
© 2022 Uriel Singer et al (Meta AI)
© 2023 Conmajia
本文基于论文 Make-A-Video: Text-to-Video Generation without Text-Video Data(2209.14792)。
本文已获论文第一作者 Uriel Singer 授权。

本视频由这句话生成:穿着超人装和红色披风的狗狗飞过天空
摘要 我们提出了 Make-A-Video(造啊视频),一种直接将最近在文生图(T2I)方面取得的巨大进展转化为文生视频(T2V)的方法。我们的方式很简单:从配对的文字图片数据中了解世界的样子以及它是如何被描述的,从无监督的视频片段中了解世界是如何运动的。Make-A-video 有三个优点:(1) 它加快了 T2V 模型的训练过程(无需从头学习视觉和多模态表示);(2) 它不需要配对的文字视频数据;(3) 生成的视频继承了当今图片生成模型的广博性(美学多样性,幻想描绘等)。我们设计了一种简单而有效的方法,在 T2I 模型上建立了新颖有效的时空模块。首先,我们分解全时间 U-Net 张量和注意力张量,并在空间和时间上逼近它们。其次,我们设计了一个时空管道来生成高分辨率和帧率视频,其中包含一个视频解码器、插值模型和两个超分辨率模型,可以支持包括 T2V 在内的各种应用。在空间和时间分辨率、文字符合度和视频质量等方面进行定性和定量的测量之后,我们相信 Make-A-Video 足以称为目前最先进的文生视频技术。
以下为正文。
1 简介
互联网使人们拥有了从 HTML 页面中收集数以十亿计的如
[替换文字,图片]
这样成对数据的能力,使得最近在文字转图片(T2I,文生图)建模方面取得了长足进步。然而对视频而言,要想(通过成对数据)复制这种成功其收益是有限的,因为迄今还没有办法可以轻松收集相似规模的
[文字,视频]
这种数据集。当市面上已经存在可以生成图片的模型时,从头训练文字转视频(T2V,文生视频)模型不啻为一种浪费。此外,运用无监督学习(即采用无标签的数据)可使网络从更多的数据中学习。大量的数据对于学习微妙的、不常见的概念表达非常重要。长期以来,无监督学习在推动自然语言处理(NLP)领域取得了巨大成功。以这种方式预训练的模型比以有监督方式单独训练的模型产生的性能要高得多。
受此启发,我们提出了 Make-A-Video(造啊视频)。Make-A-Video 利用了 T2I 模型来学习文字和视觉世界之间的对应关系,并对未标记(未配对)的视频数据使用无监督学习方法来学习真实物体的运动。Make-A-Video 可以在不使用
[文字,视频]
这种配对数据的情况下从文字直接生成视频。显然,描述图片的文字不可能(也不需要)捕捉到视频中观察到的全部景象。即是说,人们通常可以从静态图片中——例如喝咖啡的妇女,或踢足球的大象——推断物体的动作和事件,就像在基于图片的动作识别系统中所做的那样。此外,即使没有文字描述,无监督视频也足以学习世界上不同的实体如何移动和交互——例如海滩上的波浪或大象鼻子的运动。我们发现只见过描述图片文字的模型在生成短视频方面效率惊人,如基于时间扩散的方法所示。Make-A-Video 开创了 T2V 时代的新技术。

图 1. T2V 生成样张。我们的模型可以为一系列不同的视觉概念生成具有连贯动作的高质量视频。在样张 (a) 中,视频中的狗有较大而真实的动作。在样张 (b) 中,书本几乎是静止的,但是整个场景随着摄像机的运动而变化。视频样张可以在 make-a-video.github.io 上访问。
我们使用函数保持转换在模型初始化阶段扩展了空间层,以包括时间信息。扩展的时空网络包括新的注意力模块,从视频集合中学习时间动态。该程序通过将先前训练过的 T2I 网络中的知识瞬间转移到新的 T2V 网络中,极大地加快了 T2V 训练过程。为了提高视觉质量,我们训练了空间超分辨率模型和帧插值模型。这增加了生成视频的分辨率,并实现了可控的更高帧速率。
我们的主要贡献是:
- 我们提出了 Make-A-Video:一种通过时空因子扩散模型扩展基于扩散的 T2I 模型到 T2V 的有效方法。
- 我们利用联合文字图片先验来绕过对于成对文字-视频数据的需求,从而可以扩展到更大数量的视频数据。
- 我们提出空间和时间上的超分辨率策略,在用户提供的文字输入的情况下,首次生成高清晰度、高帧率的视频。
- 我们将 Make-A-Video 与现有的 T2V 系统进行了评估,并提出:(a) 最先进的定量和定性测量结果,以及 (b) 比 T2V 现有文献更彻底的评估。我们还收集了一个包含 300 个提示的测试集,用于零样本 T2V 人工评估,计划稍后发布。
2 以前的工作
