
注意力机制是许多最先进神经网络架构的基本组成部分,比如Transformer模型。注意力机制中的一个关键方面是掩码,它有助于控制信息流,并确保模型适当地处理序列。
在这篇文章中,我们将探索在注意力机制中使用的各种类型的掩码,并在PyTorch中实现它们。
在神经网络中,掩码是一种用于阻止模型使用输入数据中的某些部分的技术。这在序列模型中尤其重要,因为序列的长度可能会有所不同,且输入的某些部分可能无关紧要(例如,填充符)或需要被隐藏(例如,语言建模中的未来内容)。

掩码的类型
填充掩码 Padding Mask
在深度学习中,特别是在处理序列数据时,"填充掩码"(Padding Mask)是一个重要概念。当序列数据的长度不一致时,通常需要对短的序列进行填充(padding),以确保所有序列的长度相同,这样才能进行批处理。这些填充的部分实际上是没有任何意义的,不应该对模型的学习产生影响。
序列掩码 Sequence Mask
序列掩码用于隐藏输入序列的某些部分。比如在双向模型中,想要根据特定标准忽略序列的某些部分。
前瞻掩码 Look-ahead Mask
前瞻掩码,也称为因果掩码或未来掩码,用于自回归模型中,以防止模型在生成序列时窥视未来的符号。这确保了给定位置的预测仅依赖于该位置之前的符号。
填充掩码
填充掩码就是用来指示哪些数据是真实的,哪些是填充的。在模型处理这些数据时,掩码会用来避免在计算损失或者梯度时考虑填充的部分,确保模型的学习只关注于有效的数据。在使用诸如Transformer这样的模型时,填充掩码特别重要,因为它们可以帮助模型在进行自注意力计算时忽略掉填充的位置。
importtorch
defcreate_padding_mask(seq, pad_token=0):
mask= (seq==pad_token).unsqueeze(1).unsqueeze(2)
returnmask # (batch_size, 1, 1, seq_len)
# Example usage
seq=torch.tensor([[7, 6, 0, 0], [1, 2, 3, 0]])
padding_mask=create_padding_mask(seq)
print(padding_mask)
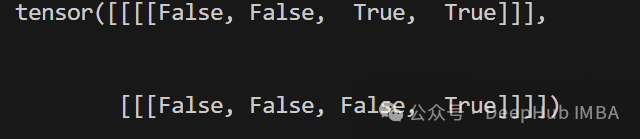
序列掩码
在使用如Transformer模型时,序列掩码用于避免在计算注意力分数时考虑到填充位置的影响。这确保了模型的注意力是集中在实际有意义的数据上,而不是无关的填充数据。
RNNs本身可以处理不同长度的序列,但在批处理和某些架构中,仍然需要固定长度的输入。序列掩码在这里可以帮助RNN忽略掉序列中的填充部分,特别是在计算最终序列输出或状态时。
在训练模型时,序列掩码也可以用来确保在计算损失函数时,不会将填充部分的预测误差纳入总损失中,从而提高模型训练的准确性和效率。
序列掩码通常表示为一个与序列数据维度相同的二进制矩阵或向量,其中1表示实际数据,0表示填充数据
def create_sequence_mask(seq):
seq_len = seq.size(1)
mask = torch.triu(torch.ones((seq_len, seq_len)), diagonal=1)
return mask # (seq_len, seq_len)
# Example usage
seq_len = 4
sequence_mask = create_sequence_mask(torch.zeros(seq_len, seq_len))
print(sequence_mask)
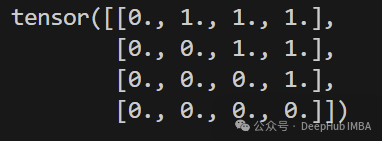
前瞻掩码 Look-ahead Mask
前瞻掩码通过在自注意力机制中屏蔽(即设置为一个非常小的负值,如负无穷大)未来时间步的信息来工作。这确保了在计算每个元素的输出时,模型只能使用到当前和之前的信息,而不能使用后面的信息。这种机制对于保持自回归属性(即一次生成一个输出,且依赖于前面的输出)是必要的。
在实现时,前瞻掩码通常表示为一个上三角矩阵,其中对角线及对角线以下的元素为0(表示这些位置的信息是可见的),对角线以上的元素为1(表示这些位置的信息是不可见的)。在计算注意力时,这些为1的位置会被设置为一个非常小的负数(通常是负无穷),这样经过softmax函数后,这些位置的权重接近于0,从而不会对输出产生影响。
def create_look_ahead_mask(size):
mask = torch.triu(torch.ones(size, size), diagonal=1)
return mask # (seq_len, seq_len)
# Example usage
look_ahead_mask = create_look_ahead_mask(4)
print(look_ahead_mask)
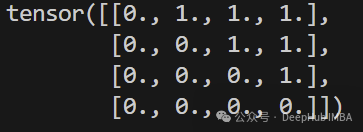
掩码之间的关系
填充掩码(Padding Mask)和序列掩码(Sequence Mask)都是在处理序列数据时使用的技术,它们的目的是帮助模型正确处理变长的输入序列,但它们的应用场景和功能有些区别。这两种掩码经常在深度学习模型中被一起使用,尤其是在需要处理不同长度序列的场景下。
填充掩码专门用于指示哪些数据是填充的,这主要应用在输入数据预处理和模型的输入层。其核心目的是确保模型在处理或学习过程中不会将填充部分的数据当作有效数据来处理,从而影响模型的性能。在诸如Transformer模型的自注意力机制中,填充掩码用于阻止模型将注意力放在填充的序列上。
序列掩码通常用于更广泛的上下文中,它不仅可以指示填充位置,还可以用于其他类型的掩蔽,如在序列到序列的任务中掩蔽未来的信息(如解码器的自回归预测)。序列掩码可以用于确保模型在处理过程中只关注于当前及之前的信息,而不是未来的信息,这对于保持信息的时序依赖性非常重要。
