
前言
YOLO系列在目标检测领域可谓名声赫赫,其性能表现不俗,如今其已经更新到了YOLOV7版本,今天便来一睹其风采。
博主之前只是对YOLO算法的原理一知半解,并未实验,因此并不熟练,因此,借此机会来进行实验以为日后的论文撰写做好准备。
看一下YOLOV7X的网络结构: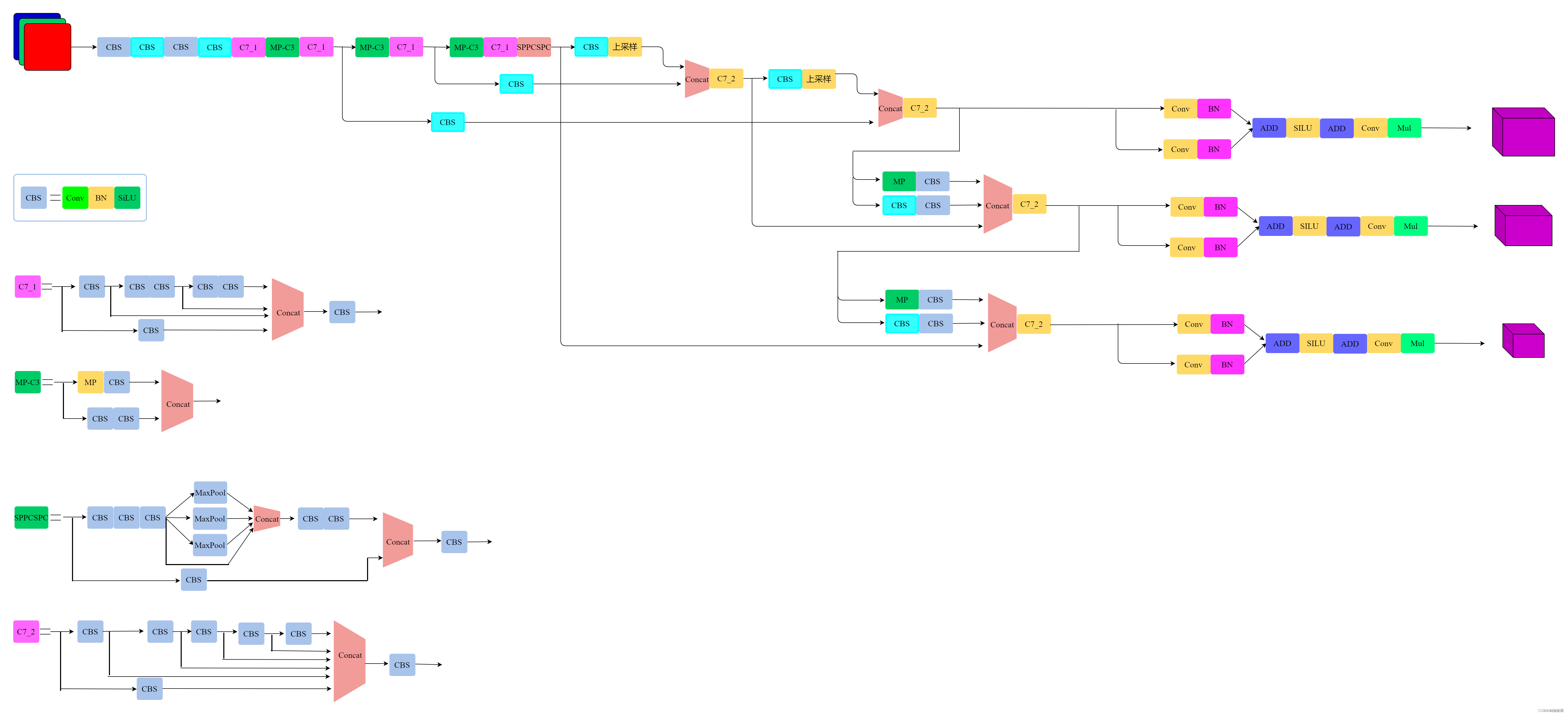
源码与环境
首先是去下载源码:
https://gitcode.net/mirrors/bubbliiiing/yolov7-pytorch?utm_source=csdn_github_accelerator
在readme中,有着相关介绍一级一些步骤,下载完成后我们打开项目,博主使用的是pycharm,在requirement.txt中给出了所需环境。
scipy==1.2.1
numpy==1.17.0
matplotlib==3.1.2
opencv_python==4.1.2.30
torch==1.2.0
torchvision==0.4.0
tqdm==4.60.0
Pillow==8.2.0
h5py==2.10.0
当然这个环境也不一定需要完全匹配,能用即可。
打开文件后,我们先train以下试试,出现报错:
FileNotFoundError:[Errno 2] No such fileor directory:'model_data/yolov7_weights.pth'
出现报错,这是yolov7的权重文件缺失,由于权重文件较大,就没有放到项目中去,下载放入指对文件夹model_data即可
链接: https://pan.baidu.com/s/1uYpjWC1uOo3Q-klpUEy9LQ
提取码:pmua
再次运行:
FileNotFoundError:[Errno 2] No such fileor directory:'2007_train.txt'
还是文件丢失问题,没有训练的文件,找到这个读取的文件目录,我们去下载相关文件
项目使用的是VOC数据集,首先我们去下载相关文件
