
前言
上期我们引入了一个目标检测的模型,并对其所需的环境配置进行了搭建。这期主要针对项目如何运行以及运行过程中的常见报错进行记录以及分享,毕竟报错在深度学习的环境搭建也是很常见的嘛,如何解决报错问题还是很有必要去分析以及学习的。
1.准备工作
本期项目源码以及环境搭建可以参考我的上期博客:
Pytorch搭建yolov5目标检测环境配置_yutu-7的博客-CSDN博客https://blog.csdn.net/m0_73414212/article/details/129770438软件配置可以参考文章(我用的是VScode以及Anaconda):
vscode以及Anaconda安装以及相关环境配置_vscode配置anaconda环境_yutu-7的博客-CSDN博客https://blog.csdn.net/m0_73414212/article/details/129704221
项目训练数据集(所用为voc数据集)可以通过网盘资源获取:
链接:百度网盘 请输入提取码 提取码: j5ge
训练所需的权值可在百度网盘中下载: 链接: 百度网盘 请输入提取码 提取码: 3mjs
上述相关资源包获取之后,我们先打开voc数据集,也就是VOC07+12+test文件夹,一路点开到VOC2007文件夹下,我这里的路径是:F:\VOC07+12+test\VOCdevkit\VOC2007:
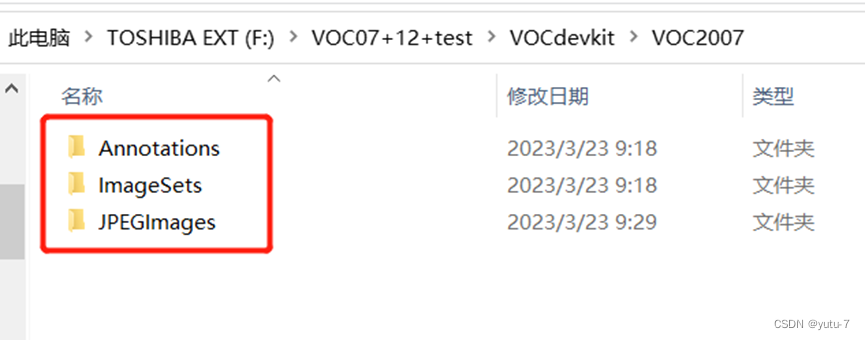
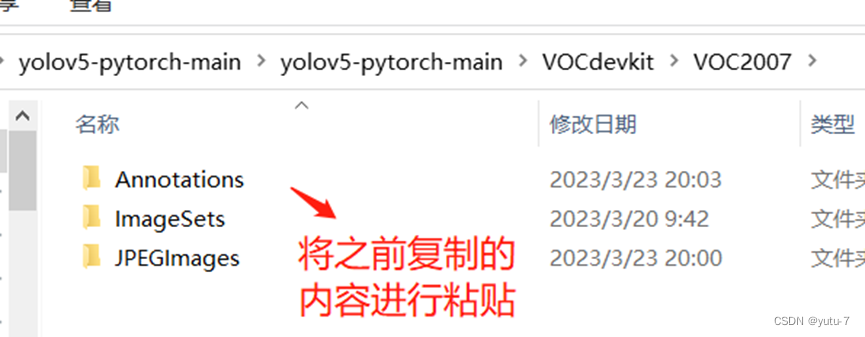
将这里对应的三个文件复制,然后回到源码文件中的yolov5-pytorch-main\yolov5-pytorch-main\VOCdevkit\VOC2007路径下,因为我是直接利用的下载安装包的方式获取的源文件,如果是git clone的 方式的话,路径应该是:yolov5-pytorch\VOCdevkit\VOC2007,打开会出现同样名字的三个文件夹,直接粘贴替代原文件就可以了:
然后我们将训练的权值文件进行复制,然后粘贴到yolov5-pytorch-main\yolov5-pytorch-main\model_data路径下:

