
在处理诸如文本之类的序列时,排序信息显然是至关重要的。为了结合排序信息而不是将序列视为集合,对位置信息进行编码是至关重要的。位置编码通过为每个位置分配嵌入向量并将其添加到相应的标记表示来实现这一点。绝对和相对位置编码是最常见的两种位置编码方式,但是本文将要比较更高级的位置编码方法:
1、RoPE 位置编码及其变体
2、CoPE
旋转位置编码
旋转位置编码(Rotary Positional Encoding,RoPE)是一种在自然语言处理(NLP)中处理序列数据时使用的技术。它旨在通过旋转方式将位置信息编码到输入的表示中,使得模型能更好地理解序列中元素的位置关系。关键思想是通过将上下文表示与旋转矩阵相乘来编码相对位置。RoPE随相对距离的增加而衰减。
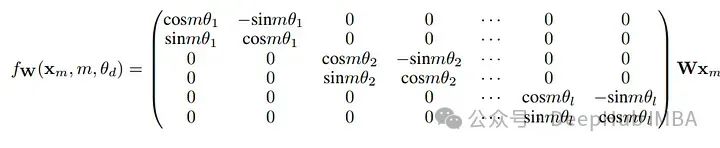
RoPE 的核心思想是通过在每个位置应用一个旋转矩阵到每个词元的嵌入上,从而将位置信息融入到词元的表示中。这种编码方式允许模型在处理序列数据时,能够更好地利用位置信息,提升语义理解和语言生成的质量。
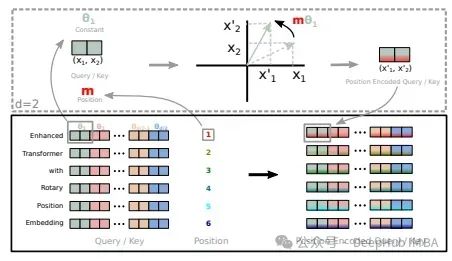
我们简单的实现一下RoPE:
defapply_rope(k, q, cis):
# Idea suppose vector v = [x,y,x1,y1,...] # v.shape = dim
# convert vetor into complex num # ie two vec one real, one imagery
# [x,y,x1,y1,...] -> x+iy, x1+iy1
# Multiplying by complex num == roatate vector
# => (x + iy) * (cos + isin) -> x'+iy'
# restack
# x'+iy' -> [x',y',x1',y1'...]
# you roated vector in chunks of two lfg!!!
_, seq_len, _, _=q.shape
freqs_cos, freqs_sin=cis
freqs_cos, freqs_sin=freqs_cos[:seq_len], freqs_sin[:seq_len]
# rehsape a shape (...,n )-> (..., n//2,2)
q_cis=q.float().reshape(
q.shape[:-1] + (-1, 2)
) # (B,T,nhead,C) -> (B,T,nhead,Cc,2) # Cc = C//2
k_cis=k.float().reshape(k.shape[:-1] + (-1, 2)) # (B,T,nhead,C) -> (B,T,nhead,Cc,2)
xq_r, xq_i=q_cis.unbind(-1) # (B,T,nhead,Cc,2) -> ((B,T,Cc), (B,T,Cc)) split into two tuple
xk_r, xk_i=k_cis.unbind(-1) # (B,T,nhead,Cc,2) -> ((B,T,Cc), (B,T,Cc))
freqs_cos=reshape_for_broadcast(freqs_cos, xq_r) # freqs.shape = (1,T,1,Cc)
freqs_sin=reshape_for_broadcast(freqs_sin, xq_r)
xq_out_r=xq_r*freqs_cos-xq_i*freqs_sin # (ac-bd) # shape = # (B,T,nhead,Cc)
xq_out_i=xq_r*freqs_sin+xq_i*freqs_cos # (ad+bc) * i
xk_out_r=xk_r*freqs_cos-xk_i*freqs_sin # (ac-bd)
xk_out_i=xk_r*freqs_sin+xk_i*freqs_cos # (ad+bc) * i
# now we stack r,i -> [r,i,r2,i2]
xq_out=torch.stack([xq_out_r, xq_out_i], dim=-1) # (B,T,nhead,Cc,2)
xk_out=torch.stack([xk_out_r, xk_out_i], dim=-1) # (B,T,nhead,Cc,2)
# flatten last two dimensions
xq_out=xq_out.flatten(3) # (B,T,nhead,C)
xk_out=xk_out.flatten(3) # (B,T,nhead,C)
returnxq_out.type_as(q), xk_out.type_as(q)
这是我们下面介绍的一些变体的基础,所以实现的比较简单。下面我们主要介绍一些变体:
基于旋转矩阵/旋转角度以及如何预先计算cos和sin频率,RoPE有三种变体。为了将模型的上下文长度扩展到预训练的极限之外,还会引入一些方法相关的函数。
线性旋转位置编码
在线性旋转位置编码中,通过引入以下方法相关函数g(m)和h(θ_d)来修改RoPE方程:
其中s为比例因子(扩展上下文长度与原始上下文长度之比),θ_d定义如下,b为底数(10000)