VOC数据集下载地址如下,里面已经包括了训练集、测试集、验证集(与测试集一样),无需再次划分:
链接: https://pan.baidu.com/s/19Mw2u_df_nBzsC2lg20fQA
提取码: j5ge
下载完成后,我们需要将其放到合适的位置:
训练VOC07+12数据集
VOC是 (Visual Object Classes)的简称,它是一套检测和识别标准化的数据集,可以说是该类数据集的开山之作,目前学术界主流是在COCO(另外一个数据集,后面会介绍)数据集上验证模型,已经很少有在VOC数据集上验证了。可以说VOC已经对state-of-the-art的模型不构成挑战了。但是VOC是不是没有必要学习了呢?其实不然。一方面VOC作为第一代的数据集,数据量不大,所以很快可以下载上手;另外训练自己的检测器或者是分类器的时候,制作VOC格式数据集还是比较方便。
且后续的很多数据集,都是在此基础上的扩展。目前应用最广的是VOC 2007和VOC 2012,即在2007推出的VOC和2012年推出的
数据集的准备
本文使用VOC格式进行训练,训练前需要下载好VOC07+12的数据集,解压后放在根目录
文件分别为:标注文件,文件目录设置,图片
数据集的处理
修改voc_annotation.py里面的annotation_mode=2,运行voc_annotation.py生成根目录下的2007_train.txt和2007_val.txt。(这里也就是刚刚我们需要的文件)
运行成功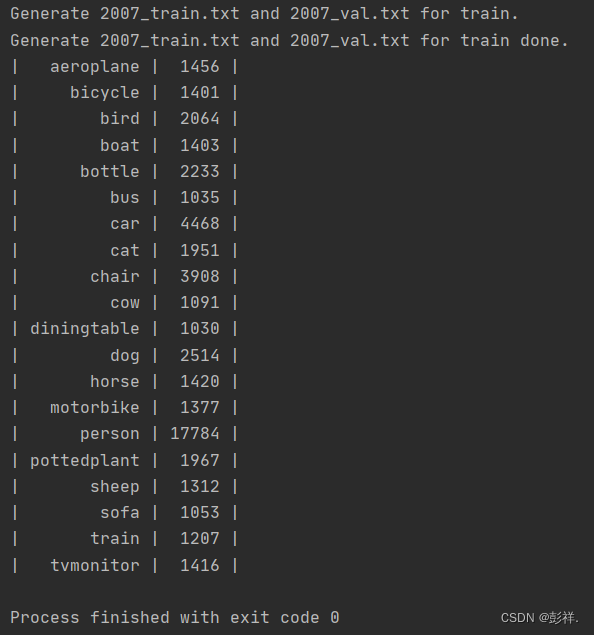
生成的tran2017.txt文件内容:
开始网络训练
train.py的默认参数用于训练VOC数据集,直接运行train.py即可开始训练。
此时再次运行train.py,报错:
内存不足
OSError:[WinError 1455] 页面文件太小,无法完成操作。 Error loading "D:\Anaconda\envs\python38\lib\site-packages\torch\lib\shm.dll"or one of its dependencies.
