

- Title:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- Paper:https://arxiv.org/abs/2102.03334
- Github:https://github.com/dandelin/vilt
摘要
**视觉和语言预训练 (VLP) **在提高了各种联合视觉和语言下游任务上的性能。目前的 VLP 方法 **严重依赖于图像特征提取过程**,其中大部分涉及 **区域监督** (如目标检测) 和 **卷积架构** (如 ResNet)。虽然在文献中被忽略了,但我们发现在以下方面 **存在问题**:(1) **效率/速度**,简单地提取输入特征比多模态交互步骤需要更多的运算;(2) **表达能力 (express power)**,因为它是视觉嵌入器 (embedder) 及其预定义视觉词汇的表达能力的上限。在本文中,我们提出了一个最小的 VLP 模型,**视觉和语言 Transformer (ViLT)**,在此意义上,**视觉输入的处理 **被大大简化为与我们处理文本输入相同的 **无卷积 (convolution-free) 方式**。我们证明了 ViLT 比以前的 VLP 模型快几十倍,但仍具有竞争力或更好的下游任务性能。我们的代码和预训练权重可在 Github 上找到。
一、引言
预训练和微调方案已经扩展到视觉和语言的联合领域,从而产生了视觉和语言预训练 (VLP) 模型的类型/范畴 (Lu et al., 2019; Chen et al., 2019; Su et al., 2019; Li et al., 2019; Tan & Bansal, 2019; Li et al., 2020a; Lu et al., 2020; Cho et al., 2020; Qi et al., 2020; Zhou et al., 2020; Huang et al., 2020; Li et al., 2020b; Gan et al., 2020; Yu et al., 2020; Zhang et al., 2021)。这些模型通过图像文本匹配和掩码语言建模目标 (虽然一些工作采用了额外的目标和数据结构,但这两个目标适用于几乎每个 VLP 模型) 进行预训练,并对视觉和语言下游任务进行微调,其中输入涉及两种模态 (modalities)。
** 为输入 VLP 模型,图像像素在初始时 需要同语言标记 (tokens) 一起 以密集的形式嵌入 (embedded in a dense form)**。自 Krizhevesk 等人 (2012) 的开创性工作以来,深度卷积网络一直被认为是这一视觉嵌入步骤的关键。大多数 VLP 模型使用在 Visual Genome 数据集上预训练的对象检测器 (Krishna 等人, 2017),标注了 1600 个对象类别和 400 个属性类别,如 Anderson 等人 (2018)。Pixel-BERT (Huang 等人, 2020)是这一趋势的一个例外,因为它使用了在 ImageNet 预训练分类 (Russakovsky 等人, 2015) 的 ResNet 变体 (He 等人, 2016; Xie 等人, 2017) 的嵌入像素来代替对象检测模块。
到目前为止,大多数 VLP 的研究都集中于通过增加视觉嵌入器的能力 (power) 来提高性能。在学术实验中,具有较重 (heavy) 的视觉嵌入器的缺点往往被忽略,因为区域特征通常在训练时被预先缓存 (cached in advance),以减轻特征提取的负担。然而,这些限制在现实世界的应用程序中仍然很明显,因为在 "野外" (in the wild) 的查询必须经历一个缓慢的提取过程。
为此,我们将注意力转移到 **轻量快速的视觉输入嵌入 **上。最近的工作 (Dosovitskiy 等人, 2020; Touvron 等人, 2020) 证明,**在将像素输入 Transformer 之前 使用图像块 (patch) 的简单线性投影来嵌入像素 足够有效**。尽管 Transformer 是文本的坚实主流 (solid mainstream) (Devlin 等人, 2019),但直到最近 Transformer 才也被用于图像 (Vaswani 等人, 2017)。**我们假设,在 VLP 模型中用于模态交互的 Transformer 模块也可以设法处理视觉特征 来代替卷积视觉嵌入器,就像它处理文本特征一样**。