我们这里训练的时候采用的是yolov5_s,如果你想要取得更好的效果,可以选择yolov5_x,但是相对应的训练时间会加长,并且比较吃显存。
2.运行过程
2.1打开项目文件
首先我们需要利用vscode打开项目文件夹的根目录,这个是很重要的,如果你打开的不是根目录,同样会出现源码,但是在运行的时候会出现找不到相应模块的错误。如果你是利用下载安装包的方式获取的源码,那么根目录指代的是yolov5-pytorch-main\yolov5-pytorch-main路径下的第二个yolov5-pytorch-main文件目录:

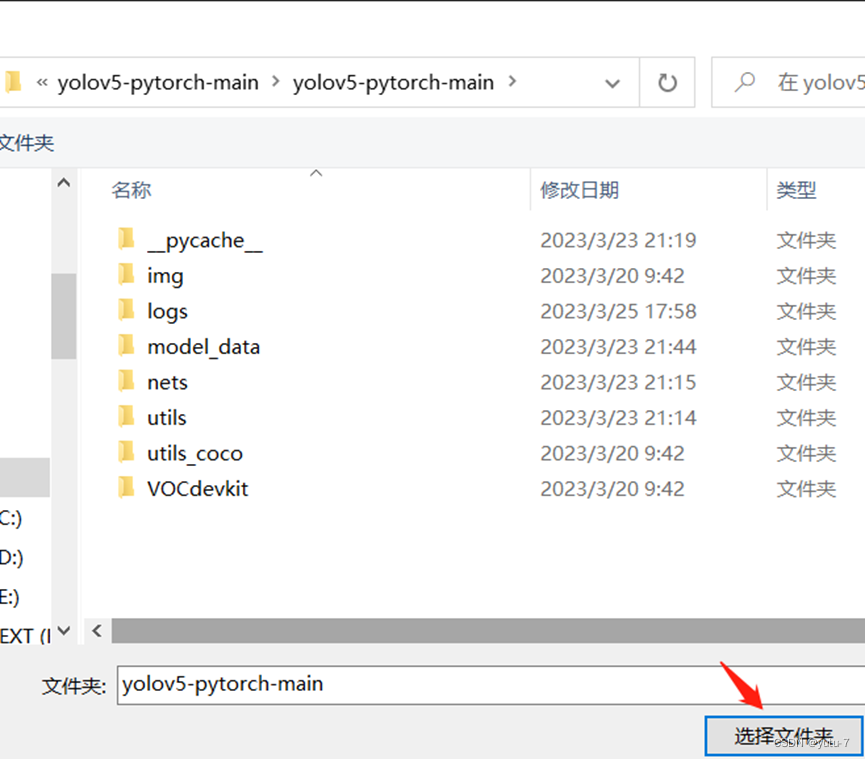
如果是git clone方式的话,对应的第一个yolov5-pytorch文件就是对应的根目录文件啦。
2.2运行voc_annotation.py文件
点开voc_annotation.py文件,将annotation_mode 改为2,这是为了生成训练集以及验证集的标签数据,这里的数值为0的时候会进行整个数据集的划分并且生成相应的标签数据,为1的时候只会进行数据集的划分,因为我们这里已经提前将数据集划分好了,所以就直接生成标签数据就好啦:

数据集的划分情况可以从yolov5-tf2-main\VOCdevkit\VOC2007\ImageSets\Main进行查看:

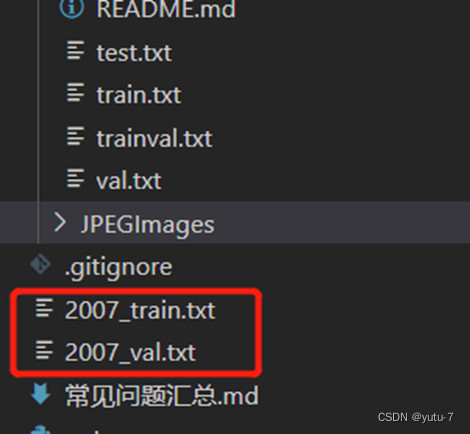
最终根目录下会生成2007_train.txt 以及2007_val.txt文件:
2.3运行train.py文件
然后运行train.py文件,如果你用的数据集和我一样是官方数据集,那么这里不需要修改,直接运行就可以了,至于运行过程中出现的报错以及解决方案,我们待会再说:

