【人工智能】LLM 大型语言模型和 Transformer 架构简介
然而,传统的机器学习模型,例如神经网络,并不能天生理解输入的顺序。通过将位置编码纳入 Transformer 架构,GPT 可以更有效地理解句子中单词的顺序,并生成语法正确且语义有意义的输出。但是,模型只能理解数字,不能理解文本,因此需要将这些输入转换为称为“输入嵌入”的数字格式。作为初创公司的首席
Ubuntu20.04LTS安装CUDA并支持多版本切换
由于我工作站(Ubuntu 20.04 LTS)的英伟达驱动版本为520.61.05,从上图可以看出,我最高可以安装的CUDA版本为11.8.x。(注:CUDA 12.0.x和CUDA 12.1.x都要求英伟达驱动版本大于等于525.60.13,因此我的520.61.05不符合,所以我最高只能安装C
【人工智能概论】 K折交叉验证
K折交叉验证

使用QLoRA对Llama 2进行微调的详细笔记
本文是一个良好的开端,因为可以把我们在这里学到的大部分东西应用到微调任何LLM的任务中。
【人工智能的数学基础】函数的光滑化(Smoothing)
综上所述,需要对非光滑函数进行光滑近似的方法。本文首先对函数的光滑化进行定义,并介绍几种对函数进行光滑化的方法。光滑函数(smooth function)是指在其定义域内无穷阶数连续可导的函数。函数的光滑化是指对于一个非光滑函数fff,寻找一个光滑函数fμf_{\mu}fμ,使得fμf_{\mu}
Stability AI发布基于稳定扩散的音频生成模型Stable Audio
Stability AI的Stable Audio AI模型标志着人工智能驱动的听觉创造力的重大飞跃。它为音乐和声音爱好者打开了新的视野。在未来还会提供进一步增强模型、数据集和训练技术的体系结构,发布基于Stable Audio的开源模型,并将提供必要的代码,以方便定制音频内容生成模型的训练。
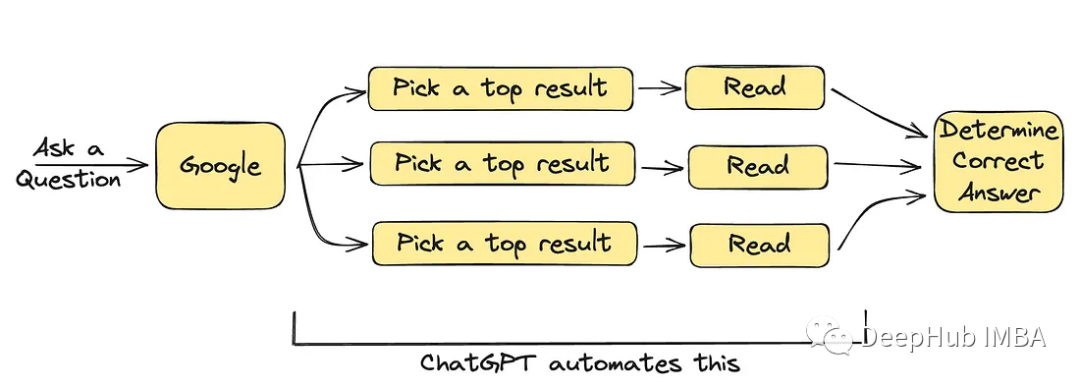
ChatGPT可以取代搜索引擎吗?
ChatGPT对于一些简单的问题,可以完美的完成任务。但是我让它写一篇完整的文章,看看它能否代替我进行写作地的时候,我确定它不能完全取代人类。
【DL】2023年你应该知道的 10 大深度学习算法
它们是训练有素的神经网络,可将数据从输入层复制到输出层。它们具有相同数量的输入和输出层,但可能有多个隐藏层,可用于构建语音识别、图像识别和机器翻译软件。无论您是初学者还是专业人士,这三大深度学习算法都将帮助您解决与深度学习相关的复杂问题:CNN 或卷积神经网络、LSTM 或长短期记忆网络和 RNN
Anaconda安装教程
Anaconda安装教程
Torch中常见插值方式及各自的优缺点
插值指的是利用已知数据去预测未知数据,图像插值则是给定一个像素点,根据它周围像素点的信息来对该像素点的值进行预测。当我们调整图片尺寸或者对图片变形的时候常会用到图片插值。常见的插值算法可以**分为两类**:**自适应和非自适应**。 自适应的方法可以根据插值的内容来改变(尖锐的边缘或者是平滑的纹理)