这是由于内存不足造成的,修改我们的batch_size即可,或者关闭pycharm,重新运行,发现还是报错,后来看到代码中
# num_workers 用于设置是否使用多线程读取数据# 开启后会加快数据读取速度,但是会占用更多内存# 内存较小的电脑可以设置为2或者0 #------------------------------------------------------------------#
num_workers =0
我们将其设置为0,原本为4
再次运行:报错
数据存放位置不统一
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
Epoch 1/30:0%||0/4137[00:30<?, ?it/s<class'dict'>]
这是由数据使用不统一导致的,网上有解释说需要降低pytorch版本,
版本1.13.0-cuda117,更换为torch==1.10.1+cu113
但博主没有选择这种方式,而是选择修改代码:
找到yolo_training.py文件
添加:
device = targets.device

修改代码:
from_which_layer.append((torch.ones(size=(len(b),))* i).to(torch.device(device)))

添加代码:
fg_mask_inboxes = fg_mask_inboxes.to(torch.device(device))

再次运行:终于可以运行了
查看占用
此时我们查看显卡占用情况:cmd -> nvidia-smi
利用率:100%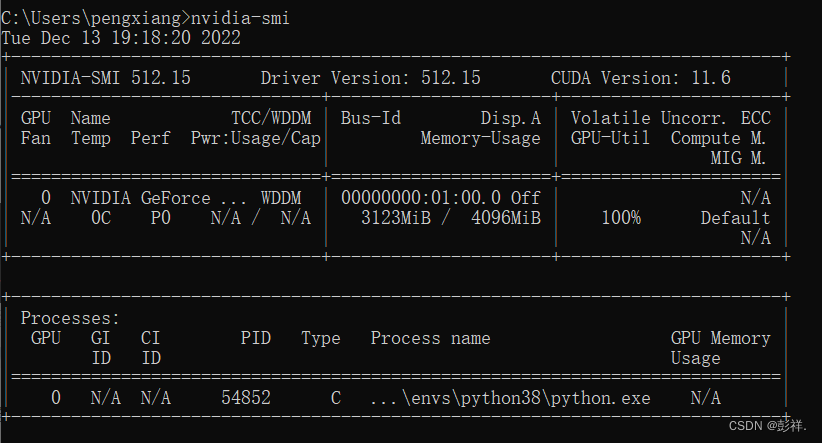
显存占用并不大:
此时我们可以尝试增大以下batch-size,毕竟太慢了,显存占用明显升高了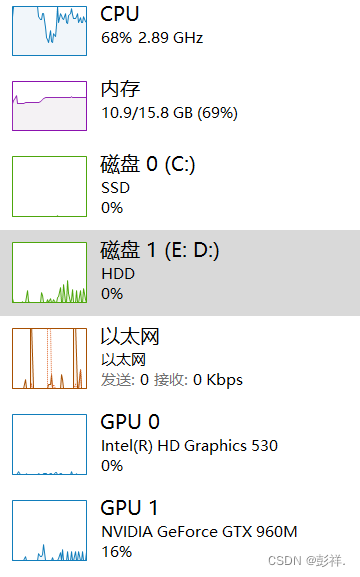
当提升到batch-size=16时:报错显存爆了哈哈哈,还是老老实实设置为8吧
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0;4.00 GiB total capacity;3.48 GiB already allocated;0bytes free;3.51 GiB reserved in total by PyTorch) If reserved memory is>> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
运行成功后发现速度特别慢,哎毕竟自己的笔记本年迈无力,把迭代次数设置为1次,先跑出个结果再看看吧。最终,历时两个多小时,总算是跑完了。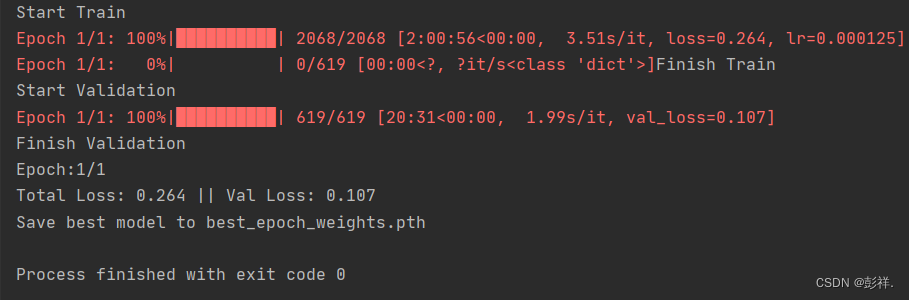
当我们迭代30次时,到第10次时出现错误:
RuntimeError: Caught MemoryError in DataLoader worker process 1.