文字转图片生成。里德发表的方法是最早将无条件生成对抗网络(GAN)用于 T2I 生成的研究之一。后续的 GAN 变种则专注于渐进式生成,或者更优图文对齐。有关 DALL-E 的研究开创性地将 T2I 生成看作是序列到序列的翻译问题,并使用了一个离散变分自动编码器(VQVAE)和变换器来实现。在那之后,不断有新的变种推出。例如,造啊场景(Make-A-Scene)利用语义映射研究了可控的 T2I 生成。趴踢(Parti)则瞄准多元内容生成,通过编码器-解码器的架构和改良的图片令牌器完成功能。另一方面,降噪扩散概率模型(DDPM)成功撬动了 T2I 生成的发展。GLIDE 训练了一个 T2I 和用于层叠式生成的上采样扩散模型。 T2I 生成中广泛采用了 GLIDE 提出的无分类器引导,借此提高图片质量和文字符合度。DALLE-2 利用了 CLIP 隐空间和先验模型。VQ-diffusion 和 stable diffusion 在隐空间而非像素空间中进行 T2I 生成,以提高工作效率。
文字转视频生成。尽管 T2I 生成功能进展显著,但 T2V 生成的进展却大幅滞后,主要有两个原因:缺乏具有高质量文字视频配对的大规模数据集,以及高维视频数据建模的复杂性。一些早期工作主要关注简单领域的视频生成,例如移动的数字或者特定的人物动作。据我们所知,Sync-DRAW 是第一个利用重复注意力的变分自编码器 T2V 生成方法。中科大的 Pan Yingwei 和杜克大学的 Li Yitong 等人也在各自研究中将 GAN 网络从图片生成领域扩展到了 T2V 上。
最近,GODIVA 首次使用 2D VQVAE 和稀疏注意力来支持更加真实的 T2V 生成场景。 NÜWA 扩展了 GODIVA,并在多任务的学习方案中为各种生成型任务提供了统一的表示方法。为了进一步提高 T2V 生成的性能,清华大学的 Hong Wenyi 等人基于已经下马的 CogView-2 项目开发出添加了额外时间注意力的 CogVideo T2I 模型。视频扩散模型(VDM)同时使用了图片和视频数据对用于视频表达的时间-空间进行训练。CogVideo 和 VDM 收集了 10M 的私人文字-视频对用于训练,而我们的工作仅使用开源数据集,使其更容易由大众复现。
利用图片先验生成视频。由于视频建模的复杂性和高质量视频数据收集的挑战,人们自然会考虑利用视频的图片先验知识来简化学习过程。毕竟,图片是只有一帧的视频。在无条件视频生成中,MoCoGAN-HD 将视频生成定义为在预先训练的固定图片生成模型的隐空间内寻找轨迹的任务。在 T2V 生成中,NÜWA 在多任务预训练阶段结合了图片和视频数据集,以提高模型泛化以进行微调。CogVideo 利用预先训练和固定的 T2I 模型用于 T2V 生成,这样只需少量可训练参数,以减少训练期间的内存使用。但是固定的自编码器和 T2I 模型对 T2V 的生成有一定的限制。VDM 的架构可以实现结合了图片和视频的生成方式。然而,他们是从随机视频中随机抽取独立图片作为来源,也未利用大量的文本图片数据集。
Make-A-Video 与这些作品有几个不同之处:首先,我们的架构打破了 T2V 生成中对于文本-视频配对训练样本的依赖。与以前的工作相比,这是一个显著的优势,前者必须限制在很窄的范围,或者需要大规模配对的文本视频数据;其次,我们对 T2I 模型进行了视频生成微调,获得了有效调整模型权重的优势,而不是像 CogVideo 那样冻结权重;第三,我们的成果从之前对视频和 3D 视觉任务的高效架构的工作中获取了灵感,使用伪三维卷积和时间注意力层。这不仅更好地利用了 T2I 架构,而且与 VDM 相比,它还允许更好的时间信息融合。
3 方法
Make-A-Video 包含了三个主要的组件:(i) 用文字图片数据对训练的 T2I 基本模型(见 3.1 节);(ii) 时空卷积和注意力层,用于将网络的砌块(building block)扩展到时间维度上(见 3.2 节);(iii) 时空网络,包括时空层和 T2V 生成所需的另一个关键元素——用于高帧率生成的帧插值网络(见 3.3 节)。
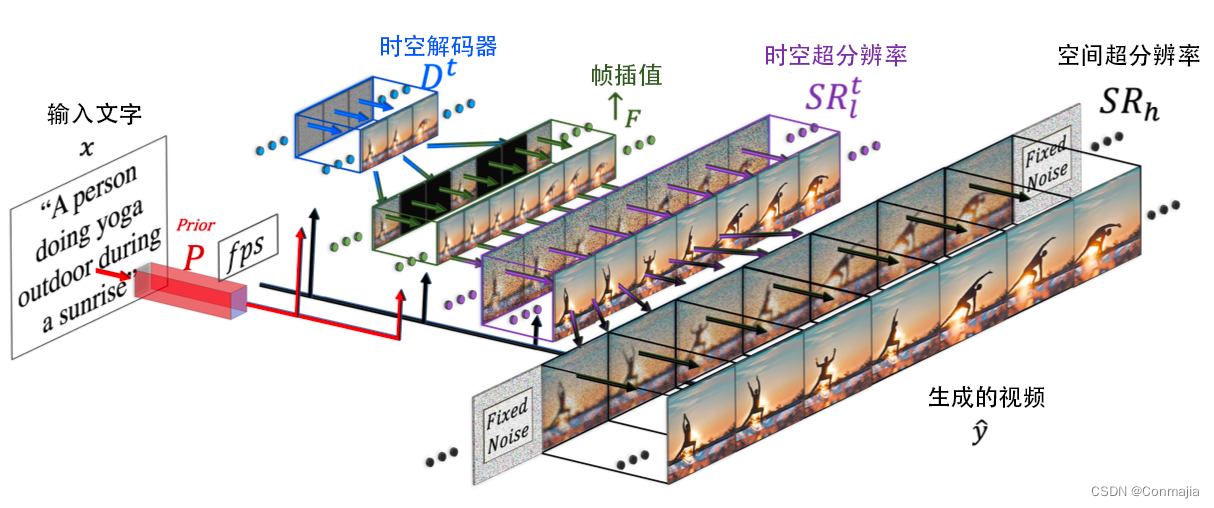
图 2. Make-A-Video 高层次架构。给定输入文字 x,由先验 P 翻译成图片嵌入,并指定所需的帧速率,解码器 Dt 生成 16 个 64 × 64 帧,通过 ↑F 插值成高帧率,通过 SR 将分辨率提高到 256 × 256,通过 SRh 将分辨率提高到 768 × 768,从而生成高时空分辨率的视频 y
Make-A-Video 的最终 T2V 推断方案(如图 2 所示)可以表述为:
y
t
^
=
S
R
h
∘
S
R
l
t
↑
F
∘
D
t
∘
P
∘
(
x
^
,
C
x
(
x
)
)
,
(1)
\hat{y_t}=\mathrm{SR}_h\circ\mathrm{SR}_l^t\uparrow_F\circ\mathrm{D}^t\circ\mathrm{P}\circ\left(\hat{x},\mathrm{C}_x\left(x\right)\right),\tag{1}
yt^=SRh∘SRlt↑F∘Dt∘P∘(x^,Cx(x)),(1)
其中
y
t
^
\hat{y_t}
yt^ 是生成的视频,
S
R
h
\mathrm{SR}_h
SRh、
S
R
l
\mathrm{SR}_l
SRl 分别是空间、时空超分辨率网络(见 3.2 节),
↑
F
\uparrow_F
↑F 是帧插值网络(见 3.3 节),
D
t
\mathrm{D}^t
Dt 是时空解码器(见 3.2 节),
P