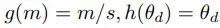
最后将波长(与频率成反比)描述为在维度d上嵌入RoPE以执行完整旋转(2π)所需的token长度。
实现如下:
defprecompute_freqs_cis_linear(dim: int, end: int, theta: float=10000.0):
freqs=1.0/ (theta** (torch.arange(0, dim, 2)[: (dim//2)].float() /dim))
# [: (dim // 2)] for odd number truncation
t=torch.arange(end, device=freqs.device)
freqs=torch.outer(t, freqs).float() # gives diffrent angle vector
freqs_cos=torch.cos(freqs) # real
freqs_sin=torch.sin(freqs) # imaginary
returnfreqs_cos, freqs_sin
NTK
神经切线核(Neural Tangent Kernel,简称NTK)是一种在深度学习领域中被广泛研究的概念,它提供了一种框架来分析和理解神经网络训练过程中的动态行为。NTK是在无限宽度极限下的神经网络中定义的,即当网络的层宽度趋向于无限大时,网络的行为可以通过一个固定的核函数来描述。
NTK 核贡献在于将传统的神经网络训练过程与核方法联系起来。在无限宽度的假设下,神经网络在初始化后的行为可以被描述为一个线性模型,其权重通过NTK进行更新。这意味着,在这种情况下,神经网络的学习动态可以通过解析形式来精确计算,而这通常在有限宽度的网络中是不可能的。
NTK 感知插值解决了在插值RoPE嵌入时丢失高频信息的问题,通过减少对高频的缩放,增加对低频的缩放,这与将RoPE的每个维度均匀地缩放一个因子s不同,所以只需对θ的值执行基本变化即可完成,代码如下:
defprecompute_freqs_cis_ntk(dim: int, end: int, theta: float=10000.0, alpha: int=16):
theta=theta*alpha** (dim/ (dim-2))
freqs=1.0/ (theta** (torch.arange(0, dim, 2)[: (dim//2)].float() /dim))\
t=torch.arange(end, device=freqs.device)
freqs=torch.outer(t, freqs).float()
freqs_cos=torch.cos(freqs) # real
freqs_sin=torch.sin(freqs) # imaginary
returnfreqs_cos, freqs_sin
YaRN
YaRN(Yet another RoPE extensioN)是通过一种高效的计算方法来扩展模型的上下文窗口,比以前的方法减少10倍的令牌和2.5倍的训练步骤。它引入了一个ramp函数,并将该函数合并到方法依赖函数中,如下所示:
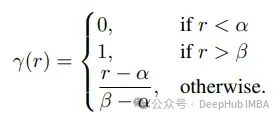
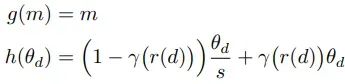
defprecompute_freqs_cis_yarn(dim: int, original_max_position_embeddings: int, theta: float=10000.0, scale: int=16, beta_fast:int=32, beta_slow:int=1, mscale: float=0.707, max_position_embeddings: int=2048):
pos_freqs=theta** (torch.arange(0, dim, 2)[: (dim//2)].float() /dim)
inv_freq_extrapolation=1.0/pos_freqs
inv_freq_interpolation=1.0/ (scale*pos_freqs)
low=max(math.floor(dim*math.log(original_max_position_embeddings/(beta_fast*2*math.pi)))/(2*math.log(theta)),0)
high=min(math.ceil(dim*math.log(original_max_position_embeddings/(beta_slow*2*math.pi)))/(2*math.log(theta)),dim-1)
linear_func= (torch.arange(dim//2, dtype=torch.float32) -low) / (high-low)
ramp_func=torch.clamp(linear_func, 0, 1).float().to(device=pos_freqs.device)
inv_freq_mask=1-ramp_func
inv_freq=inv_freq_interpolation* (1-inv_freq_mask) +inv_freq_extrapolation*inv_freq_mask