充掩码多用于模型的输入阶段或在注意力机制中排除无效数据的影响,序列掩码则可能在模型的多个阶段使用,特别是在需要控制信息流的场景中。
与填充掩码和序列掩码不同,前瞻掩码专门用于控制时间序列的信息流,确保在生成序列的每个步骤中模型只能利用到当前和之前的信息。这是生成任务中保持模型正确性和效率的关键技术。
在注意机制中应用不同的掩码
在注意力机制中,掩码被用来修改注意力得分。
importtorch.nn.functionalasF
defscaled_dot_product_attention(q, k, v, mask=None):
matmul_qk=torch.matmul(q, k.transpose(-2, -1))
dk=q.size()[-1]
scaled_attention_logits=matmul_qk/torch.sqrt(torch.tensor(dk, dtype=torch.float32))
ifmaskisnotNone:
scaled_attention_logits+= (mask*-1e9)
attention_weights=F.softmax(scaled_attention_logits, dim=-1)
output=torch.matmul(attention_weights, v)
returnoutput, attention_weights
# Example usage
d_model=512
batch_size=2
seq_len=4
q=torch.rand((batch_size, seq_len, d_model))
k=torch.rand((batch_size, seq_len, d_model))
v=torch.rand((batch_size, seq_len, d_model))
mask=create_look_ahead_mask(seq_len)
attention_output, attention_weights=scaled_dot_product_attention(q, k, v, mask)
print(attention_output)
我们创建一个简单的Transformer 层来验证一下三个掩码的不同之处:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0
self.depth = d_model // num_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.depth)
return x.permute(0, 2, 1, 3)
def forward(self, v, k, q, mask):
batch_size = q.size(0)
q = self.split_heads(self.wq(q), batch_size)
k = self.split_heads(self.wk(k), batch_size)
v = self.split_heads(self.wv(v), batch_size)
scaled_attention, _ = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous()
original_size_attention = scaled_attention.view(batch_size, -1, self.d_model)
output = self.dense(original_size_attention)
return output
class TransformerLayer(nn.Module):
def __init__(self, d_model, num_heads, dff, dropout_rate=0.1):
super(TransformerLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model)
self.layernorm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout_rate)
self.dropout2 = nn.Dropout(dropout_rate)
def forward(self, x, mask):
attn_output = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output)
out2 = self.layernorm2(out1 + ffn_output)
return out2
创建一个简单的模型:
d_model = 512
num_heads = 8
dff = 2048
dropout_rate = 0.1
batch_size = 2
seq_len = 4
x = torch.rand((batch_size, seq_len, d_model))
mask = create_padding_mask(torch.tensor([[1, 2, 0, 0], [3, 4, 5, 0]]))
transformer_layer = TransformerLayer(d_model, num_heads, dff, dropout_rate)
output = transformer_layer(x, mask)
然后在Transformer层上运行我们上面介绍的三个掩码。
def test_padding_mask():
seq = torch.tensor([[7, 6, 0, 0], [1, 2, 3, 0]])
expected_mask = torch.tensor([[[[0, 0, 1, 1]]], [[[0, 0, 0, 1]]]])
assert torch.equal(create_padding_mask(seq), expected_mask)
print("Padding mask test passed!")