\mathrm{P}
P 是先验值(见 3.1 节),
x
^
\hat{x}
x^ 是经 BPE 编码的文字,
C
x
\mathrm{C}_x
Cx 是 CLIP 文字编码器,
x
x
x 是输入文字。三大主要组件将在后续小节中详细阐述。
3.1 文字转图片模型
在添加时间组件之前,我们训练了此方法的主要部分:在文本图片对上训练的 T2I 模型,这个模型核心组件跟 Ramesh 的研究里用到的核心组件一致。
我们使用以下网络从文本生成高分辨率图片:(i) 一个先验网络
P
\mathrm{P}
P,给定文本嵌入
x
e
x_e
xe 和 BPE 编码的文本令牌
x
^
\hat{x}
x^ 时,在推理过程中生成图片嵌入
y
e
y_e
ye;(ii) 一个解码器网络
D
\mathrm{D}
D,以图片嵌入
y
e
y_e
ye 为条件生成低分辨率
64
×
64
64\times 64
64×64 RGB 图片
y
l
^
\hat{y_l}
yl^;(iii) **两个超分辨率网络
S
R
l
\mathrm{SR}_l
SRl、
S
R
h
\mathrm{SR}_h
SRh**,分别将生成的图片
y
l
^
\hat{y_l}
yl^ 的分辨率提高到
256
×
256
256\times 256
256×256 和
768
×
768
768\times768
768×768 像素,从而生成最终的图片
y
^
\hat{y}
y^。
3.2 时空层
为了将二维 (2D) 条件网络扩展到时间维度,我们修改了两个关键的砌块。为了便于生成视频,现在不仅需要空间维度,还需要时间维度:(i) 卷积层(见 3.2.1 节)和 (ii) 注意力层(见 3.2.2 节)。其他层(如全连接层)在添加额外维度时不需要作特别处理,因为它们与结构化的空间和时间信息无关。大多数基于 U-Net 的扩散网络都进行了时间修改——时空解码器
D
t
\mathrm{D}_t
Dt 现在生成 16 个 RGB 帧,每个大小为
64
×
64
64\times 64
64×64,新增的帧插值网络
↑
F
\uparrow_F
↑F,通过在 16 个生成的帧之间进行插值来提高有效帧速率(如图 2 所示),以及超分辨率网络
S
R
l
t
\mathrm{SR}_l^t
SRlt。
注意,超分辨率涉及到幻觉信息。为了实现无闪烁作品,帧与帧之间的幻觉必须是一致的。因此,我们的
S
R
l
t
\mathrm{SR}^t_l
SRlt 模块在操作时以跨空间和时间维度的方式进行。在定性检查中,我们发现这大大胜过执行逐帧超分辨率处理。由于内存和计算的限制,以及高分辨率视频数据的稀缺,将
S
R
h
\mathrm{SR}_h
SRh 扩展到时间维度颇具挑战性。所以
S
R
h
\mathrm{SR}_h
SRh 只在空间维度上起作用。但是为了鼓励在帧与帧之间产生一致的细节幻觉,我们使用相同的噪声去初始化每一帧。
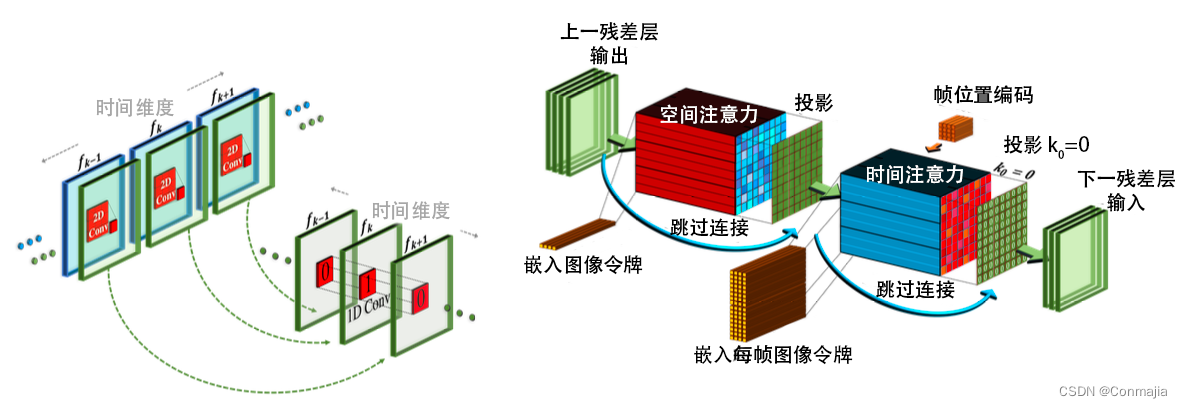
图 3. 伪 3D 卷积层和关注层的架构和初始化方案,使预先训练的文字到图片模型无缝过渡到时间维度。(左) 每个空间 2D 卷积层后面跟着一个时间 1D 卷积层。时间转换层用恒等函数初始化。(右) 通过将时间投影初始化为零,在空间注意力层之后应用时间注意力层,得到时间注意力块的恒等函数。
3.2.1 伪三维卷积层
在可分离卷积的激励下,我们在每个二维(2D)卷积层之后叠加了一个一维(1D)卷积,如图 3 所示。这促进了空间轴和时间轴之间的信息共享,而不会受制于三维(3D)卷积层过重的计算负荷。此外,它在预训练的 2D 卷积层和新初始化的 1D 卷积层之间创建了一个具体的分区,允许我们从头开始训练时间卷积,并与此同时在空间卷积的权重中保留先前学习的空间知识。
给定输入张量
h
∈
R
B
×
C
×
F
×
H
×
W
h\in\mathbb{R}^{B\times C\times F\times H\times W}
h∈RB×C×F×H×W,其中
B
B
B、
C
C
C、
F
F
F、
H
H
H、
W
W
W 分别为批次维、通道维、帧维、高度维、宽度维,我们的伪三维卷积层定义为:
Conv
P3D
(
h
)
≔
Conv
1D
(
Conv
2D
(
h
)
∘
T
)
∘
T
,
(2)
\text{Conv}_{\text{P3D}}\left(h\right)\coloneqq\text{Conv}_{\text{1D}}\left(\text{Conv}_{\text{2D}}\left(h\right)\circ T\right)\circ T,\tag{2}
ConvP3D(h):=Conv1D(Conv2D(h)∘T)∘T,(2)
其中转置算子
∘
T
\circ T
∘T 用于交换空间和时间维度。为了让初始化过程更加平滑,当
Conv
2D
\text{Conv}_{\text{2D}}
Conv2D 层从预训练的 T2I 模型初始化时,
Conv
1D
\text{Conv}_{\text{1D}}
Conv1D 层初始化为恒等函数,从而实现从训练的纯空间层到时空层的无缝过渡。注意,在初始化时,由于使用了随机噪声,网络将生成