_mscale=float((0.1*math.log(scale) +1.0) *mscale)
t=torch.arange(max_position_embeddings, device=inv_freq.device, dtype=inv_freq.dtype) # torch.Size([2048])
freqs=torch.outer(t, inv_freq) # torch.Size([2048, 48])
dtype=torch.get_default_dtype()
freqs_cos=freqs.cos() *_mscale
freqs_sin=freqs.sin() *_mscale
returnfreqs_cos, freqs_sin
上下文位置编码(CoPE)
上下文位置编码(Contextual Positional Encoding,简称CoPE)是一种在处理序列数据时用于提高模型性能的技术。这种编码方法在自然语言处理(NLP)和其他需要处理时间序列数据的任务中尤其重要,因为它可以更好地捕获序列中元素的上下文关系。
传统的位置编码(如Transformer中使用的正弦位置编码)通常是静态的,即对于给定的位置,位置编码总是相同的,不考虑序列的具体内容。而上下文位置编码(CoPE)则试图根据序列中的实际内容动态调整位置编码,使编码反映出序列中每个元素的上下文环境。
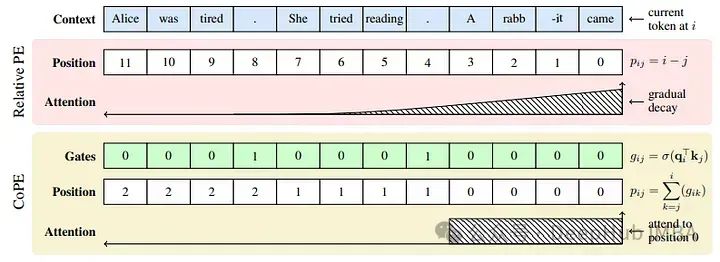
门控机制
门控决定包含哪些令牌,以便使用它们的上下文向量来计算位置编码,并为每个查询键对计算一个门控值。:
值为1表示标记号在位置计数中被考虑,而值为0表示它被忽略。
计算位置嵌入
要计算位置嵌入,需要添加当前令牌和之前所有令牌之间的门值。每个位置可以表示给定序列中的一个记号/单词/句子号。
为了计算有限的位置,即如果门是稀疏激活的(当计算句子时),可以用更少的位置覆盖序列长度T的整个上下文,并将每个位置夹在最大可能的位置内。
因为添加了sigmoid输出[0,1],得到的每个第i个位置值都是[0,i]内的浮点数。所以位置是不可学习的,不能由嵌入层计算。
位置嵌入的插值
为了克服上述由于位置值浮动而导致的学习嵌入层的限制,会对序列中的每个整数位置分配一个可学习的位置嵌入e[p],第ij个元素的位置嵌入将是由上述计算的分数位置值加权的两个最接近的整数嵌入之间进行简单的插值。
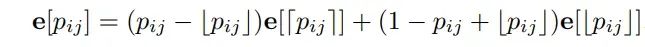
最后通过添加关键向量中的位置嵌入来计算注意力。
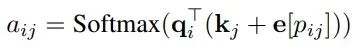
CoPE的实现
为了节省内存和计算,q.e[p]矩阵会被预先计算,这样可以进一步进行插值,然后添加到上下文中。插值计算如下:
classCoPE(nn.Module):
def__init__(self, npos_max, head_dim):
super().__init__()
self.npos_max=npos_max
self.pos_emb=nn.Parameter(torch.zeros(1, head_dim, npos_max))
defforward(self, query, attn_logits):
# Compute positions
gates=torch.sigmoid(attn_logits)
pos=gates.flip(-1).cumsum(dim=-1).flip(-1)
pos=pos.clamp(max=self.npos_max-1)
# Interpolate from integer positions
pos_ceil=pos.ceil().long()
pos_floor=pos.floor().long()
logits_int=torch.matmul(query, self.pos_emb)
logits_ceil=logits_int.gather(-1, pos_ceil)
logits_floor=logits_int.gather(-1, pos_floor)
w=pos-pos_floor
returnlogits_ceil*w+logits_floor* (1-w)
给定查询矩阵和查询键乘积,CoPE类的前向传播可以返回内插的位置嵌入。下面就是要将它们添加到Attention类中的attn_mtx上下文中。
classAttention(nn.Module):
def__init__(self, model_args: MOEConfig):
super().__init__()
d_model=model_args.d_model
self.num_heads=model_args.num_heads
self.head_dim=model_args.d_model//model_args.num_heads
self.num_kv_heads= (
model_args.num_headsifmodel_args.num_kv_heads==0elsemodel_args.num_kv_heads
)
assertself.num_heads%self.num_kv_heads==0
self.num_queries_per_kv=self.num_heads//self.num_kv_heads