def test_sequence_mask():
seq_len = 4
expected_mask = torch.tensor([[0, 1, 1, 1], [0, 0, 1, 1], [0, 0, 0, 1], [0, 0, 0, 0]])
assert torch.equal(create_sequence_mask(torch.zeros(seq_len, seq_len)), expected_mask)
print("Sequence mask test passed!")
def test_look_ahead_mask():
size = 4
expected_mask = torch.tensor([[0, 1, 1, 1], [0, 0, 1, 1], [0, 0, 0, 1], [0, 0, 0, 0]])
assert torch.equal(create_look_ahead_mask(size), expected_mask)
print("Look-ahead mask test passed!")
def test_transformer_layer():
d_model = 512
num_heads = 8
dff = 2048
dropout_rate = 0.1
batch_size = 2
seq_len = 4
x = torch.rand((batch_size, seq_len, d_model))
mask = create_padding_mask(torch.tensor([[1, 2, 0, 0], [3, 4, 5, 0]]))
transformer_layer = TransformerLayer(d_model, num_heads, dff, dropout_rate)
output = transformer_layer(x, mask)
assert output.size() == (batch_size, seq_len, d_model)
print("Transformer layer test passed!")
test_padding_mask()
test_sequence_mask()
test_look_ahead_mask()
test_transformer_layer()
结果和上面我们单独执行是一样的,所以得到如下结果
总结
最后我们来做个总结,在自然语言处理和其他序列处理任务中,使用不同类型的掩码来管理和优化模型处理信息的方式是非常关键的。这些掩码主要包括填充掩码、序列掩码和前瞻掩码,每种掩码都有其特定的使用场景和目的。
- 填充掩码(Padding Mask):- 目的:确保模型在处理填充的输入数据时不会将这些无关的数据当作有效信息处理。- 应用:主要用于处理因数据长度不一致而进行的填充操作,在模型的输入层或注意力机制中忽略这些填充数据。- 功能:帮助模型集中于实际的、有效的输入数据,避免因为处理无意义的填充数据而导致的性能下降。
- 序列掩码(Sequence Mask):- 目的:更广泛地控制模型应该关注的数据部分,包括但不限于填充数据。- 应用:用于各种需要精确控制信息流的场景,例如在递归神经网络和Transformer模型中管理有效数据和填充数据。- 功能:通过指示哪些数据是有效的,哪些是填充的,帮助模型更有效地学习和生成预测。
- 前瞻掩码(Look-ahead Mask):- 目的:防止模型在生成序列的过程中“看到”未来的信息。- 应用:主要用在自回归模型如Transformer的解码器中,确保生成的每个元素只能依赖于之前的元素。- 功能:保证模型生成信息的时序正确性,防止在生成任务中出现信息泄露,从而维持生成过程的自然和准确性。
这些掩码在处理变长序列、保持模型效率和正确性方面扮演着重要角色,是现代深度学习模型不可或缺的一部分。在设计和实现模型时,合理地使用这些掩码可以显著提高模型的性能和输出质量。