K
K
K 个不同的图片,每张图片都符合输入文本,但是缺乏时间一致性。
3.2.2 伪三维注意力层
T2I 网络的一个关键组成部分是注意力层。除了自我关注提取的特征外,文字信息被注入到几个网络层次结构中,以及其他相关信息,例如扩散时间步骤。虽然使用 3D 卷积层的计算量很大,但从内存消耗的角度来看,将时间维度添加到注意力层是完全不可行的。受 VDM 工作的启发,我们将维度分解策略扩展到注意层。在每个(预训练的)空间注意力层之后,我们叠加一个时间注意力层,它与卷积层一样,近似于一个完整的时空注意力层。具体来说,给定一个输入张量
h
h
h,我们将
flatten
\text{flatten}
flatten(扁平化)定义为一个矩阵算子,它将空间维度压平为
h
′
∈
R
B
×
C
×
F
×
H
×
W
h'\in\mathbb{R}^{B\times C\times F\times H\times W}
h′∈RB×C×F×H×W。
Unflatten
\text{Unflatten}
Unflatten(反扁平化)定义为逆矩阵算子。因此,伪三维注意层被定义为:
ATTN
P3D
(
h
)
=
unflatten
(
ATTN
1D
(
ATTN
2D
(
flatten
(
h
)
)
∘
T
)
∘
T
)
.
(3)
\text{ATTN}_{\text{P3D}}\left(h\right)=\text{unflatten}\left(\text{ATTN}_{\text{1D}}\left(\text{ATTN}_{\text{2D}}\left(\text{flatten}\left(h\right)\right)\circ T\right)\circ T\right).\tag{3}
ATTNP3D(h)=unflatten(ATTN1D(ATTN2D(flatten(h))∘T)∘T).(3)
与
Conv
P3D
\text{Conv}_\text{P3D}
ConvP3D 类似,为了允许平滑的时空初始化,
ATTN
2D
\text{ATTN}_\text{2D}
ATTN2D 层从预训练的 T2I 模型初始化,
ATTN
1D
\text{ATTN}_\text{1D}
ATTN1D 层则初始化为恒等函数。
因子化时空注意力层也被用于 VDM 和 CogVideo 中。CogVideo 为每个(冻结的)空间层添加了时间层,而我们联合训练它们。为使其网络能够交替训练图片和视频,VDM 通过反扁平化的
1
×
3
×
3
1\times 3\times3
1×3×3 卷积滤波器将 2D U-Net 扩展到 3D,这样后续的空间注意力仍然是 2D 的,并可通过相对位置嵌入 1D 时间注意力。相比之下,我们应用了额外的
3
×
1
×
1
3\times1\times1
3×1×1 卷积投影(在每个
1
×
3
×
3
1\times3\times3
1×3×3 之后),这样时间信息也将通过各卷积层传递。
帧速率调节。除了 T2I 条件,类似于 CogVideo,我们添加了一个额外的条件参数
fps
\text{fps}
fps,表示生成视频中的每秒帧数。通过调节不同的帧数每秒,使一个额外的增强方法,以解决有限的可用视频在训练时,并提供了额外的控制在推理时所生成的视频。
3.3 帧插值网络
除了第 3.2 节中讨论的时空修改之外,我们还训练了一个新的掩蔽帧插值和外推网络
↑
F
\uparrow_F
↑F。它能够通过帧插值来增加生成的视频的帧数,从而生成更平滑的视频,或者通过前后帧外推来延长视频长度。为了在内存和计算约束下提高帧率,我们在掩蔽帧插值任务上对时空解码器
D
t
\text{D}^t
Dt 进行微调,通过对掩蔽输入帧进行零填充,实现视频的上采样。当对掩蔽帧插值进行微调时,我们在 U-Net 的输入中添加了额外的 4 个通道:3 个用于 RGB 掩蔽视频输入,另外一个二进制通道表示哪些帧被掩蔽。我们对可变帧跳跃和
fps
\text{fps}
fps 调节进行了微调,以实现多个时间上采样。我们将
↑
F
\uparrow_F
↑F 表示为通过掩蔽帧插值扩展给定视频张量的运算符。对于我们所有的实验,我们应用了
↑
F
\uparrow_F
↑F 和跳帧值 5,将 16 帧视频上采样到 76 帧(
(
16
−
1
)
×
5
+
1
(16-1)\times 5+1
(16−1)×5+1)。注意,我们可以通过在视频的开头或结尾掩蔽帧来将相同的架构用于视频外推或图片动画。
3.4 训练
上面描述的 Make-A-Video 各组件是独立训练的。唯一接收文字作为输入的组件是先验
P
\text{P}
P。我们在配对的文字图片数据上训练它,而不是在视频上对它进行微调。解码器、先验和两个超分辨率组件首先单独对图片(没有对齐的文本)进行训练。回想一下,解码器接收 CLIP 图片嵌入作为输入,超分辨率组件在训练期间接收下采样图片作为输入。在对图片进行训练后,我们添加和初始化新的时间层,并在未标记的视频数据上对其进行微调。从原始视频中随机抽取 16 帧,帧数从 1 到 30 不等。我们使用 beta 函数进行采样,在训练解码器时,从更高的 FPS 范围(较少的运动)开始,然后过渡到更低的 FPS 范围(更多的运动)。遮蔽帧插值组件由时序解码器进行微调。