self.cope=CoPE(model_args.seq_len,self.head_dim)
self.key=nn.Linear(d_model, self.head_dim*self.num_heads)
self.query=nn.Linear(d_model, self.head_dim*self.num_kv_heads)
self.value=nn.Linear(d_model, self.head_dim*self.num_kv_heads)
self.proj=nn.Linear(d_model, d_model, model_args.bias)
self.attn_dropout=nn.Dropout(model_args.dropout)
self.res_dropout=nn.Dropout(model_args.dropout)
self.flash_attn=hasattr(torch.nn.functional, "scaled_dot_product_attention")
defforward(self, x: torch.Tensor, mask: torch.Tensor, freqs_cis) ->torch.Tensor:
batch, seq_len, d_model=x.shape
k: torch.Tensor
q: torch.Tensor
v: torch.Tensor
k=self.key(x)
q=self.query(x)
v=self.value(x)
k=k.view(
batch, seq_len, self.num_heads, self.head_dim
) # shape = (B, seq_len, num_heads, head_dim)
q=q.view(batch, seq_len, self.num_heads, self.head_dim)
v=v.view(batch, seq_len, self.num_heads, self.head_dim)
q, k=apply_rope(q, k, freqs_cis)
# Grouped Query Attention
ifself.num_kv_heads!=self.num_heads:
k=torch.repeat_interleave(k, self.num_queries_per_kv, dim=2)
v=torch.repeat_interleave(v, self.num_queries_per_kv, dim=2)
k=k.transpose(1, 2) # shape = (B, num_heads, seq_len, head_dim)
q=q.transpose(1, 2)
v=v.transpose(1, 2)
attn_mtx=torch.matmul(q, k.transpose(2, 3)) /math.sqrt(self.head_dim)
attn_mtx=attn_mtx+mask[:, :, :seq_len, :seq_len]
print("Before:", attn_mtx[0, 0, :3, :3])
attn_mtx+=self.cope(q,attn_mtx)
print("AFTER:", attn_mtx[0, 0, :3, :3])
attn_mtx=F.softmax(attn_mtx.float(), dim=-1).type_as(k)
attn_mtx=self.attn_dropout(attn_mtx)
output=torch.matmul(attn_mtx, v) # (batch, n_head, seq_len, head_dim)
# restore time as batch dimension and concat heads
output=output.transpose(1, 2).contiguous().view(batch, seq_len, d_model)
# final projection into the residual stream
output=self.proj(output)
output=self.res_dropout(output)
returnoutput
attn_mtx += self.cope(q, attn_mtx)是将cope嵌入添加到上下文的地方。
CoPE通过引入与序列内容相关的动态位置信息,使模型能更准确地理解和处理语言中的长距离依赖关系,例如在复杂的句子或文档中正确解释词义和句子结构。在处理多样化或特定领域的数据时,CoPE可以通过适应不同的文本特征和结构,提高模型的灵活性和泛化能力。在一些需要高度上下文感知的任务中,如机器翻译、文本摘要或对话系统,CoPE能够显著提升模型的性能。
总结
以下是本文介绍的一些方法的论文,供参考:
https://arxiv.org/abs/2104.09864
https://arxiv.org/abs/2306.15595
https://arxiv.org/abs/2310.05209
https://arxiv.org/abs/2309.00071
https://arxiv.org/abs/2405.18719
作者:Zain ul Abideen