PointPillars 工程复现
PointPillars 工程复现, 学习并复现PointPillars,解决部署时遇到的各类问题。
tensorflow如何使用gpu
tensorflow查看GPU的数量、使用GPU加速,单GPU模拟多GPU环境等
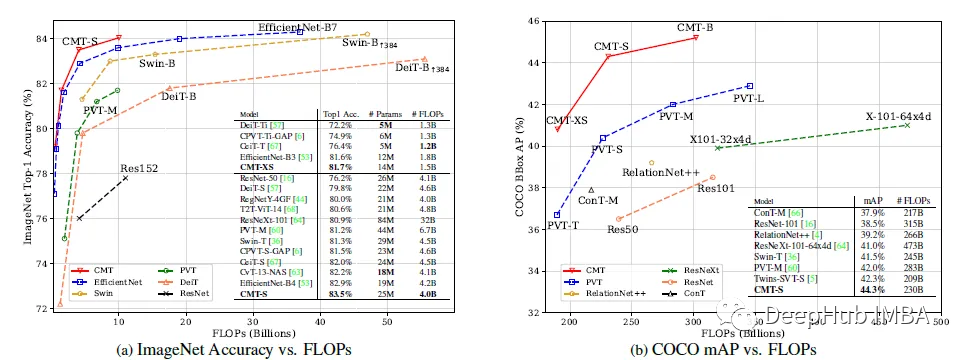
CMT:卷积与Transformers的高效结合
论文提出了一种基于卷积和VIT的混合网络,利用Transformers捕获远程依赖关系,利用cnn提取局部信息。构建了一系列模型cmt,它在准确性和效率方面有更好的权衡。
特定场景小众领域数据集之——焊缝质量检测数据集
特定场景小众领域数据集之——焊缝质量检测数据集
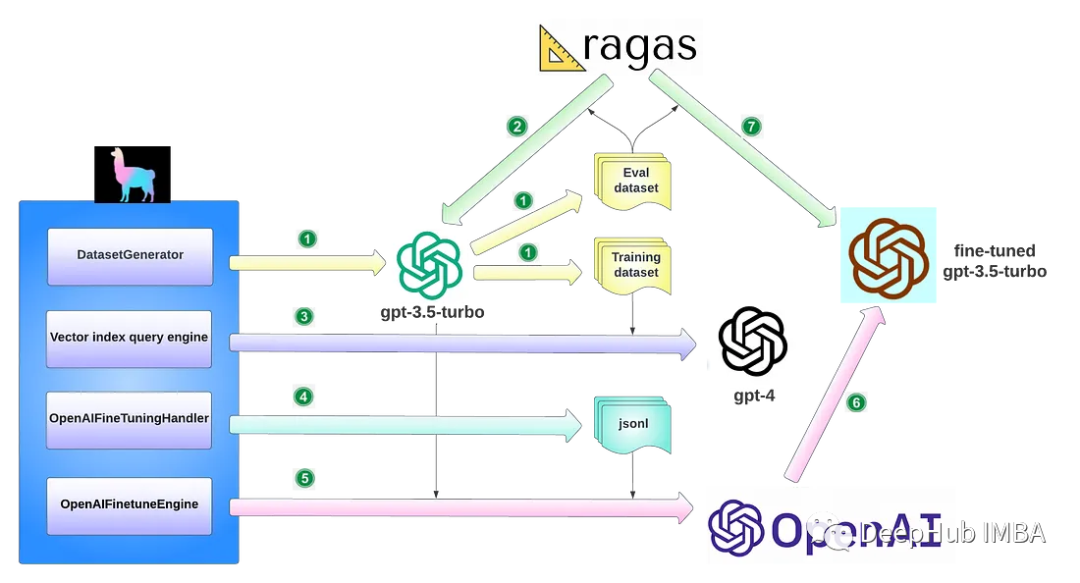
使用GPT-4生成训练数据微调GPT-3.5 RAG管道
我们现在可以使用GPT-4生成训练数据,然后用更便宜的API(gpt-3.5 turbo)来进行微调,从而获得更准确的模型,并且更便宜。
生成模型之VAE与VQ-VAE
有关图像处理的课程作业需要学习一篇论文,此论文中作者使用了VQ-VAE模型对舞蹈动作进行编码。因此,对相关知识略作整理以供之后查找。AE、VAE和VQ-VAE可以统一为latent code的概率分布设计不一样,AEr通过网络学习得到任意概率分布,VAE设计为正态分布,VQVAE设计为codeboo
深度学习入门——深度卷积神经网络模型(Deep Convolution Neural Network,DCNN)概述
机器学习是实现人工智能的方法和手段,其专门研究计算机如何模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构使之不断改善自身性能的方法。计算机视觉技术作为人工智能的一个研究方向,其随着机器学习的发展而进步,尤其近10年来,以深度学习为代表的机器学习技术掀起了一场计算机视觉革命。本文