Yolov5改进: Yolov5-FasterNet网络推理加速
FasterNet是CVPR 2023 新出来的网络,主要用来加速网络推理实现轻量化。作者重新审视了现有的操作符,特别是DWConv的计算速度——FLOPS。作者发现导致低FLOPS问题的主要原因是频繁的内存访问。然后,作者提出了PConv作为一种竞争性替代方案,它减少了计算冗余以及内存访问的数量。
免费部署一个开源大模型 MOSS
MOSS 的公开无异于宣告与百度对话模型的“正面竞争”,这场人工智能的“决战”注定轰动一时。未来几个月, ChatGPT 式对话产品将在中国大行其道,而 MOSS 和“文心一言”的 PK 则成为行业和公众最关心的话题。这场竞赛的结果,将对中国在人工智能领域的地位产生重大影响。人工智能时代的创新,正在
Pytorch查看GPU信息
GPU,Torch,Cuda
DenseNet网络详解及Pytorch实现
DenseNet是由Gao Huang等研究人员于2017年提出的一种深度神经网络架构。DenseNet的主要思想是在网络的每一层之间建立密集的连接,这种密集连接的结构使得网络在训练过程中可以更好地传播梯度信息,有效地缓解了梯度消失问题。DenseNet在图像分类、物体检测等计算机视觉任务中取得了出
深度学习模型复杂度评估(时间复杂度、空间复杂度)
由于维度灾难的限制,模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,这会导致模型的训练更容易过拟合。时间复杂度和空间复杂度是衡量一个算法的两个重要指标,用于表示算法的最差状态所需的时间增长量和所需辅助空间.如果复杂度过高,会导致模型训练和预测耗费大量时间,既无法快速的验
Latent Diffusion Models
详细解读Latent Diffusion Models:原理和代码
pytorch性能分析工具Profiler
PyTorch Profiler 是一个开源工具,可以对大规模深度学习模型进行准确高效的性能分析。分析model的GPU、CPU的使用率各种算子op的时间消耗trace网络在pipeline的CPU和GPU的使用情况Profiler利用可视化模型的性能,帮助发现模型的瓶颈,比如CPU占用达到80%,
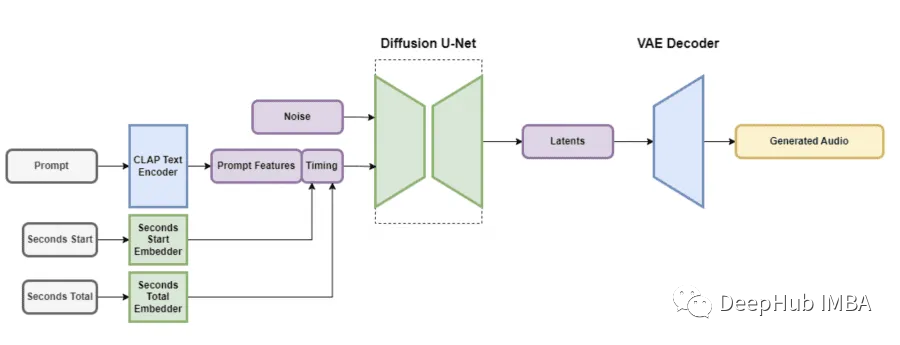
Stability AI发布基于稳定扩散的音频生成模型Stable Audio
近日Stability AI推出了一款名为Stable Audio的尖端生成模型,该模型可以根据用户提供的文本提示来创建音乐。
基于CNN-Transformer时间序列预测模型
基于CNN-Transformer时间序列预测模型
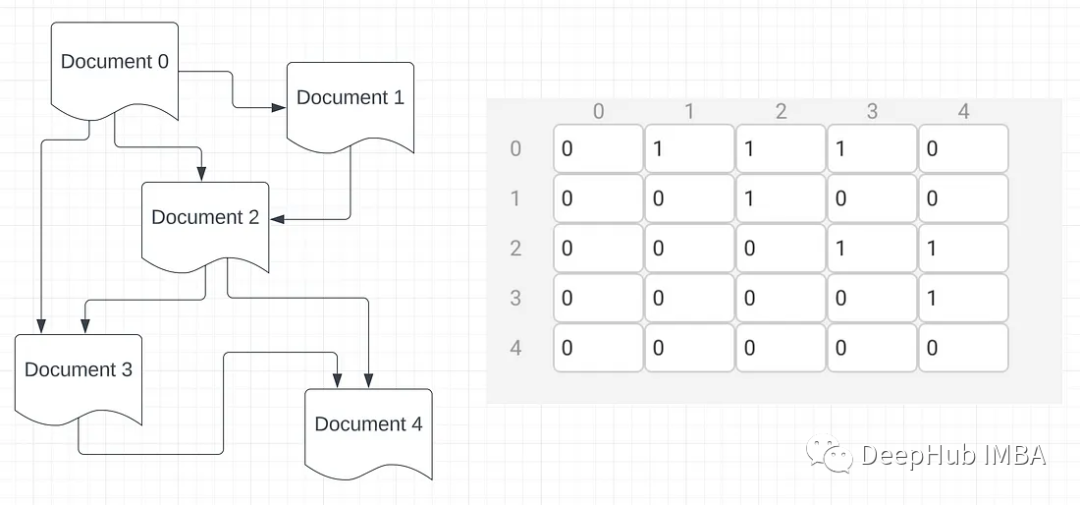
图注意网络(GAT)的可视化实现详解
能够可视化的查看对于理解图神经网络(gnn)越来越重要,所以在这篇文章中,我将介绍传统GNN层的实现,然后展示ICLR论文“图注意力网络”中对传统GNN层的改进。