图 1:可视化比较传统的 VLP 架构和我们提出的 ViLT。
我们已经从 VLP 管道中完全删除了 CNN,而不会影响下游任务的性能。
ViLT 是第一个 模态特定的组件 比 用于多模态交互的 Transformer 组件 计算量更少的 VLP 模型。
本文提出了一种 **视觉和语言 Transformer (ViLT)**,它以一种统一的方式处理两种模态。其中,主要有别于以前的 VLP 模型的部分为 **浅层中无卷积嵌入的像素级输入**。删除仅用于视觉输入的深度嵌入器,可以显著减少模型的大小和运行时间。图 1 显示,我们的参数高效模型比具有区域特征的 VLP 模型快几十倍,至少比具有网格 (grid) 特征的 VLP 模型快四倍,同时在视觉和语言下游任务上表现出相似甚至更好的性能。
我们的主要贡献可以总结如下:
- ViLT 是视觉和语言模型中最简单的架构,因为它使用 Transformer 模块 代替单独的深度视觉嵌入器 来提取和处理视觉特征。这种设计本质上显著改善了运行时间和参数效率。
- 这是我们首次在不使用区域特征或深度卷积视觉嵌入器的情况下,在视觉和语言任务上取得了胜任的性能。
- 此外,我们首次通过经验表明,在 VLP 训练方案中 前所未有的整个单词掩码和图像增强进一步推动了下游性能。
二、背景
2.1 视觉和语言模型的分类法
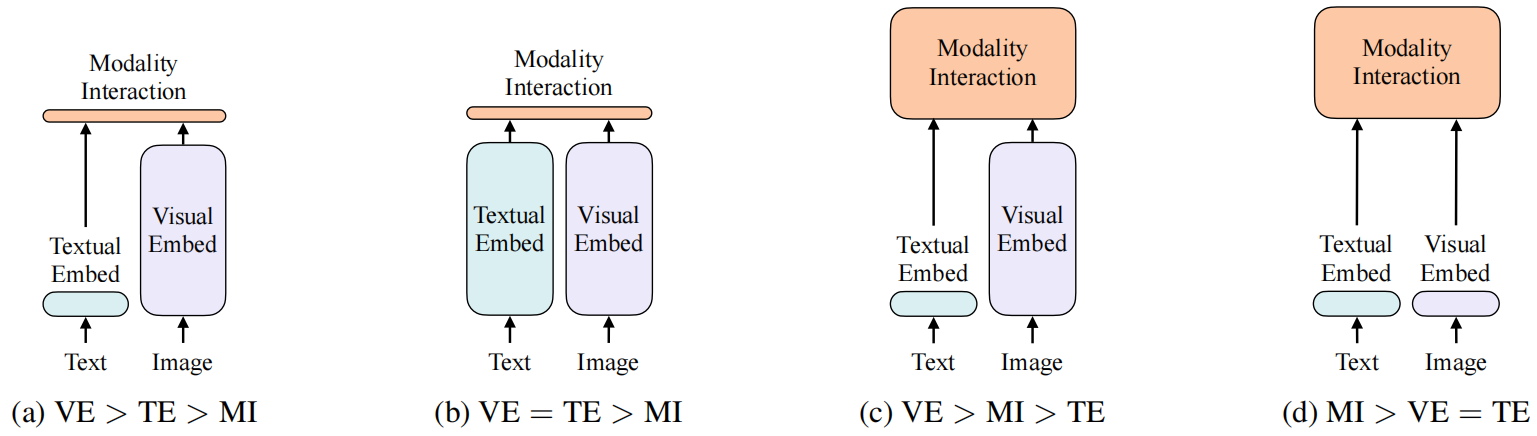
图 2:四类视觉和语言模型。
每个矩形的高度表示其相对计算量大小。
VE、TE 和 MI 分别是视觉嵌入器、文本嵌入器和模态交互的缩写。
我们提出了一种基于两点的视觉和语言模型的分类 (准则):
两种模态在投入的参数和/或计算方面是否具有相同的表达水平 (even level of expressiveness);
两种模态是否在深度网络中交互。
这些要点的组合将得到图 2 中的四种原型。 ** 视觉语义嵌入 (Visual Semantic Embedding,* *VSE) 模型**,如 **VSE++** (Faghri 等人, 2017) 和 **SCAN** (Lee 等人, 2018),属于 **图 2a**。他们使用单独的嵌入器来处理图像和文本,而前者要重量级得多。然后,它们用 **简单的点积 **或 **浅注意力层 **表示两种模态的嵌入特征的相似度。 **CLIP** (Radford et al., 2021) 属于 **图 2b**,因为它对每个模态分别使用独立但同样昂贵的 Transformer 嵌入器。图像向量和文本向量之间的交互仍然很浅 (点积)。**尽管 CLIP 在图像到文本的检索上的零次性能出色,但我们无法在其他视觉和语言下游任务上观察到同样水平的表现**。例如,微调 NLVR2 的 MLP 头部 (Suhr 等人, 2018),使用来自 CLIP 的混合视觉和文本向量的点积作为多模态表示,开发/验证准确率低至 50.99±0.38 (使用 3 种不同的随机数种子运行);由于偶然水平准确率 (chance level accuracy) 为 0.5,我们得出结论,即该表示无法胜任对这个任务的学习。这也与 Suhr 等人 (2018) 的研究结果相匹配,即 **所有具有简单融合多模态表示的模型都无法学习 NLVR2**。 这一结果支持 (backs up) 了我们的推测 (speculation),即 即使是来自高性能的 联合模态 (unimodal) 嵌入器的简单输出 的融合,也可能不足以学习复杂的视觉和语言任务,从而支持 (bolstering) 对更严格的跨模态交互方案的需求。 与具有 **浅交互 (shallow interaction) **的模型不同,最近属于 **图 2c** 下的 **VLP 模型 **使用 **深度 Transformer **来建模图像和文本特征的交互。然而,除了交互模块外,图像特征的提取和嵌入中仍涉及卷积网络,这占了如图 1 所示的计算量的大部分。**基于调制 (modulation-based) 的视觉和语言模型** (Perez 等人, 2018; Nguyen 等人, 2020) 也属于 **图 2c**,它们的视觉 CNN 主干对应于视觉嵌入器,RNN 产生文本嵌入器的调制参数,调制 CNN 用于模态交互。 我们提出的 **ViLT** 是 **图 2d **类型的第一个模型,其中 **原始像素的嵌入层是浅的,计算上像文本标记 (tokens) 一样轻量**。因此,这种架构 **将大部分的计算集中在模态交互的建模上**。
