
当前OpenAI提出的CLIP是AI领域内最火热的多模态预训练模型,简单的图文双塔结构让多模态表征学习变得异常简单。此前CLIP只有官方英文版本,如果想在中文领域尤其是业务当中使用这种强大的表征模型,需要非常麻烦的翻译工作。近期达摩院提出中文版本CLIP,Chinese CLIP系列,在ModelScope和Github均已开源,并且代码也已经并入Huggingface Transformers,在检索任务上效果非常好。这里就根据Chinese CLIP官方介绍来做个简单的快速上手指南。
Github: GitHub - OFA-Sys/Chinese-CLIP: Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation.
ArXiv: https://arxiv.org/abs/2211.01335
中文CLIP简介
Chinese CLIP作为CLIP的中文版,几乎没有做太多复杂的模型改进,主要就是将预训练数据替换成大约2亿规模的主要以中文原生数据为主的图文对数据。而针对CLIP训练成本高训练难度大的问题,Chinese CLIP采用了两阶段训练的方案:

图文双塔分别用已有的预训练模型初始化,分别为CLIP的图像塔和中文RoBERTa。在第一阶段训练中,图像侧参数冻结,让文本塔通过对比学习使其表征空间对齐CLIP的图像表征空间,而在第二阶段,模型在通过对比微调学习中文原生的图像和文本数据。
快速使用
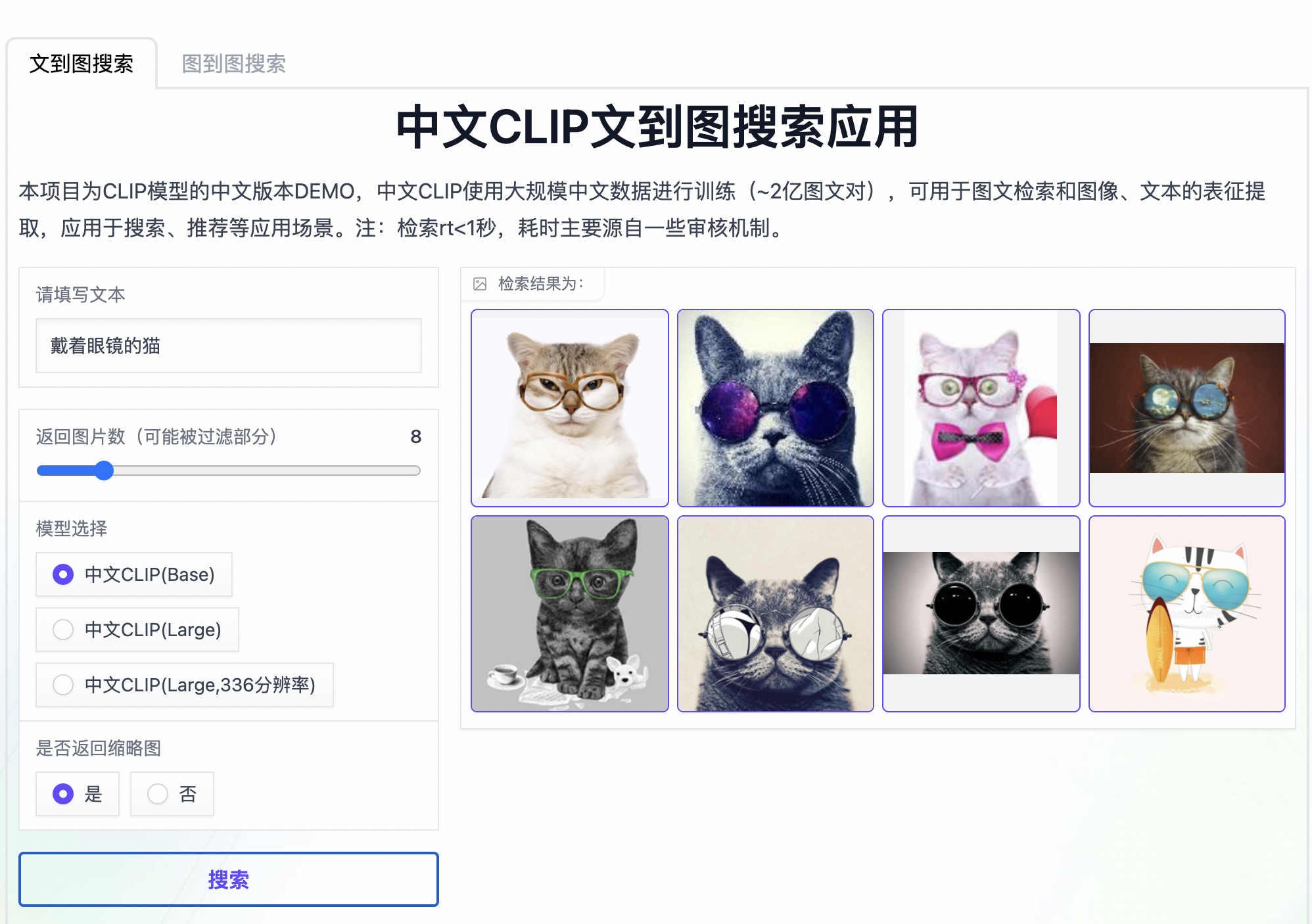
在上手代码前,我看到官方还提供了检索和分类两种Demo,其中检索的Demo在ModelScope上,可以看到检索回来的结果基本是符合文字描述的,比如“戴眼镜的猫”这种:
Huggingface上有更加简洁的零样本分类的demo:
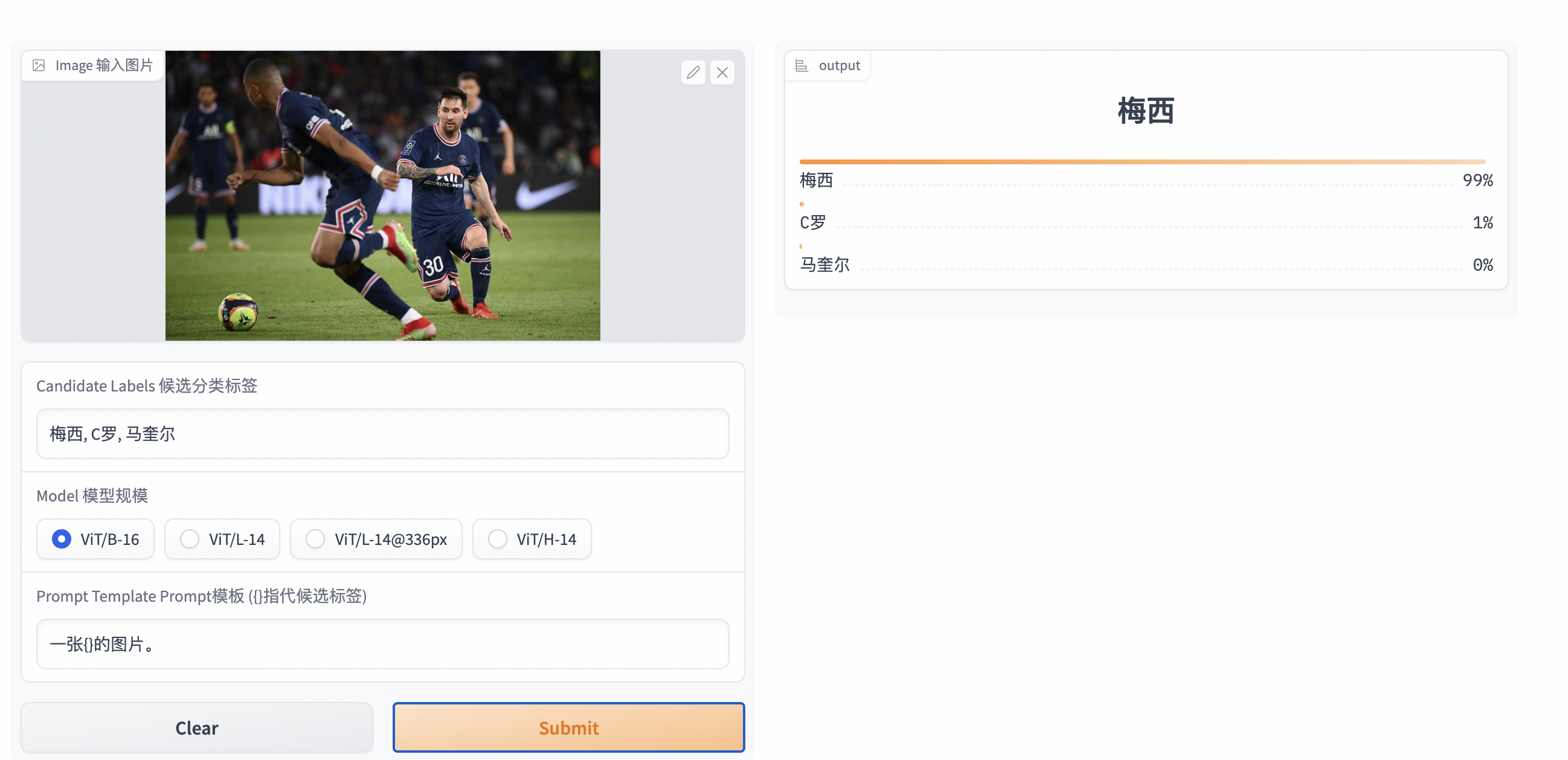
精准识别梅老板没啥问题(当然那个马大头属实是来搞笑的了……)
看了一下感觉官方给的API还是蛮简单的,首先先安装中文CLIP,可以直接安装pip包或者拉代码下来安装也行:
# 通过pip安装
pip install cn_clip
# 或者从源代码安装
cd Chinese-CLIP
pip install -e .
随后就是几行代码就可以快速产出特征,做个简单的零样本分类只需要把预先准备好的标签传入即可:
import torch
from PIL import Image
import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14', 'RN50']
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./')
model.eval()
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 对特征进行归一化,请使用归一化后的图文特征用于下游任务
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
logits_per_image, logits_per_text = model.get_similarity(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # [[1.268734e-03 5.436878e-02 6.795761e-04 9.436829e-01]]