timm使用swin-transformer
swin-transformer
AI 大模型 LLM 的基础概念、核心算法原理数学模型和发展历史及其应用领域
文本摘要是指从大量的文本中提取关键信息,并生成简洁、易于理解的摘要。LLM能够通过对文本进行编码和自动摘要,从而提高文本摘要的质量和效率。总之,LLM是自然语言处理领域中的一个重要组成部分,它通过对大量数据进行训练,实现了自然语言理解、文本分类、机器翻译、文本摘要等多种自然语言处理任务。在未来的发展
人工智能(pytorch)搭建模型12-pytorch搭建BiGRU模型,利用正态分布数据训练该模型
大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型12-pytorch搭建BiGRU模型,利用正态分布数据训练该模型。本文将介绍一种基于PyTorch的BiGRU模型应用项目。我们将首先解释BiGRU模型的原理,然后使用PyTorch搭建模型,并提供模型代码和数据样例。接下来
Coursera吴恩达《深度学习》课程总结(全)
01 神经网络和深度学习(Neural Networks and Deep Learning)1-1 深度学习概论主要介绍:主要对深度学习进行了简要概述。首先,我们使用房价预测的例子来建立最简单的单个神经元组成的神经网络模型。然后,我们将例子复杂化,建立标准的神经网络模型结构。接着,我们从监督式学习
注意力机制——ECANet及Mobilenetv2模型应用
SENet、ECA-Net的Mobilenetv2嵌入
[点云学习] 一、点云相关知识了解
点云是一种表示三维空间中对象的数据结构,它由许多离散的点组成。每个点都有自己的位置坐标和可能的其他属性,如颜色、法向量和强度等。点云通常由激光扫描仪、相机或其他传感器捕获,用于创建三维模型、地图或进行遥感分析。在计算机视觉和机器学习领域,点云也被广泛应用于目标检测、物体识别、3D重建和虚拟现实等方面