关于第一个错误,提到是由于torch的DataLoader,是启用多线程(num_workers!=0)提示哪个线程有问题,因为batch合并时维度不一样,导致第一个线程就挂了(worker process 0),所以会提示RuntimeError: Caught RuntimeError in DataLoader worker process 0.
这时我们只需要将num_workers=2改为num_workers=0即可,但个人认为并不是由于这个导致的,毕竟之前已经迭代了多次了。同时也报了如下错误,博主认为是这个原因导致,即性能不足,呜呜呜
numpy.core._exceptions._ArrayMemoryError: Unable to allocate 1.17 MiB
for an array with shape (640, 640, 3) and data type uint8
最主要的还是电脑内存不足,因为需要处理的数据量太大,GPU性能不够,存在内存溢出现象。
训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。我们首先需要去yolo.py里面修改model_path以及classes_path,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
"model_path":'logs/last_epoch_weights.pth',"classes_path":'model_data/voc_classes.txt',

注意事项
文件类别和权重一定要对应好,我们训练时的类别为voc类型,而默认的权重及类别为coco类型,否则会报错:
RuntimeError: Error(s)in loading state_dict for YoloBody:
size mismatch for yolo_head3.1.weight: copying a param with shape torch.Size([75,256,1,1])from checkpoint, the shape in current model is torch.Size([255,256,1,1]).
size mismatch for yolo_head3.1.bias: copying a param with shape torch.Size([75])from checkpoint, the shape in current model is torch.Size([255]).
size mismatch for yolo_head2.1.weight: copying a param with shape torch.Size([75,512,1,1])from checkpoint, the shape in current model is torch.Size([255,512,1,1]).
size mismatch for yolo_head2.1.bias: copying a param with shape torch.Size([75])from checkpoint, the shape in current model is torch.Size([255]).
size mismatch for yolo_head1.1.weight: copying a param with shape torch.Size([75,1024,1,1])from checkpoint, the shape in current model is torch.Size([255,1024,1,1]).
size mismatch for yolo_head1.1.bias: copying a param with shape torch.Size([75])from checkpoint, the shape in current model is torch.Size([255]).