4 试验
4.1 数据集与设置
数据集。为了训练图片模型,我们使用来自 Laion-5b 数据集的 2.3B 子集,其文字语言为英语。我们过滤出含有 NSFW 图片、垃圾话、或是水印概率大于 0.5 的样本对。我们使用 WebVid-10M 和 HD-VILA-100M 的 10M 子集来训练我们的视频生成模型。注意,我们只使用了视频(而非相应的文字)。解码器
D
t
D^t
Dt 和插值模型在 WebVid-10M 上训练。
SR
l
t
\text{SR}^t_l
SRlt 在 WebVid-10M 和 HD-VILA-10M 上进行训练。对比之前 Hong、Ho 等人的工作收集了用于 T2V 生成的私有文本视频对,我们只使用了公共数据集(并且不使用视频的配对文本)。我们还尝试在零学习设置下对 UCF-101 和 MSR-VTT 进行了自动评估。
自动的度量标准。对于UCF-101,我们为每个类编写了一条模板句子(不生成任何视频),并将其固定以供评估。我们报告了以下 10K 样本上的弗雷歇视频距离(FVD)和初始分数(IS)。我们生成的样本遵循与训练集相同的类分布。对于 MSR-VTT,我们报告了弗雷歇初始距离(FID)和 CLIPSIM(视频帧和文字之间的平均 CLIP 相似度),并遵循 Wu Chengfei 等人的工作,使用了测试集中的所有 59794 个字幕。
真人评估集和度量。我们通过 Amazon Mechanical Turk(AMT)收集了一个由 300 个提示词(prompt)组成的评估集。我们还询问了标注这些提示词的网友“如果有 T2V 系统,他们会对生成什么感兴趣”这种问题。我们滤掉了不完整(例如,“跳进水里”)、太抽象(例如,“气候变化”)或冒犯性的提示词。然后我们确定了 5 个类别(动物、幻想、人物、自然和场景、食物和饮料),并为这些类别选择了提示词。这些提示词是在没有为他们生成任何视频的情况下选择的,并保持固定。此外,我们还使用 Imagen 的 DrawBench 提示词进行人工评估。我们主要评估视频质量和文本视频的符合度。对于视频质量,我们以随机顺序显示两个视频,并询问提示词的标注者哪个视频的质量更高。为了评估符合度,我们还会显示文本,并询问标注者哪个视频与文本有更好的对应关系(为避免干扰,我们建议他们忽略质量问题)。此外,我们还进行了人工评估,以比较我们的插值模型和 Reda 等人研究的 FILM 视频运动真实感。对于每次比较,我们以 5 个不同标注者的投票结果占多数者作为最终结果。
4.2 定量结果
MSR-VTT 的自动评估。除了 GODIVA 和 NÜWA 对 MSRVTT 的报告外,我们还对官方发布的 CogVideo 模型进行了推理,进行了中英文输入的比较。对于 CogVideo 和 Make-A-Video,在零学习设置下,我们只为每个提示生成一个示例。鉴于评估模型没必要采用更高的分辨率和帧率,我们只生成了
16
×
256
×
256
16\times 256 \times 256
16×256×256 的视频。结果如表 1 所示,Make-A-Video 的零学习性能明显优于用 MSR-VTT 训练的 GODIVA 和 NÜWA。我们在中文和英文设置上的表现也优于 CogVideo。因此,Make-A-Video 比以前的工作具有更好的生成能力。
表 1. MSR-VTT 上的 T2V 生成评估。零学习意味着未在 MSR-VTT 上进行过训练。样本/输入表示对于某一输入而生成并打分的样本数。方法零学习样本/输入FID(
↓
\downarrow
↓)CLIPSIM(
↑
\uparrow
↑)GODIVA否30–0.2402NÜWA否–47.680.2439CogVideo(中文)是124.780.2614CogVideo(英文)是123.590.2631Make-A-Video (我们的)是1**13.17****0.3049**
UCF-101 自动评估。UCF-101 是比较流行的用于评估视频生成的跑分工具,最近已经可以用于 T2V 模型。CogVideo 对预先训练的模型进行了微调,以生成基于分类条件的视频。VDM 执行无条件视频生成,并在 UCF-101 上从头开始训练。我们认为,这两种设置都不够理想,也不能作为对 T2V 生成能力的直接评估。此外,FVD 评估模型期望视频为 0.5 秒(16 帧),这太短了,无法用于实际的视频生成。尽管如此,为了与之前的工作进行比较,我们还是在零镜头和微调设置下对 UCF-101 进行了评估。结果如表 2 所示,Make-A-Video 的零镜头性能已经能与 UCF-101 训练的其他方法有一拼,而且比 CogVideo 好得多。这表明 Make-A-Video 甚至可以更好地生成特定内容。我们的微调设置实现了最先进的结果,显著降低了 FVD,这表明 Make-A-Video 可以生成比以前的工作更连贯的视频。
表 2. UCF-101 上对零学习和微调两种设置的视频生成评估。方法预训练分类分辨率IS(