2.2 模态交互模式
当代 VLP 模型的核心是 Transformer。它们获得视觉和文本嵌入序列作为输入,在整个层中建模模态间以及选择性的模态内交互,然后输出一个上下文化的特征序列。
Bugliarello 等 (2020) 将交互模式分为两类:
单流方法 (single-stream, 如 VisualBERT (Li 等, 2019)、UNITER (Chen 等, 2019) ) ,其中的层共同操作图像和文本输入的拼接;
双流方法 (dual-stream, 如 ViLBERT (Lu 等, 2019) 、LXMERT (Tan & Bansal, 2019) ),其中两种模态未在输入级别上拼接。
我们遵循单流方法用于交互 Transformer 模块,因为 **双流方法引入了额外的参数**。
2.3 视觉嵌入方案
尽管所有的性能型 (performant) VLP 模型都 **共享相同的 文本嵌入器 —— 来自预训练 BERT 的标记器 (tokenizer)、与 BERT 类似的单词和位置嵌入** —— 它们有别于视觉嵌入器。尽管如此,在大多数 (如果不是全部的话) 的情况下,**视觉嵌入是现有 VLP 模型的瓶颈**。我们在这一步走捷径 (cutting corner),即通过引入 **图像块投影 (patch projection)** 取代 使用重量提取模块获取的区域或网格特征。
2.3.1 区域特征
VLP 模型主要利用 **区域特征**,也被称为 **自底向上的 (bottom up) 特征** (Anderson 等人, 2018)。它们是从一个现成的 (off-the-shelf) 物体检测器中获得的,如 Faster R-CNN (Ren et al., 2016)。
**生成区域特征的一般管道 **如下。首先,一个区域提议网络 (RPN) 基于从 CNN 主干中池化的网格特征 提出感兴趣区域 (RoI)。非极大抑制 (NMS) 然后将 RoI 的数量减少到几千个。在被 RoI Align (He et al.,2017) 等操作池化后,RoI 通过 RoI 头部,并成为区域特征。NMS 再次应用于每个类别,最终将特征的数量减少到 100 个以下。
上述过程涉及到几个影响性能和运行时的因素:**主干、NMS 类型、RoI 头部**。以往的工作对控制这些因素比较宽松 (lenient),彼此做出不同的选择,如表 7.2 所示 (Bugliarello 等人 (2020) 表明,受控设置弥补了各种基于区域特征的 VLP 模型的性能差距)。
主干:ResNet-101 (Lu et al., 2019; Tan & Bansal, 2019; Su et al., 2019) 和 ResNext-152 (Li et al., 2019; 2020a; Zhang et al., 2021) 是两个常用的骨干。
NMS:NMS 通常按每个类别的方式 (in a per-class fashion) 完成。具有大量类别时,将 NMS 应用到每个类别将成为主要运行时瓶颈,例如VG 数据集中的 1.6 K (Jiangetal., 2020)。最近引入了经典的类别不可知的 (class-agnostic) NMS 来解决该问题 (Zhang et al., 2021)。
RoI 头部:最初使用 C4 头部 (Andrsonetal 等人, 2018)。FPN-MLP 头部 (Jiang 等人, 2018) 后来被引入。由于头部为每个 RoI 操作,它们造成了大量的运行时负担 (pose a substantial runtime burden)。
** 物体检测器都不管多轻量,都不可能比主干或单层卷积更快**。冻结视觉主干和预先缓存的区域特征 仅在训练时而非推断时有帮助,更别提它还会抑制性能 (not to mention that it could hold performance back)。
2.3.2 网格特征