当然你也可以之间使用我们之前下载好的权重文件,运行predict.py后输入图片路径即可,这里我们可以改为循环输入多张图片来进行预测。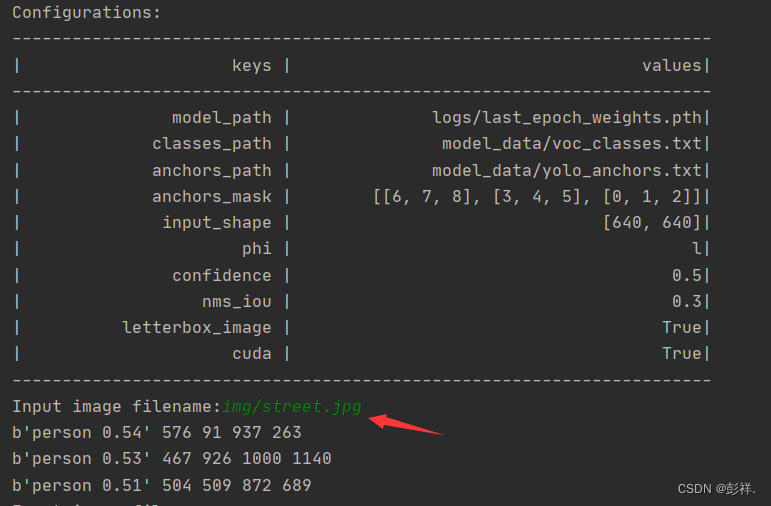
这是使用原权重文件的结果: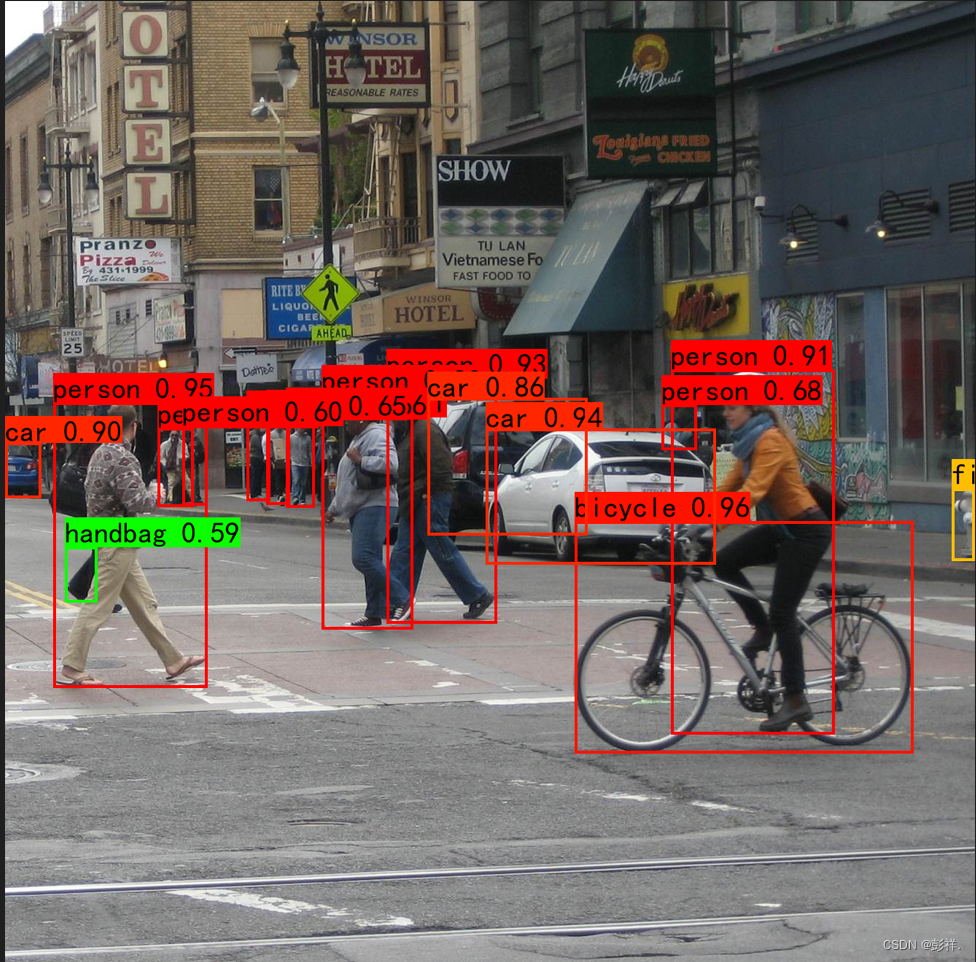
完成修改后就可以运行predict.py进行检测了。
然后我们替换自己训练的权重与类别文件后结果如下:可以看出两者差别还是蛮大的,其中一个重要原因当然是博主训练次数太少以致于没有很好的泛化。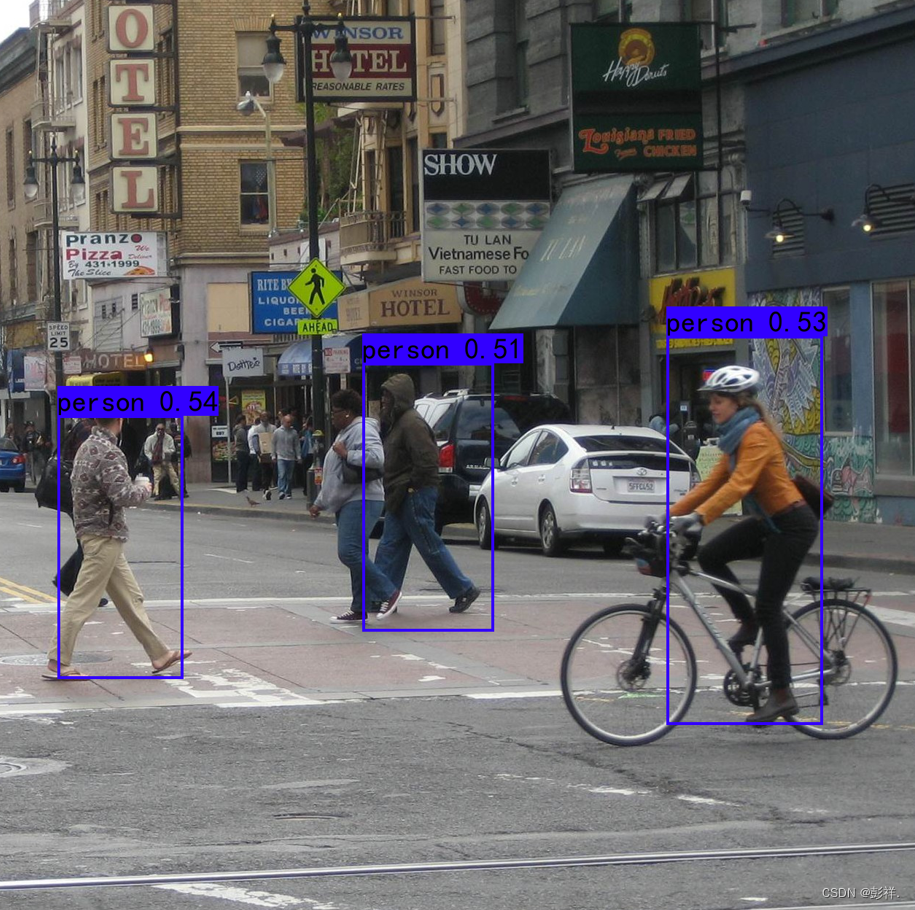
至此我们的训练与预测便调试通过了,接下来我们再看看代码中的其他功能
改进为循环:
path ='D:/python2022/data'
path_1 ='D:/python2022/out'for filename in os.listdir(path):# if filename.endswith('.bmp'): #代表结尾是bmp格式的
img_path = path +'/'+ filename
image = Image.open(img_path)