↑
\uparrow
↑)FVD(
↓
\downarrow
↓)零学习设置CogVideo(中文)否是480×48023.55751.34CogVideo(英文)否是480×48025.27701.59Make-A-Video (我们的)否是256×256**33.00****367.23**微调设置TGANv2否否128×12826.60±0.47–DIGAN否否32.70±0.35577±22MoCoGAN-HD否否256×25633.95±0.25700±24CogVideo是是160×16050.46626VDM否否64×6457.80±1.3–TATS-base否是128×12879.28±0.38278±11Make-A-Video (我们的)是是256×256**82.55****81.25**
真人评估。我们将在 DrawBench 和我们的测试集上与 CogVideo(这是唯一公开的零学习 T2V 生成模型)进行比较。我们还评估了 VDM 网页上显示的 28 个视频(这可能偏向于展示模型的优势)。由于这是一个非常小的测试集,我们对每个输入随机生成 8 个视频,进行 8 次评估并报告平均结果。我们生成了
76
×
256
×
256
76\times 256 \times 256
76×256×256 分辨率的视频供真人评估。结果如表 3 所示。在所有基准测试和比较中,Make-A-Video 在视频质量和文本视频符合度方面都取得了更好的表现。相比于 CogVideo,在 DrawBench 和我们的评估集上的结果是相似的。对于 VDM,值得注意的是,在没有任何挑选的情况下,我们已经取得了明显更好的结果。我们还将我们的帧插值网络与 FILM 进行了比较。我们首先从 DrawBench 和我们的评估集中的文字提示词生成低帧率的视频(1 FPS),然后使用每种方法将样本提高到 4 FPS。在我们的评估集上,打分者觉得我们的方法更真实的运动的概率为 62%,在 DrawBench 上这一概率为 54%。我们观察到,我们的方法在帧之间存在较大差异时表现出色,而在这种情况下,拥有物体如何移动的真实知识至关重要。
表 3. DrawBench 对比 CogVideo 和以 VDM 官网 28 支视频样本产生的测试集的真人评估结果。表中数字显示打分者更喜欢我们 Make-A-Video 模型的输出结果。比较跑分质量符合度Make-A-Video (我们的) vs. VDMVDM 提示词 (28)84.3878.13Make-A-Video (我们的) vs. CogVideo (中文)DrawBench (200)76.8873.37Make-A-Video (我们的) vs. CogVideo (英文)DrawBench (200)74.4868.75Make-A-Video (我们的) vs. CogVideo (中文)自有评估集 (300)73.4475.74Make-A-Video (我们的) vs. CogVideo (英文)自有评估集 (300)77.1571.19
4.3 定性结果
Make-A-Video 的生成样张如图 1 所示。在本节中,我们将展示 T2V 生成与 CogVideo 和 VDM 的比较,以及视频插值与 FILM 的比较。此外,我们的模型可以用于各种其他任务,如图片动画、视频变化等。由于篇幅限制,我们每种只展示一个例子。图 4.a 展示了 Make-A-Video 与 CogVideo、VDM 的比较。Make-A-Video 可以通过动作一致性和文字对应生成更丰富的内容。图 4.b 展示了一个图像动画的例子,其中我们在图片和图片段嵌入上调整了遮蔽帧插值和外推网络
↑
F
\uparrow_F
↑F 来推断视频的其余部分。这允许用户使用自己的图片生成视频——让他们有机会个性化和直接控制生成的视频。图 4.c 显示了我们的方法和 FILM 在两幅图像之间插值任务上的比较。我们通过使用插值模型来实现这一点,该模型将两张图像作为开始和结束帧,并在生成时遮蔽 14 帧。我们的模型生成了更多语义上有意义的插值,而 FILM 似乎主要是在帧之间平滑过渡,而没有对移动的内容的语义现实理解。图4.d 显示了视频变化的示例。我们将视频中所有帧的平均 CLIP 嵌入作为生成语义相似视频的条件。更多视频生成示例和应用程序可以参考这个网站:make-a-video.github.io。
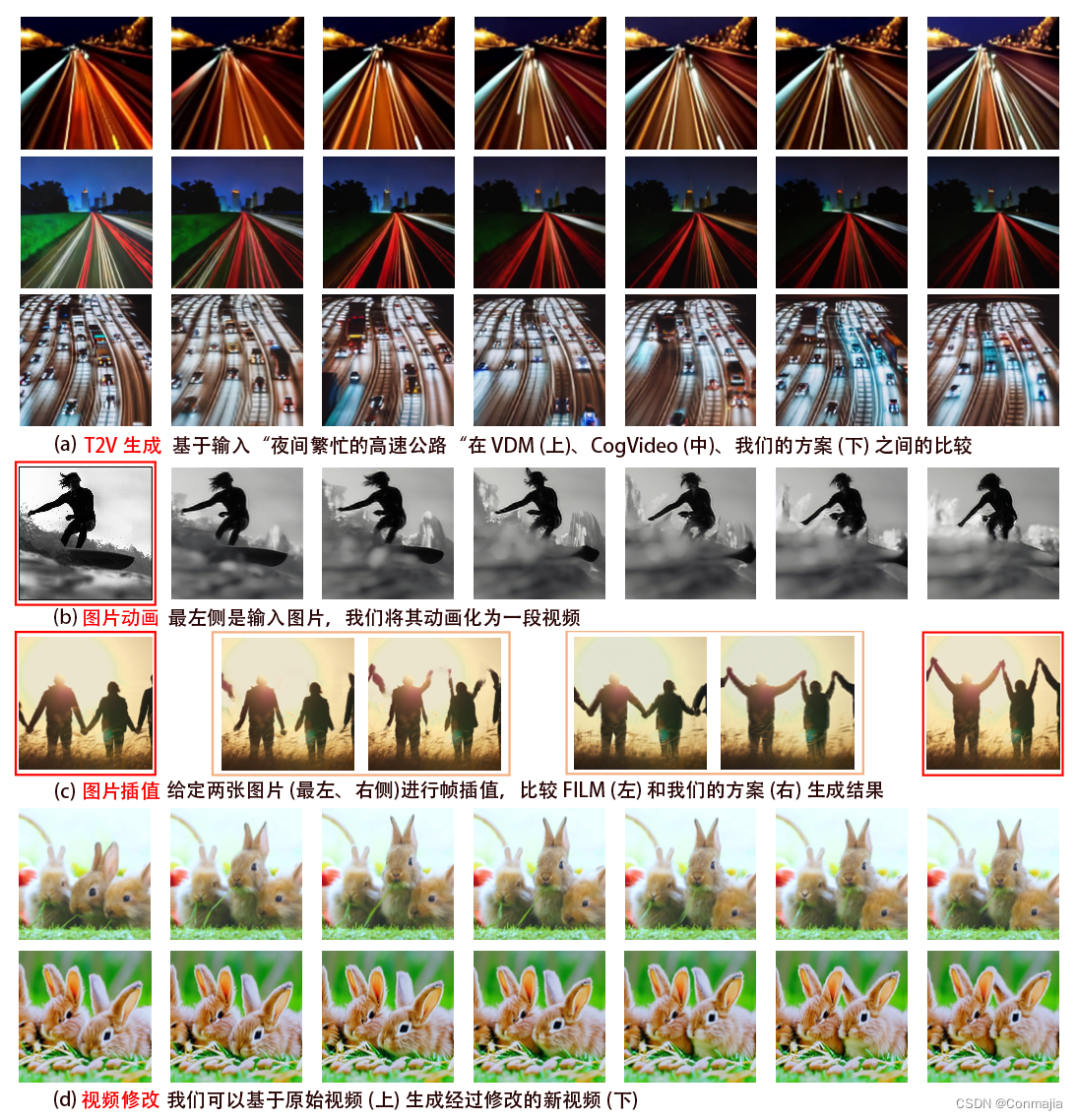
图 4. 各种应用的定性比较结果。
讨论
人类智力的最大优势之一是能够向我们周围的世界学习。如果一个生成系统能模仿人类的学习方式,就像我们通过观察能很快学会识别人、地点、事物和动作一样,将更有创造性、更有用。使用无监督学习从更高数量级的视频中学习世界的动态,有助于研究人员摆脱对标记数据的依赖。目前的工作已经展示了如何有效地结合标签图像与未标签的视频片段来实现这一点。
下一步,我们计划解决几个技术限制。如前所述,我们的方法不能学习文字及只能在视频中推断的现象之间的关联。如何结合这些(例如,生成一个人从左到右或从右到左挥手的视频),来生成更长的、包含多个场景和事件的视频,描绘更详细的故事,是留给未来的工作。