除了检测器头部外,ResNets 等 CNN 的输出特征网格 (grid) 也可以作为 视觉和语言预训练的视觉特征。直接使用网格特征首先是由 VQA 特定 (VQA-specific) 的模型提出的 (Jiang 等人, 2020; Nguyen 等人, 2020),主要旨在避免使用极其缓慢的区域选择 (region selection) 操作。
X-LXMERT (Cho 等人, 2020) 通过将区域提议 固定为网格,取代 将区域提议网络中的网格 固定为网格,从而重新审视了网格特征。然而,它们的特征缓存排除了对主干的进一步调整 (的可能性)。
Pixel-BERT 是唯一的 VLP 模型,它取代了 具有 ImageNet 分类预训练的 ResNet 变体主干的 VG 预训练物体检测器。与基于区域特征的VLP 模型中的冻结检测器不同,Pixel-BERT 的主干在视觉和语言预训练中进行了调整 (is tuned)。使用 ResNet-50 的 Pixel-BERT 的下游性能低于基于区域特征的 VLP 模型,但它使用重量得多的 ResNeXt-152 则能与其他竞争者相匹敌。
然而,我们声称网格特征并非首选,因为深度 CNN 仍然很昂贵 —— 占了整个计算的很大部分,如图 1 所示。
2.3.3 图像块投影
为最小化开销 (overhead),我们采用了最简单的视觉嵌入方案:操作于图像块上的 **线性投影 (linear projection)**。ViT (Dosovitskiy et al., 2020) 引入了图像块投影嵌入用于图像分类任务。图像块投影极大地简化了达到文本嵌入的级别/水平的视觉嵌入步骤,它还包括简单的投影 (查找/查询 (lookup)) 操作。我们使用一个** 32×32 图像块投影**,它只需要 2.4M 参数。这与复杂的 ResNe(X)t 主干 (R50 的参数为 25M,R101 为 44M,X152 为 60M) 和检测组件形成鲜明对比 (in sharp contrast to)。它的运行时间也可以忽略,如图 1 所示。我们将在第 4.6 节中进行详细的运行时间分析。
三、视觉和语言 Transformer
3.1 模型概述
ViLT 有一个简洁的 (succinct) 架构,作为一个 VLP 模型,具有最小的视觉嵌入管道,并遵循单流方法。
我们偏离了文献 —— 由预训练 ViT 而非 BERT 初始化交互 Transformer 的权重。这种初始化 利用了交互层的能力来处理视觉特征,而缺乏一个单独的深度视觉嵌入器 (我们还实验了由 BERT 权重初始化层,并使用来自 ViT 预训练的图像块投影,但它不起作用)。

ViT 由堆叠的块组成,其中包括一个 MSA 层和一个 MLP 层。ViT 与 BERT 的唯一区别是 LN 位置:**BERT 的 LN 在 MSA 和 MLP 之后 (后归一化)**,**ViT 的 LN 在 MSA 和 MLP 之前 (前归一化)**。
输入文本  通过一个 **词嵌入矩阵**  和一个 **位置嵌入矩阵**  被嵌入为 ,如公式 (1) 所示。
输入图像  被切分为 **图像块并展平为**,其中  是图像块分辨率,且有 。遵循** **  和 **位置嵌入** ,经展平的图像块  被嵌入为 ,如公式 (2) 所示。
将文本嵌入和图像嵌入 与各自对应的 **模态类型嵌入向量**  相加,然后拼接成一个 **组合序列**,如公式 (3) 所示。**经上下文化的 (contextualized) 向量** 通过深度为  的 Transformer 层迭代更新,得到最终的上下文化序列 。 是整个多模态输入的集合表示,是通过在序列  的第一个 index 上应用线性投影  和双曲正切 (hyperbolic tangent) (即 tanh 激活函数) 得到的。
对于所有的实验,我们使用了 ImageNet 预训练的 ViT-B/32 权重,因此得名 ViLT-B/32 (ViT-B/32 用 ImageNet-21K 预训练,在 ImageNet-1K 上微调,用于图像分类。我们期望在更大的数据集 (如 JFT-300M) 上预训练的权重将产生更好的性能)。隐藏层大小  为768,层深度  为12,图像块大小  为 32,MLP 大小为 3072,注意力头数为 12。
3.2 预训练目标
我们用两个常用于训练 VLP 模型的目标 来训练 ViLT:**图像文本匹配 (ITM) **和 **掩码语言建模 (MLM)**。
3.2.1 图像文本匹配