r_image = yolo.detect_image(image, count=count, crop = crop)
out_name = filename.split('.')[0]
save_name = path_1 +'/'+ out_name +'.png'
r_image.save(save_name)
原图片:
检测后:

网络模型结构
项目中提供了summary.py来查看模型结构:
运行summary时发现缺包,下载即可:
pip install thop -i https://pypi.tuna.tsinghua.edu.cn/simple
再次运行,输出其模型结构,这里只展示其数据大小,感兴趣的同学可以自行查看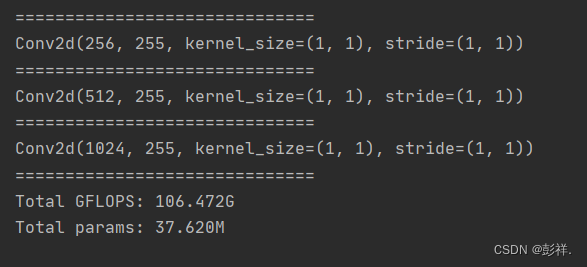
可以看到其模型十分复杂。关于YOLOV7的模型与原理解读,博主会再进行介绍。
至此,我们关于YOLOV7模型的调试就先到这里了,之后我们会考虑在此模型上进行改进提升其性能,并将其与目标追踪算法相结合来完成目标检测跟踪实验。
版权归原作者 彭祥. 所有, 如有侵权,请联系我们删除。