mAP)是一种常用的用于评估目标检测模型性能的指标。