** **随机以 0.5 的概率将 经对齐的 (aligned) 图片 (即与文本对应的图片) 替换成不同的图片。使用一个 **线性 ITM 头部 **将经池化的输出特征 映射成一个 二值类别的 logits (用来判断图像文本是否匹配),并计算 负对数似然 (negative log-likelihood) 损失 作为我们的 ITM 损失。
更多地 (Plus),受 Chen 等人 (2019) 的 **词区域对齐目标 (word region alignment objective) **的启发,我们设计 **词块对齐 (word patch alignment, WPA) **计算  的两个子集 —— 文本子集  和 视觉子集 之间的 **对齐得分**,使用 **非精确的近端点方法用于最优运输** (using the inexact proximal point method for optimal transports (IPOT)) (Xie 等人, 2020)。我们遵循 Chen 等人 (2019) () 设置了 IPOT 的超参数,并将 **近似的 wasserstein 距离 **乘以 0.1 加到 ITM 损失上。
3.2.2 掩码语言建模
MLM 的目标是通过文本的经上下文化的向量  (即抽象了的文本上下文信息) 去预测 masked 的文本 tokens 。遵循 Devlin 等人 (2019) 的启发/探索法,我们以 0.15 的概率随机 mask 掉 tokens 。
我们使用一个两层的 MLP MLM 头部,其输入  且输出与词表对应的 (over vocabulary) logits,就如 BERT 的 MLM 目标。**MLM 损失 **然后被计算为** 用于 masked tokens** 的 **负对数似然 (negative log-likelihood) 损失**。
3.2.3 全词掩码
** 全词掩码 (Whole Word Masking)** 是一种掩码技术,它 mask 了组成整个词的所有连续子词 tokens。当应用于 BERT 和 Chinese BERT 时,它显示出了对下游任务的有效性 (Cui 等人,2019)。
我们假设,为充分利用来自其他模态的信息,全词掩码对 VLP 尤为重要。例如,使用经预训练的 bert-base-uncased 标记器 (tokenizer) 将单词 “长颈鹿” 标记 (tokenized) 成 3 个子词 (wordpiece) tokens [“gi”, “##raf”, “##fe”] 。如果不是所有的 tokens 都被 masked,比如 [“gi”, “[MASK]”, “##fe”],则模型可能仅仅依赖附近的两种语言 tokens [“gi”,“##fe”] 来预测隐藏的 “##raf”,而非使用图像信息。
预训练时,我们用 0.15 的掩码概率 mask 全词/整个单词。我们将在第 4.5 节中讨论其影响。
3.4 图像扩增
据报道,图像扩增提高了视觉模型的泛化能力 (Shorten 和 Khshgoftaar, 2019)。**DeiT** (Touvron 等人, 2020) 尝试了各种扩增技术 (Zhang 等人, 2017; Yun 等人, 2019; Berman 等人, 2019; Hoffer 等人, 2020; Cubuk 等人, 2020),并发现它们有利于 ViT 训练。然而,在 VLP 模型中尚未探讨图像扩增的影响。缓存视觉特征 限制了基于区域特征的 VLP 模型 使用图像扩增。尽管它具有适用性,但 Pixel-BERT 也未研究其影响。
为此 (To this end),我们在微调过程中应用了 RandAugment (Cubuk 等人, 2020)。我们使用了所有的原始策略,**除了两种策略**:**color inversion**,因为 **文本通常也包含颜色信息**,以及 **cutout**,因为 **可能会删除分散在整个图像中的小但重要的物体**。我们使用  作为超参数。我们将在第 4.5 节和第 5 节中讨论它的影响。
四、实验
4.1 概览
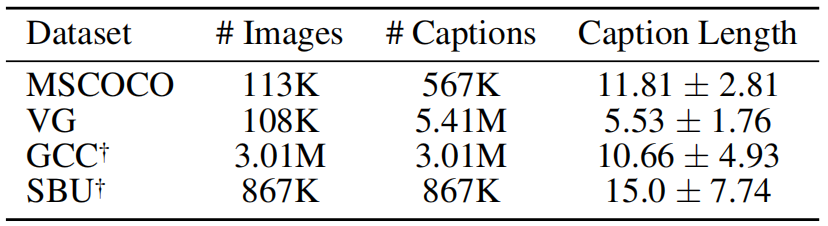
表 1:预训练数据集统计信息。
描述文字长度 (caption length) 指的是经预训练 bert-base-uncased tokenizer 处理的 tokens 长度。