训练过程中在根目录下的logs文件夹下会保存训练过程中所获得的权重,当训练达到100%时可以利用最后产生的权重文件对目标图形进行检测:

另外在运行过程中切换到任务管理器,点击性能,将GPU设置为cuda可以看到训练过程中gpu的占用情况:

2.4运行predict.py文件
运行之前需要先返回到yolo.py文件中,去修改model_path以及classes_path相关路径,这里model_path对应的model_data/yolov5_s.pth为预测所需的权值文件,可以用最后训练的权值数据代替,比如假设logs/ep096-loss0.075-val_loss0.054.pth:
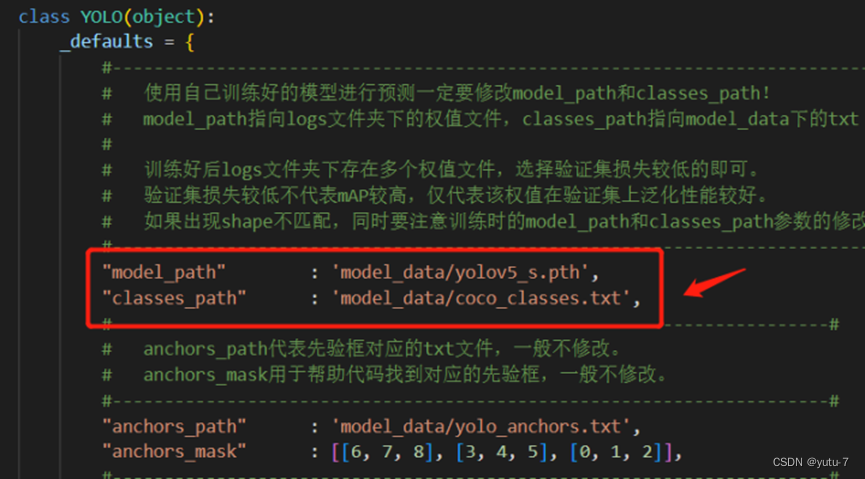
然后classes_path对应的model_data/coco_classes.txt为所要识别的种类类型,打开coco_classes.txt里面识别的类型有20种:

这取决于你想要识别的目标种类是什么,比如你只想识别人以及车,那么你可以在model_data文件夹下创立一个clss.txt文件,再将person以及car输入进去并且保存,用这个路径即model_data/clss.txt代替coco_classes.txt:

当然如果恰巧你识别的内容和上面20种类别一样,并且你不想进行训练,你可以使用提供好的权值文件而不做任何更改,也就是不需要进行上面的操作,最终的预测也能得到不错的结果。
之后就可以返回predict.py文件中进行预测了,运行程序后:
Configurations:
----------------------------------------------------------------------
| keys | values|
----------------------------------------------------------------------
| model_path | model_data/yolov5_s.pth|
| classes_path | model_data/coco_classes.txt|
| anchors_path | model_data/yolo_anchors.txt|
| anchors_mask | [[6, 7, 8], [3, 4, 5], [0, 1, 2]]|
| input_shape | [640, 640]|
| backbone | cspdarknet|
| phi | s|
| confidence | 0.5|
| nms_iou | 0.3|
| letterbox_image | True|
| cuda | True|
----------------------------------------------------------------------
Input image filename:
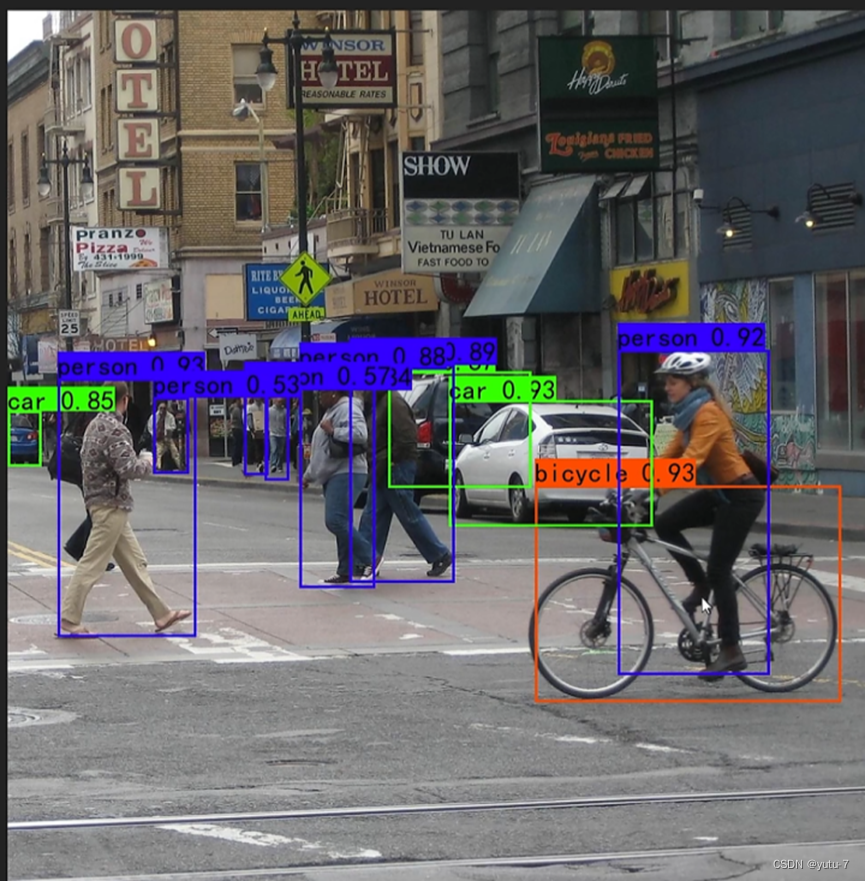
输入img\street.jpg对街景图片进行识别:
Input image filename:img\street.jpg
b'person 0.90' 550 69 940 279
b'person 0.88' 506 913 994 1144
b'person 0.87' 519 508 854 671
b'person 0.80' 540 438 858 545
b'person 0.78' 566 384 697 424
b'person 0.53' 580 208 693 262
b'person 0.51' 560 331 690 372
b'bicycle 0.90' 714 781 1029 1250
b'car 0.86' 585 657 771 964
b'car 0.81' 610 1 678 49
b'car 0.69' 544 584 718 797
如果你觉得这个图片识别不太符合你的预期效果,有的IoU比较小的目标不希望被检测出来以避免识别框到处都是,那么你可以通过非极大值抑制的方式提高IoU的识别阈值,在代码中可以返回到yolo.py文件修改nms_iou的值来实现,原来的值是0.3,现在改为0.01再试试:


发现很多重合度小的目标都被抑制掉了。
3.运行过程中的常见报错以及解决方案
3.1算力不支持报错
UserWarning:
NVIDIA GeForce RTX 3060 with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
If you want to use the NVIDIA GeForce RTX 3060 GPU with PyTorch, please check the instructions at PyTorch
出现这类错误是因为你所安装的cuda版本太低,对于30显卡来说,需要将cuda版本安装在11.0以上。
3.2no module问题
ModuleNotFoundError: No module named ‘tensorboard‘
这里的话如果按照requirements文件中的环境配置过来的话确实少了这样的一个模块,我们返回到torch环境下安装这个软件包就行了,不需要指定版本:
(torch) C:\Users\Hasee>pip install tensorboard
如果还有其他模块错误问题比如:
no module name utils.utils、no module named 'matplotlib'
出现这个问题的原因是根目录不对,我在上面已经提到过,看了就明白了。
3.3no attribute问题
AttributeError: 'numpy.ndarray' object has no attribute 'split'
TypeError: cat() got an unexpected keyword argument 'axis',Traceback (most recent call last),AttributeError: 'Tensor' object has no attribute 'bool'
出现这种问题一般是因为没有按照指定版本来安装,重新指定版本安装即可。
3.4RuntimeError
RuntimeError: CUDA out of memory.
出现这种原因其实是因为显存被限制了,不一定是因为显存不足。
可以尝试减小batch_size的大小,但是要保证是2的倍数,也就是最小得保证是2。
如果还无法解决可以通过增加虚拟内存的方式解决,具体方式为:
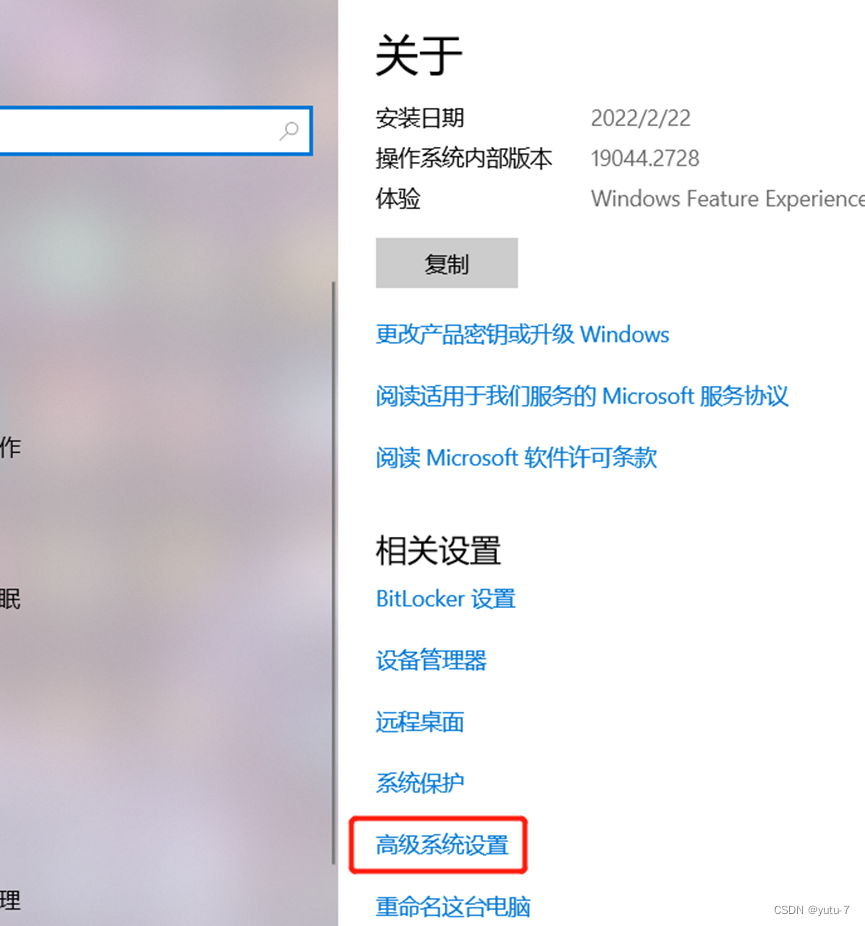
点击高级系统设置:
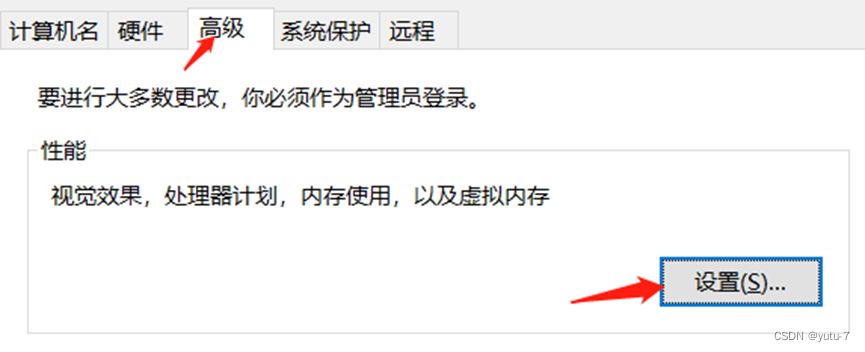
点击高级,再点击性能中的设置:
再点击高级,点击虚拟内存中的更改:
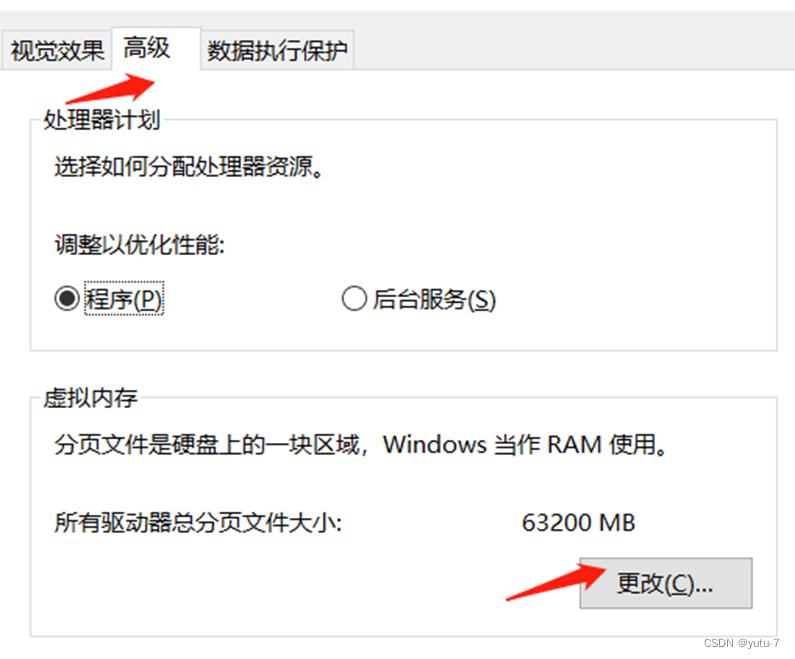
如果你的环境是设立在d盘的,可以增加d盘的虚拟内存,尽量设置大点,不用在意你电脑的实际显存多大,在这里我足足设置了50G:

如果设置后提示需要重启电脑才能生效就重启。
另外如果你在跑项目的时候还打游戏或者是还跑着其他的项目,那么这时候可以通过命令nvidia-smi查看显存的占用情况:

如果对应的值太大的话,可以终止一些进程释放显存,就比如我要释放PID为836的进程,可以输入:
taskkill -PID 836 -F
回车后:
(base) C:\Users\Hasee>taskkill -PID 836 -F
成功: 已终止 PID 为 836 的进程。
再次输入nvidia-smi:
(base) C:\Users\Hasee>nvidia-smi
回车后:
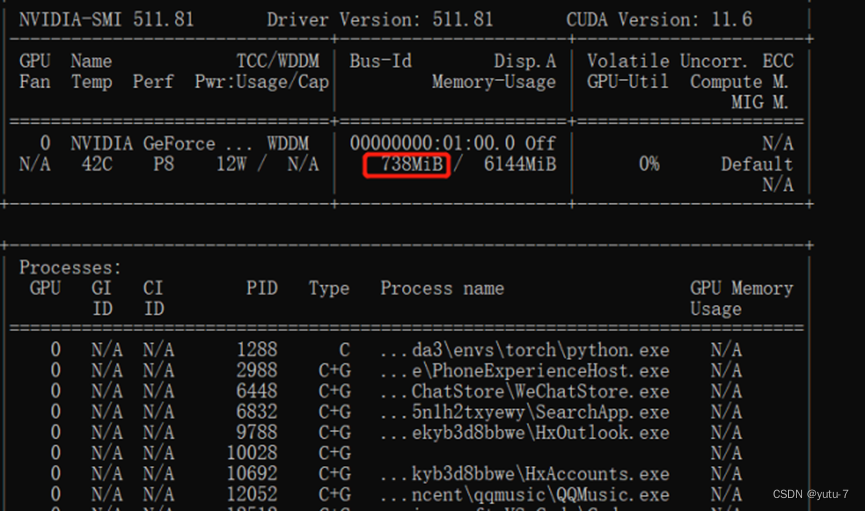
显存占用减少了40,当然这些小进程没必要取消,但当你的显存即将爆满时利用命令终止一些大进程所取得的效果立竿见影。
3.5cuDNN error
cuDNN error:CUDNN_STATUS_INTERNAL_EPPOR
这里出现的原因为pytorch版本与cuda版本不对应,安装的时候进入pytorch官网安装对应torch版本就行了。
版权归原作者 yutu-7 所有, 如有侵权,请联系我们删除。