
1. 概述
基于ViT(Vision Transformer)自监督在最近几年取得了很大进步,目前在无监督分类任务下已经超过了之前的一些经典模型,同时在检测分割等基础任务领域也展现出了强大的泛化能力。这篇文章将主要基于DINO系列自监督算法介绍它们的算法原理,方便 大家快速了解相关算法。
2. DINO-v1
参考代码:dino
这个方法源自于一个很重要的发现,自监督的ViT在图像语义分割的显式信息表达上具有独特性,也就是说相比有监督的ViT网络或者是传统的CNN网络其具有更强的语义表达能力和分辨能力。基于此使用k-NN算法作为分类器便能在一个较小的ViT网络上实现78.3% ImageNet top-1的准确率。在该方法中构建自蒸馏的方式训练和更新教师和学生网络,同样也适用了参数类似滑动平均更新和输入图像多重裁剪训练策略。对于训练得到的网络对其中的attention map进行可视化,确实也呈现出了上述提到的物体语义区域的感知能力,见下图可视化效果:
整体上文章提出的方法pipeline见下图所示: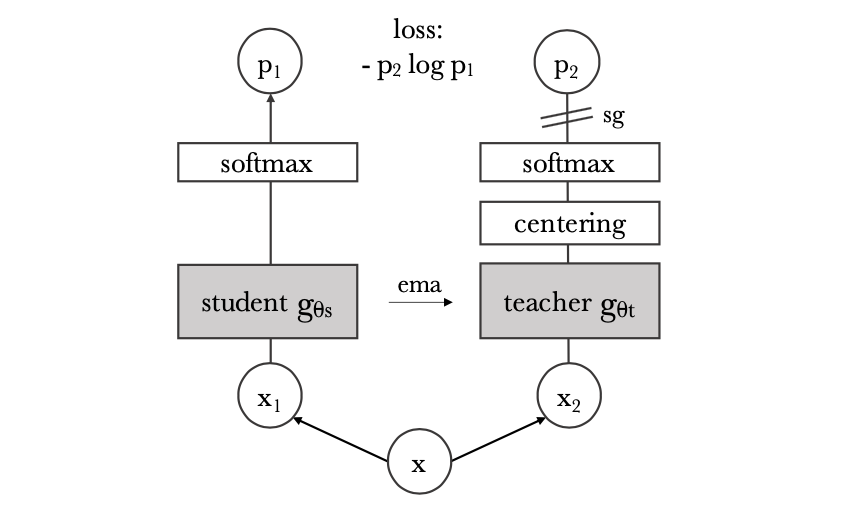
在上图中包含了两个相同结构的网络
本文转载自: https://blog.csdn.net/m_buddy/article/details/130676016
版权归原作者 m_buddy 所有, 如有侵权,请联系我们删除。
版权归原作者 m_buddy 所有, 如有侵权,请联系我们删除。