GCC 和 SBU 仅提供了图像的 URLs,故我们从仍然可访问的 URL 中收集图像。
我们使用 4 个数据集用于预训练: **Microsoft COCO (MSCOCO) **(Lin et al., 2014), **Visual Genome (VG) **(Krishna et al., 2017), **SBU Captions (SBU)** (Ordonez et al., 2011), 和 **Google Conceptual Captions (GCC) **(Sharma et al., 2018)。表 1 展示了数据集的统计信息。
我们对两种经广泛探索的视觉和语言下游任务进行评估:对于 **分类**,使用** VQAv2** (Goyal 等人, 2017) 和 **NLVR2** (Suhr 等人, 2018),对于 **检索**,使用** **由 Karpathy & Fei-Fei (2015) 重新划分的 **MSCOCO **和 **Flickr30K (F30K) **(Plummer 等人, 2015)。对于 **分类 **任务,我们对对头部和数据排序使用三种不同的初始化种子,并进行了三次微调,报告了平均分数。我们在表 5 中报告了标准差和消融研究。对于 **检索 **任务,我们只进行一次微调。
4.2 实施细节
在所有实验中,使用 **AdamW **优化器 (Loshchilov& Hutter, 2018),基础学习率为 1e-4,权重衰减为1e-2。学习率在总训练步数的前 10% 中被 warm up,并在其余训练步数中线性衰减到 0。注意,如果为每个任务自定义超参数,那么下游的性能可能会进一步提高。
我们 **将输入图像的较短边 resize 为 384,并将较长边限制在 640 以下,同时保持长宽比 (aspect ratio)**。这种调整方案也用于其他 VLP 模型的目标检测,但具有更大尺寸的较短边 (800)。一张分辨率为 **384×640** 的图像,通过 ViLT-B/32 的图像块投影生成 **12×20 = 240** 个大小为 **32×32 **的图像块。由于这是一个很少能到达的上限,我们在预训练期间 **最多采样 200 个 **图像块。我们 **插值** ViT-B/32 的 **位置嵌入**  **来适应每幅图像的尺寸**,并填充图像块用于批训练 **(即将所有图像 padding 到同一尺寸从而构成 batch)**。注意,所得到图像分辨率 **比 800×1333 小 4 倍 **(即 200×333.25),这是 **所有其他 VLP 模型用于输入其视觉嵌入器的尺寸** (指的是 800×1333 吗???)。
我们使用** bert-base-uncased tokenizer **来 tokenize 文本输入。我们并不微调经预训练的 BERT,而是 **从头开始学习 **与文本嵌入相关的参数 、 和 。虽然表面上是有益的 (beneficial prima facie),但 **使用仅文本预训练过的 BERT 并不能保证视觉和语言下游任务的性能提高**。Tan & Bansal 已经报道了反证 (counterevidence),其中,**使用经预训练的 BERT 参数初始化,比从头开始训练的性能更弱**。
我们在 64 个 NVIDIA V100 GPU 上对 ViLT-B/32 进行 100K 或 200K 步的预训练,batch size = 4096。对于所有的下游任务,我们训练了10 个 epoch,VQAv2/检索任务为 256,NLVR2 为 128。
4.3 分类任务
我们在两个常用的数据集上评估了 ViLT-B/32:VQAv2 和 NLVR2。我们使用一个隐层大小为 1536 的两层 MLP 作为微调的下游头部。
4.3.1 视觉问题回答
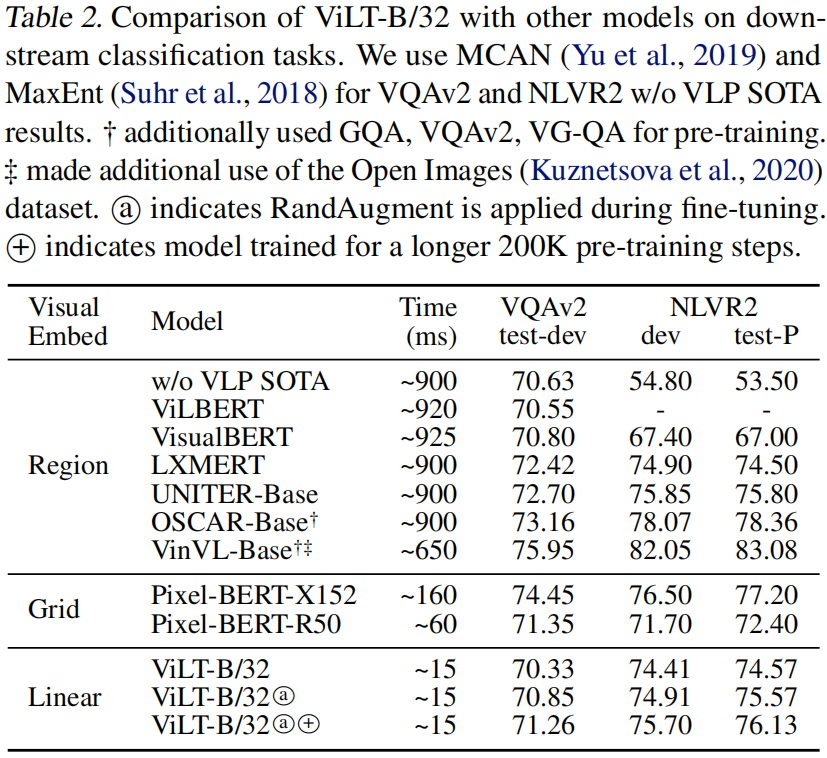
VQAv2 任务用自然语言询问给定图像和问题的答案。标注的答案最初是自由形式的自然语言,但常见的做法是 **将任务转换为包含 3129 个答案类别的分类任务**。根据这一实践,我们基于 VQAv2 训练集和验证集微调了 ViLT-B/32,同时保留了 1000 张验证图像及其相关问题用于内部验证。