代码的整体逻辑也都比较简单,首先可以看到可用的模型规模还是比较多的,ViT-H属实有点过大,但是ViT-B、ViT-L还是可以接受,ResNet-50就最良心,不过相对来说它的效果也会差些。在这里使用使用“load_from_name”这个接口,传入模型类型就可以完成模型载入的工作,然后使用preprocess就可以对图像做好预处理,文本就传入自己准备好的分类标签,放到一个列表里,传给clip.tokenize去完成接下来的工作。
产出特征的代码也比较简洁易懂,encode_image和encode_text分别负责产出图像和文本特征,随后完成归一化以后,用get_similarity的接口就可以算出图像文本的相似度,从而得出图像的分类概率。可以看到例子当中皮卡丘的图片在皮卡丘这一标签的分类概率也达到了94%,还是比较精准的。
除了官方API,ModelScope和Huggingface Transformers上的使用方法也都比较类似,在这里就不赘述了。大家可以自己去查看对应链接:
ModelScope 魔搭社区
https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16
小结
CLIP对于多模态用处还是比较大的,中文CLIP出现之后中文领域的多模态做起来也会容易很多,可以在检索、分类等众多场景发挥用户。本文简单介绍了官方提供的API的使用方法,后续会再继续补充文档上更详细的检索任务上的下游微调的方法。
版权归原作者 alimuhamad 所有, 如有侵权,请联系我们删除。