sparse conv稀疏卷积
"""Args:"""self.features = features # 储存密集的featureself.indices = indices # 储存每个feature对应的voxel坐标系下的坐标self.spatial_shape = spatial_shape #存储voxel的最大边界s
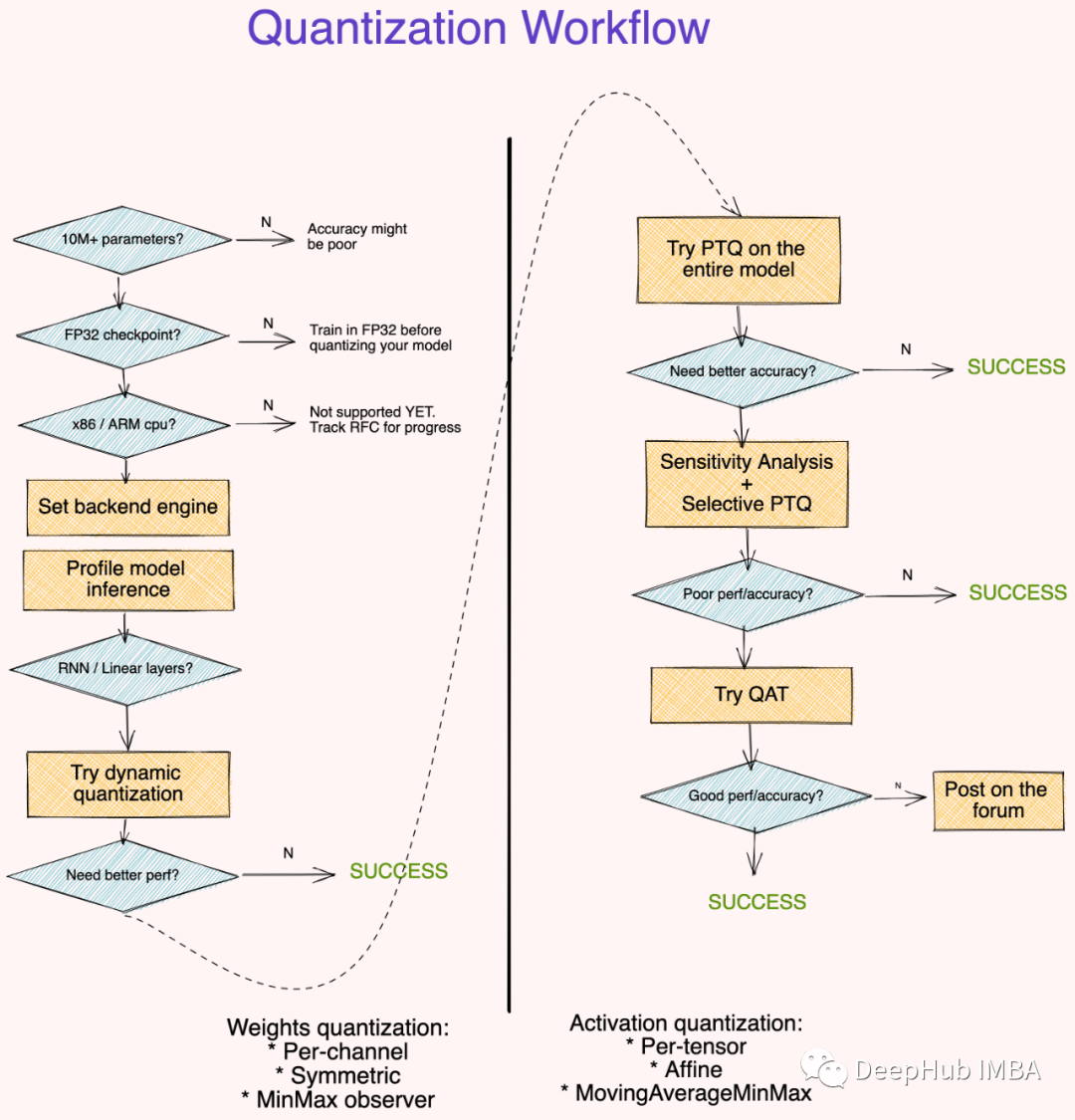
量化自定义PyTorch模型入门教程
基础模型与量化模型具有相似的准确性,但模型尺寸大大减小,这在我们希望将其部署到服务器或低功耗设备上时至关重要。
NeRF必读:Mip-NeRF总结与公式推导
由于远景近景的分辨率不同,导致经典NeRF对于多尺度场景的表达存在明显瑕疵:NeRF对于近景的重建比较模糊而对于远景的重建出现锯齿。简单粗暴的策略是supersampling,但是费时费力。相较于NeRF使用的位置编码(PE)方式,Mip-NeRF提出了积分位置编码的方式(IPE).这种编码方式可以
CV 经典主干网络 (Backbone) 系列: CSP-Darknet53
CSP-Darknet53无论是其作为CV Backbone,还是说它在别的数据集上取得极好的效果。与此同时,它与别的网络的适配能力极强。
openai的 ada,Babbage,Curie,Davinci模型分别介绍一下
具体来说,175亿个参数是指Davinci模型中的参数数量,该模型使用了一个大型的变压器(transformer)神经网络,该神经网络由多个Transformer encoder和decoder层组成。Ada:Ada是OpenAI推出的最新模型,它是一种大规模的、多任务的语言模型,能够执行多种不同的
监督学习、半监督学习、无监督学习、自监督学习、强化学习和对比学习
监督学习、半监督学习、无监督学习、自监督学习、强化学习和对比学习

20用于深度学习训练和研究的数据集
本文将整理常用且有效的20个数据集。