我们报告了提交给评估服务器的测试开发 (test-dev) 得分结果 (VQA 得分是通过比较推断出的答案和 10 个基本真实的答案来计算的,详见https://visualqa.org/ evaluation.html)。与其他具有重量视觉嵌入器的 VLP 模型相比,ViLT 的 VQA 得分不足。我们 **怀疑由目标检测器生成的分离对象表示 (detached object representation) 可以简化 VQA 的训练,因为 VQA 中的问题通常是关于对象的**。
4.3.2 视觉推理的自然语言
NLVR2 任务是一个二元分类任务,其给定由两幅图像和一个自然语言问题构成的三元组 (triplets)。由于有两幅输入图像,因此存在多种策略 (UNITER 提出了三种下游头部设置:pair, triplet, pair-biattn)。继 OSCAR (Li 等人, 2020b) 和 VinVL (Zhang 等人, 2021) 之后,我们使用** pair 方法**。在这里,**三元组输入被重新构造为两个对 (问题, 图像1) 和 (问题, 图像 2)**,每个对都用于 ViLT。**头部将两个经池化表示  的拼接作为输入,并输出二元预测**。
表 2 展示了结果。考虑到其显著的推理速度,ViLT-B/32 在两个数据集上都保持了竞争性能。
4.4 检索任务
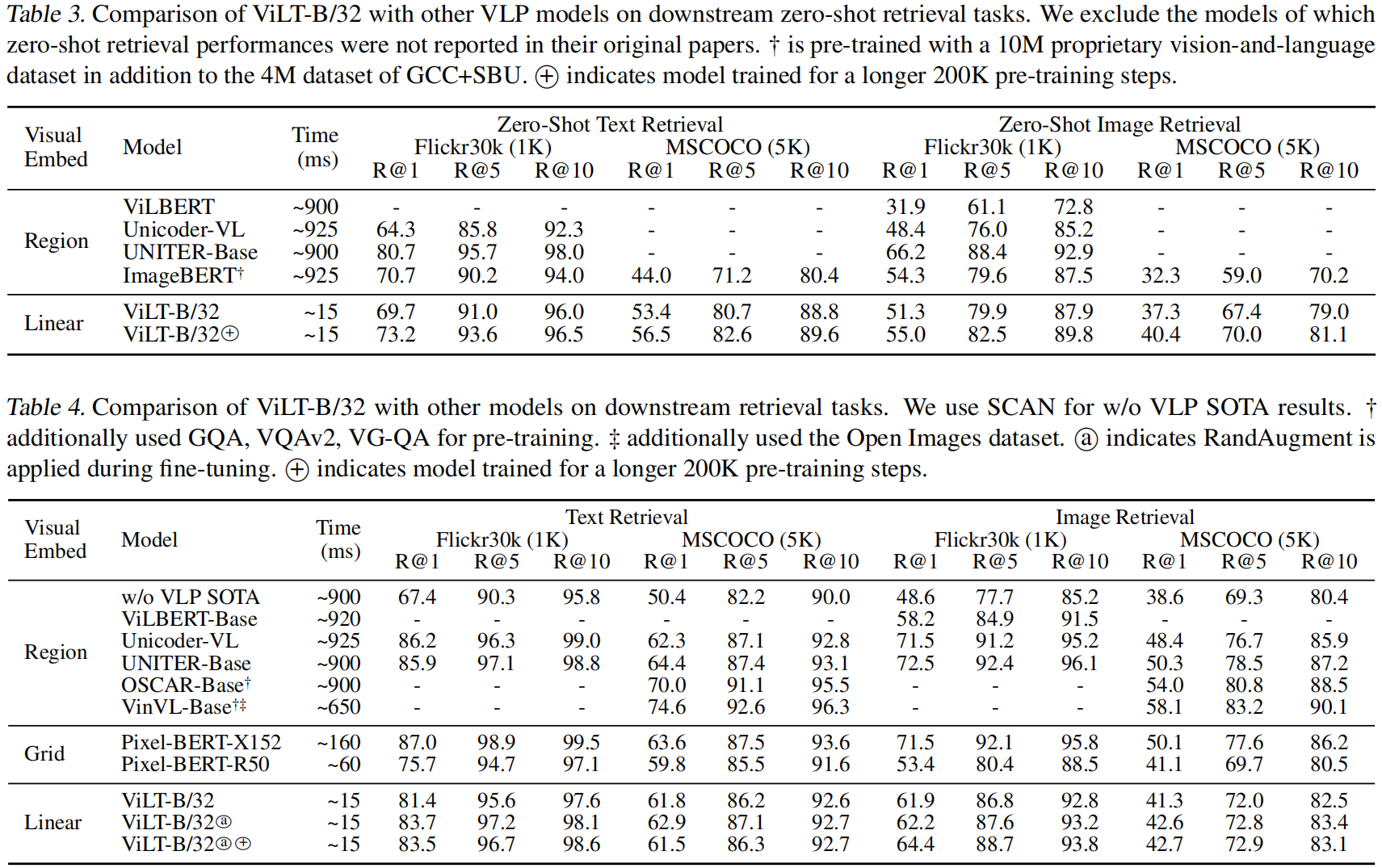
我们使用 Karpathy & Fei-Fei (2015) 重新划分 (split) 的 MSCOCO 和 F30K 数据集对 ViLT-B/32 进行了微调。对于图像到文本和文本到图像的检索 (跨模态检索),我们 **同时衡量零次和微调性能 **(R@K 对应于 GT 是否包含在验证集的 topK 个结果中)。我们 **使用经预训练的 ITM 头部来初始化相似性得分头部**,特别是 **计算 true-pair logits 的部分**。我们抽取 15 个随机文本作为负样本,并使用交叉熵损失调整 (tune) 模型,以最大化正对的得分。
我们在表 3 中报告了零次检索结果,在表 4 中报告了微调结果。在零次检索时,尽管 ImageBERT 在更大的 (14M) 数据集上预训练,但ViLT-B/32 总体上优于 ImageBERT。在微调检索中,ViLT-B/32 的召回率 **远高于 (by a large margin than)** 第二快的模型 (Pixel-BERT-R50)。
4.5 消融实验
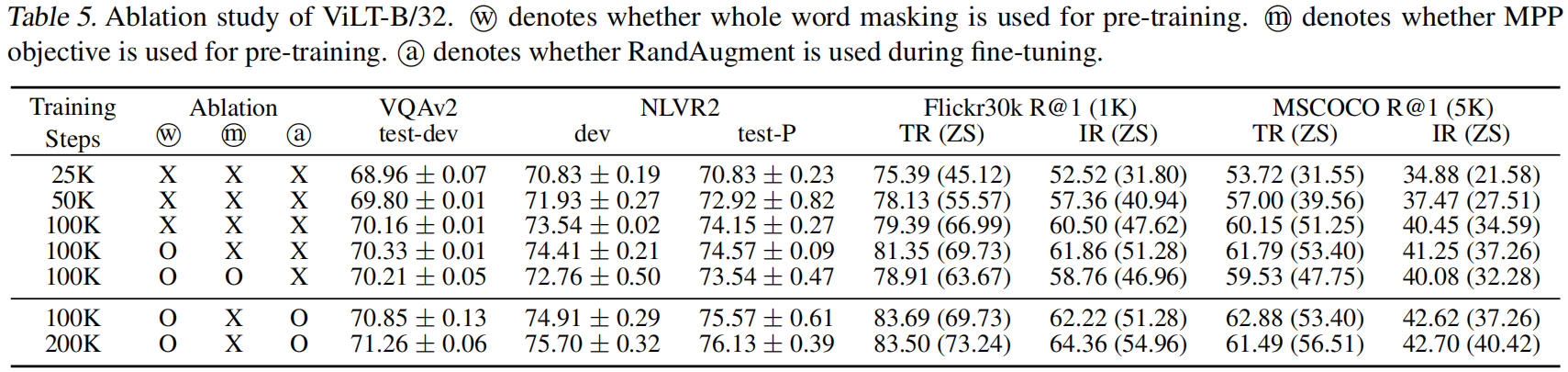
在表 5 中,我们进行了各种消融。**更多的训练步数,全词掩码,和图像增广都是有益的,而一个额外的训练目标则没有帮助**。
据报道,训练迭代的次数会影响自监督模型的性能 (Devlin 等人, 2019; Chen 等人, 2020a;b)。由于 VLP 也是一种自监督训练的形式,我们研究了训练时间 (durations) 的影响。正如预期的那样,随着模型训练了更长的步数 (1~3 行),性能不断提升。为 MLM 目标 mask 全词 (3~4 行)和具有增广的微调 (第 6 行) 也提高了性能。进一步将训练迭代增加到 200K,提高了 VQAv2、NLVR2 和零次检索的性能。随着微调后的文本检索性能的下降,我们停止增加迭代次数避免超过 200K。
**一个额外的 掩码区域建模 (MRM) 目标是提高 VLP 模型性能的关键**,例如 Chen 等人 (2019)。我们用 **掩码图像块预测 (MPP)** (Dosovitskiy 等人, 2020) 进行实验,它以 与图像块投影相兼容的形式 模拟 (mimics) MRM 的效果影响。图像块  的掩码概率为 0.15,模型从其经上下文化的向量  预测经掩码的图像块的平均 RGB 值。然而,**MPP 对下游性能没有贡献** (4~5 行)。这一结果与 MRM 对目标检测的监督信号的MRM 目标形成鲜明对比 (in sharp contrast to)。
4.6 VLP 模型的复杂度分析
我们从各种角度分析了 VLP 模型的复杂度。在表 6 中,我们报告了 **参数数、浮点操作 (FLOPs) 数,以及可视化嵌入器和 Transformer 的推理延迟**。我们 **排除了文本嵌入器**,因为它被所有 VLP 模型共享 (FLOPs 和时间是可以忽略的,因为该操作是一个嵌入查找 (lookup)。bert-base-uncased 使用的 30K 嵌入字典有 23.47M 参数)。在 Xeon E5-2650 CPU 和 NVIDIA P40 GPU 上,平均延迟超过 10K 倍。
