LSS (Lift, Splat, Shoot)论文精读
自动驾驶车辆的感知目标是从多个传感器中提取语义表示,并将这些表示融合到单一的“鸟瞰视图”坐标系中,供运动规划使用。我们提出了一种新的端到端架构,它可以直接从任意数量的相机图像数据中提取场景的鸟瞰视图表示。我们方法的核心思想是将每个图像单独“提升”到每个相机的特征锥体中,然后“涂抹”所有锥体到一个光栅
深度学习环境的配置
介绍:关于深度学习的框架有很多,比如国外的Pytorch,TensorFlow,Keras等等,国内的话例如百度的PaddlePaddle,华为的MindSpore。我们学习的以Pytorch为主,因为目前Pytorch是主流趋势,pytorch是动态框架,tensorflow是静态框架,动态框架可
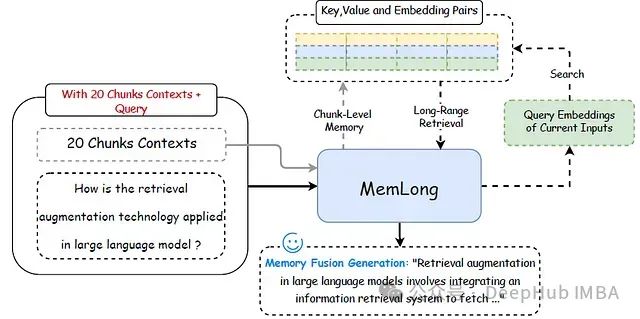
MemLong: 基于记忆增强检索的长文本LLM生成方法
本文将介绍MemLong,这是一种创新的长文本语言模型生成方法。MemLong通过整合外部检索器来增强模型处理长上下文的能力,从而显著提升了大型语言模型(LLM)在长文本处理任务中的表现。
【AI大模型】ChatGPT模型原理介绍(上)
ChatGPT 是由人工智能研究实验室 OpenAI 在2022年11月30日发布的全新聊天机器人模型, 一款人工智能技术驱动的自然语言处理工具. 它能够通过学习和理解人类的语言来进行对话, 还能根据聊天的上下文进行互动, 真正像人类一样来聊天交流, 甚至能完成撰写邮件、视频脚本、文案、翻译、代码等
一文彻底搞懂 Fine-tuning - 超参数(Hyperparameter)
最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
【爆火】TransUNet:融合Transformer与U-Net的医学图像分割神器!
在医学图像分割领域,传统的U-Net模型已经取得了显著成果。然而,随着Transformer在计算机视觉领域的崛起,将其与U-Net结合的TransUNet模型成为了新的热门。TransUNet是一种融合了Transformer和U-Net结构的深度学习模型,旨在提高医学图像分割的精度。它结合了Tr
数据集 | 人脸公开数据集的介绍及下载地址
本文介绍了人脸相关算法的数据集。
Datawhale X 李宏毅苹果书 AI夏令营-深度学习入门 Task 2
L1N∑nenLN1n∑en随机找到一组初始数值θ0θ0然后对每一个未知参数都计算对L的微分之后再集合起来,组成一个向量gg∂L∂θ1∣θθ0∂L∂θ2∣θθ0⋮\vdotsg∂θ1∂L∣θθ0∂θ2∂L∣θθ0⋮向量gg▽Lθ0g▽Lθ0。
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
本文对transformers之pipeline的文本分类(text-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用NLP中的文本分类(text-classification
AI:247-YOLOv8改进 | 基于ContextGuided的轻量级下采样方法实现大幅度性能提升
通过引入残差连接,减缓信息丢失,并促进梯度流动。:利用密集连接方式,增强特征重用,提高信息传递效率。:引入注意力机制,动态调整下采样过程中的特征权重。本文介绍了在YOLOv8中引入的ContextGuided下采样方法,以提升目标检测性能,特别是对小目标的检测效果。通过在YOLOv8的Backbon
【人工智能】枢纽:数据驱动洞察引领未来智能系统
人工智能是当今最具革命性的技术之一,从基础的机器学习、深度学习到更复杂的自然语言处理和强化学习,AI技术正在深刻影响各个行业。然而,随着技术的发展,AI也带来了伦理和安全方面的挑战。通过掌握人工智能的基本原理、算法和实际应用,未来的研究和工程师可以在这个领域继续推动创新并解决现实问题。
基于YOLO的植物病害识别系统:从训练到部署全攻略
使用Kaggle上的植物叶片病害数据集,包含多种植物叶片的病害图像和标注。数据集下载链接:https://www.kaggle.com/datasetsYOLO (You Only Look Once) 是一种快速准确的目标检测模型。YOLOv8/v7/v6/v5 是不同版本的YOLO模型,性能和速
ai工具推荐系列:文生图,图生图工具liblibAi
介绍一款比较专业的文生图工具
torch.nn.Linear的维度变换过程详解(有图有公式有代码)
当初在学习nn.Linear时了解到的博客都是关于一维变换的,比如输入3通道,输出6通道;又比如得到(3,4,4)的特征图,需要进行拉平为(48,)的向量,然后通过nn.Linear(48,10)得到10个输出(分类任务很常见)。nn.Linear除了可以进行分类,主要的作用就是改变维度便于下一个卷
深度学习笔记 # Datawhale X 李宏毅苹果书 AI夏令营
从零基础开始深度学习
如何解决NVIDIA显卡报错:uncorrectable ECC error的问题
线上问题出现的时候,如果国内的百度搜不到解决方案,就试试国际的Google,办法总比困难多。
《RMT: Retentive Networks Meet Vision Transformers》CVPR2024
这篇论文探讨了将Retentive Network(RetNet)的概念引入到计算机视觉领域,并与Vision Transformer结合,提出了一种新的模型RMT(Retentive Networks Meet Vision Transformers)。RetNet最初在自然语言处理(NLP)领域
AI模型应根据应用场景选择全能型或者专精型
AI模型的发展方向,在追求全能与专精之间并非简单的二选一,都取决于其应用场景、设计目标以及技术可行性等多个因素。这两种策略各有优势和局限性。综上所述,AI模型的发展策略应根据具体情况进行权衡和选择,既可以考虑追求专精以提高特定任务的性能,也可以考虑追求全能以提高模型的通用性和适应性。
YOLOv5改进 | 融合改进 | C3融合可变核卷积AKConv【附代码+小白可上手】
yolov5,模块融合,yolov5改进,C3_AKConv