与所有使用网络数据训练的大规模模型一样,我们的模型可能会从中学到并且夸大一些带有社会偏见的有害内容。我们的 T2I 生成模型是在去除 NSFW 内容和有害词汇的数据上进行训练的。我们所有的数据(图像和视频)都是公开的,这为我们的模型增加了一层透明度,并使该领域工作者能够再现我们的工作。
致谢
Mustafa Said Mehmetoglu, Jacob Xu, Katayoun Zand, Jia-Bin-Huang, Jiebo Luo, Shelly Sheynin, Angela Fan, Kelly Freed。感谢您的贡献!
参考文献
- Max Bain, Arsha Nagrani, Gu ̈l Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, pp. 1728–1738, 2021.
- Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. CoRR, abs/2005.14165, 2020. URL https://arxiv.org/abs/2005.14165.
- Franc ̧ois Chollet. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1251–1258, 2017.
- Ming Ding, Wendi Zheng, Wenyi Hong, and Jie Tang. Cogview2: Faster and better text-to-image generation via hierarchical transformers. arXiv preprint arXiv:2204.14217, 2022.
- Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman. Make-a- scene: Scene-based text-to-image generation with human priors, 2022. URL https://arxiv. org/abs/2203.13131.
- Songwei Ge, Thomas Hayes, Harry Yang, Xi Yin, Guan Pang, David Jacobs, Jia-Bin Huang, and Devi Parikh. Long video generation with time-agnostic vqgan and time-sensitive transformer. ECCV, 2022.
- Deeptha Girish, Vineeta Singh, and Anca Ralescu. Understanding action recognition in still images. pp. 1523–1529, 06 2020. doi: 10.1109/CVPRW50498.2020.00193.
- Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. NIPS, 2014.
- Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In CVPR, pp. 10696– 10706, 2022.
- Tanmay Gupta, Dustin Schwenk, Ali Farhadi, Derek Hoiem, and Aniruddha Kembhavi. Imagine this! scripts to compositions to videos. In ECCV, pp. 598–613, 2018.
- Thomas Hayes, Songyang Zhang, Xi Yin, Guan Pang, Sasha Sheng, Harry Yang, Songwei Ge, Is- abelle Hu, and Devi Parikh. Mugen: A playground for video-audio-text multimodal understanding and generation. ECCV, 2022.
- Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020. URL https://arxiv.org/abs/2006.11239.
- Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models, 2022. URL https://arxiv.org/abs/2204.03458.
- Seunghoon Hong, Dingdong Yang, Jongwook Choi, and Honglak Lee. Inferring semantic layout for hierarchical text-to-image synthesis. In CVPR, pp. 7986–7994, 2018.
- Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pre- training for text-to-video generation via transformers, 2022. URL https://arxiv.org/ abs/2205.15868.
- Yitong Li, Martin Min, Dinghan Shen, David Carlson, and Lawrence Carin. Video generation from text. In AAAI, volume 32, 2018.
- Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019a. URL http://arxiv.org/abs/1907.11692.
- Yue Liu, Xin Wang, Yitian Yuan, and Wenwu Zhu. Cross-modal dual learning for sentence-to- video generation. In Proceedings of the 27th ACM International Conference on Multimedia, pp. 1239–1247, 2019b.
- Tanya Marwah, Gaurav Mittal, and Vineeth N Balasubramanian. Attentive semantic video genera- tion using captions. In ICCV, pp. 1426–1434, 2017.
- Gaurav Mittal, Tanya Marwah, and Vineeth N Balasubramanian. Sync-draw: Automatic video gen- eration using deep recurrent attentive architectures. In Proceedings of the 25th ACM international conference on Multimedia, pp. 1096–1104, 2017.
- Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Yingwei Pan, Zhaofan Qiu, Ting Yao, Houqiang Li, and Tao Mei. To create what you tell: Generat- ing videos from captions. In Proceedings of the 25th ACM international conference on Multime- dia, pp. 1789–1798, 2017.
- Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. In CVPR, 2022.
- Zhaofan Qiu, Ting Yao, and Tao Mei. Learning spatio-temporal representation with pseudo-3d residual networks. In ICCV, pp. 5533–5541, 2017.
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pp. 8748–8763. PMLR, 2021.
- Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In ICML, pp. 8821–8831. PMLR, 2021.
- Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with clip latents, 2022. URL https://arxiv.org/abs/ 2204.06125.
- Fitsum Reda, Janne Kontkanen, Eric Tabellion, Deqing Sun, Caroline Pantofaru, and Brian Curless. Film: Frame interpolation for large motion. arXiv preprint arXiv:2202.04901, 2022.
- Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. Generative adversarial text to image synthesis. In ICML, pp. 1060–1069. PMLR, 2016.
- Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjo ̈rn Ommer. High- resolution image synthesis with latent diffusion models. In CVPR, pp. 10684–10695, 2022.
- Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kam- yar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Sal- imans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image dif- fusion models with deep language understanding, 2022. URL https://arxiv.org/abs/ 2205.11487.
- Masaki Saito, Shunta Saito, Masanori Koyama, and Sosuke Kobayashi. Train sparsely, generate densely: Memory-efficient unsupervised training of high-resolution temporal gan. International Journal of Computer Vision, 128(10):2586–2606, 2020.
- Christoph Schuhmann, Romain Beaumont, Cade W Gordon, Ross Wightman, Theo Coombes, Aarush Katta, Clayton Mullis, Patrick Schramowski, Srivatsa R Kundurthy, Katherine Crowson, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.
- Christoph Schuhmann, Richard Vencu, Romain Beaumont, Theo Coombes, Cade Gor- don, Aarush Katta, Robert Kaczmarczyk, and Jenia Jitsev. LAION-5B: laion- 5b: A new era of open large-scale multi-modal datasets. https://laion.ai/ laion-5b-a-new-era-of-open-large-scale-multi-modal-datasets/, 2022.
- Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012.
- Yu Tian, Jian Ren, Menglei Chai, Kyle Olszewski, Xi Peng, Dimitris N Metaxas, and Sergey Tulyakov. A good image generator is what you need for high-resolution video synthesis. ICLR, 2021.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2017. URL https://arxiv. org/abs/1706.03762.
- Chenfei Wu, Lun Huang, Qianxi Zhang, Binyang Li, Lei Ji, Fan Yang, Guillermo Sapiro, and Nan Duan. Godiva: Generating open-domain videos from natural descriptions. arXiv preprint arXiv:2104.14806, 2021a.
- ChenfeiWu,JianLiang,LeiJi,FanYang,YuejianFang,DaxinJiang,andNanDuan.NU ̈wa:Visual synthesis pre-training for neural visual world creation, 2021b. URL https://arxiv.org/ abs/2111.12417.
- Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotem- poral feature learning: Speed-accuracy trade-offs in video classification. In ECCV, pp. 305–321, 2018.
- Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In CVPR, pp. 5288–5296, 2016.
- Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. Attngan: Fine-grained text to image generation with attentional generative adversarial net- works. In CVPR, pp. 1316–1324, 2018.
- Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, and Baining Guo. Advancing high-resolution video-language representation with large-scale video transcriptions. In CVPR, pp. 5036–5045, 2022.
- Rongtian Ye, Fangyu Liu, and Liqiang Zhang. 3d depthwise convolution: Reducing model parame- ters in 3d vision tasks. In Canadian Conference on Artificial Intelligence, pp. 186–199. Springer, 2019.
- Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved vqgan. arXiv preprint arXiv:2110.04627, 2021.
- Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation, 2022a. URL https://arxiv.org/abs/2206.10789.
- Sihyun Yu, Jihoon Tack, Sangwoo Mo, Hyunsu Kim, Junho Kim, Jung-Woo Ha, and Jinwoo Shin. Generating videos with dynamics-aware implicit generative adversarial networks. ICLR, 2022b.
- Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dim- itris N Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adver- sarial networks. In ICCV, pp. 5907–5915, 2017.
- Han Zhang, Jing Yu Koh, Jason Baldridge, Honglak Lee, and Yinfei Yang. Cross-modal contrastive learning for text-to-image generation. In CVPR, pp. 833–842, 2021.
论文作者名单
Uriel Singer+, Adam Polyak+, Thomas Hayes+, Xi Yin+, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh+, Sonal Gupta+, Yaniv Taigman+
Meta AI
注 + 者为论文主要贡献者。通信作者:Uriel Singer urielsinger@meta.com
版权归原作者 Conmajia 所有, 如有侵权,请联系我们删除。