输入大小的图像分辨率 和 经拼接的多模态输入序列的长度 影响了 FLOPs 数。我们共同注意 (co-note) 到了序列的长度。**图像分辨率方面,基于区域的 VLP 模型 和 Pixel-BERT-R50 为 800×1333,Pixel-BERT-X152 为 600×1000,ViLT-B/32 为 384×640**。
在 Pixel-BERT 和 ViLT 中,视觉 tokens 在预训练时被采样,并全部用于微调。我们报告了视觉 tokens 的最大数量。
我们观察到,对于长度在 300 以下的输入序列,BERT-base-like Transformer 的运行时间变化仅 < 1ms。由于 ViLT-B/32 的图像块投影最多生成 240 个图像 tokens,所以即使它接收图像和文本 tokens 的组合,我们的模型仍可有效。
4.7 可视化

图 4 是一个 **跨模态对齐的示例**。WPA 的 transportation 计划表达了一个用粉红色突出显示的文本 token 的热图。**每个正方形方块 (square tile) 代表一个图像块,它的不透明度 (opacity) 表示从突出显示的单词 token 传递了 (transported) 多少部分 (mass)**。
更多的 IPOT 迭代 —— 在训练阶段超过 50 次 —— 帮助可视化热图收敛;根据经验,1000 次迭代就足以得到一个清晰可辨的热图。我们对每个 token 的计划进行 z-normalize,并将值夹断至 [1.0, 3.0]。
五、结论及未来工作
在本文中,我们提出了一个最小的 VLP 架构,视觉和语言 Transformer (ViLT)。ViLT 能够胜任那些大量配备卷积视觉嵌入网络 (如 Faster R-CNN 和 ResNets) 的竞争者。我们要求未来关于 VLP 的工作 **更多地关注 Transformer 模块内部的模态交互**,而不是参与一场仅仅推动联合模态 (unimodal) 嵌入器的军备竞赛。尽管 ViLT-B/32 非常引人注目,但它更多地证明了 **没有卷积和区域监督的高效 VLP 模型仍然是具有竞争力的**。最后,我们指出了一些可能加到 ViLT 家族的因素。
5.1 扩展性
如关于大型 Transformer 论文所示 (Devlin 等人, 2019; Dosovitskiy 等人, 2020),给定适当的数据量,预训练过的 Transformer 的性能能够良好扩展 (scale well)。这一观察结果为更好地实施 ViLT 变体 (如 ViLT-L (Large) 和 ViLT-H (Huge)) 铺平了道路 (paves the way for)。我们将训练更大的模型留给未来的工作,因为经对齐的视觉和语言数据集仍然稀缺 (are yet scarce)。
5.2 视觉输入的掩码建模
考虑到 MRM 的成功,我们推测,通过将信息保留至 Transformer 的最后一层,视觉模态的掩蔽建模目标是有帮助的。然而,如表 5 所示,图像块 (MPP) 上的 MRM 的一个朴素 (naive) 变体失败了。Cho 等人 (2020) 提出用掩码对象分类 (MOC) 任务来训练他们的网格 RoIs。然而,本研究中的视觉词汇簇 (cluster) 在视觉和语言预训练期间 与 视觉主干一起是固定的。对于可训练的视觉嵌入器,一次性簇 (cluster) 不是一个可行的选择。我们认为,可以应用交替聚类 (Caron et al., 2018; 2019) 或同时聚类 (Asano et al., 2019; Caron et al., 2020) 研究的方法。
我们鼓励未来的工作,不使用区域监督来设计一个更复杂的视觉形态的掩码目标。
5.3 增广策略
先前关于对比视觉表征学习的工作 (Chen et al., 2020a; b) 表明,与更简单的增强策略相比,RandAugment 未用到的高斯模糊给下游性能带来了显著的收益 (He et al., 2020)。为文本和视觉输入探索适当的增强策略将是一个有价值的补充 (valueable addition)。
版权归原作者 何处闻韶 所有, 如有侵权,请联系我们删除。