
在总结文章或回答给定段落的问题时,大语言模型可能会产生幻觉,并会根据给定的上下文回答不准确或未经证实的细节,这也被称为情境幻觉。为了解决这个问题,这篇论文的作者提出了一个简单的幻觉检测模型,其输入特征由上下文的注意力权重与新生成的令牌(每个注意头)的比例给出。它被称为回看或基于回看比率的检测器。
该方法计算为给定上下文的注意力权重与新生成的令牌的比值。在每个时间步,计算每个注意头的回看率,并训练一个线性分类器,称之为Lookback Lens,根据回看率特征检测上下文幻觉,如下图所示
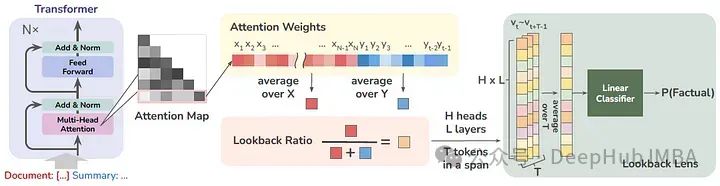
在解码过程中可以进一步整合该检测器,获得可减少幻觉的回看透镜引导解码策略
幻觉检测
Lookback Lens(回看透镜)
作者引入了回看比例,这是一个基于Transformer模型的注意力分布的度量 给定一个具有L层的Transformer,每层有H个头部,该模型处理一个输入序列的上下文标记X = {x1, x2, . . . , xN},长度为N,然后是一组新生成的标记Y = {y1, y2, . . . , yt−1}来生成下一个标记yt。在时间步t,对于每个头部,计算关注于上下文标记与新生成标记的注意力权重的比例 对于每个头部h在层l中,定义:
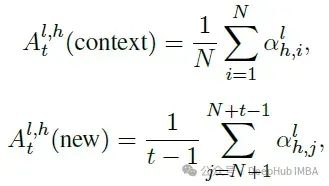
其中αl h,i和αl h,j分别是分配给上下文令牌X和新令牌Y的softmax激活的注意力权重
在时间步t的层l中头h的回看比例计算为
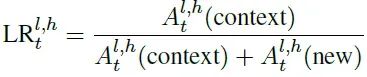
将回看比率作为输入特征,通过将所有头部和层的回看比率连接成时间步t的特征向量,用于检测幻觉:
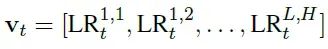
给定一个文本跨度 {yt, yt+1, …, yt+T−1},将相应的回看比率向量 {vt, vt+1, …, vt+T−1} 平均成一个单一向量 ¯v。然后使用逻辑回归分类器 F 基于平均后的回看比率向量来预测该跨度是事实(1)还是幻觉(0)。
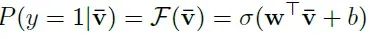
其中σ为sigmoid函数,w为权重向量,b为分类器的偏置项。
回看透镜预测跨度上幻觉的概率。作者考虑了以下两种方式来获取给定序列的跨度:
预定义跨度:当幻觉和非幻觉跨度的注释可用时,直接训练分类器来区分它们。
滑动窗口:由于在解码过程中没有预定义的跨度,因此使用滑动窗口设置,遍历所有可能的跨度。具体来说将句子处理成固定大小的块,并训练分类器来预测标签,如果块内存在任何幻觉内容,则预测为0,否则预测为1。
实验设置
下表显示了在NQ (QA)和CNN/DM (Sum.)上使用预定义的跨度分割和滑动窗口(size = 8)的分类任务的AUROC。
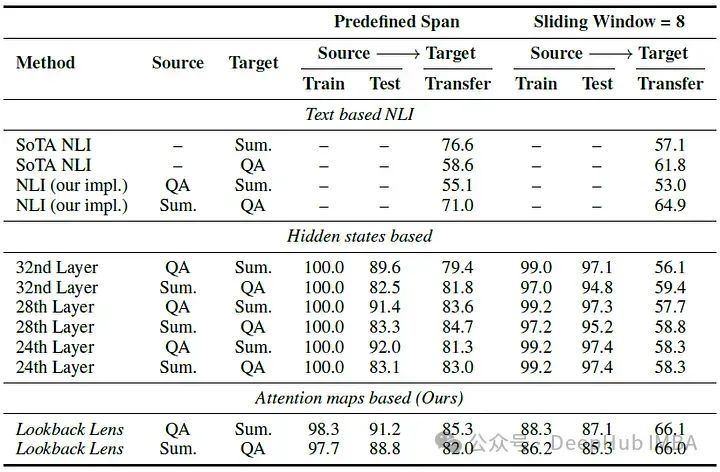
Lookback Lens的性能略好于基于隐藏状态的分类器,并且显著优于NLI模型。在滑动窗口设置中,回看镜头相对于基于隐藏状态的分类器的优势更为显著。基于隐藏状态的分类器在二次验证过程中容易出现训练集过拟合的问题,并且在转移到域外任务时表现出明显的性能下降
Lookback Lens虽然并不总是完美地拟合训练集,但在应用于域外任务时始终表现出更好的性能
上下文幻觉缓解
回看透镜引导解码
将回看镜头(F)整合到解码过程中:
F可以评估多个标记块,因为每个块在多个解码步骤中引起不同的注意力模式
给定上下文和部分生成的文本,在相同的解码步骤t独立采样一组k个候选块 {C1,C2, . . . ,Ck}。
对于每个块Cj,相关的回看比率被平均以形成特征向量¯vj
如下图所示,作者选择由F预测的最佳候选C∗并将其添加到生成中
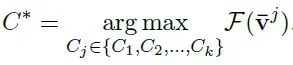
重复此过程,直到生成EOS令牌或达到最大长度

结果
下表显示了在块大小为8的情况下,每个块使用8个候选块的解码结果
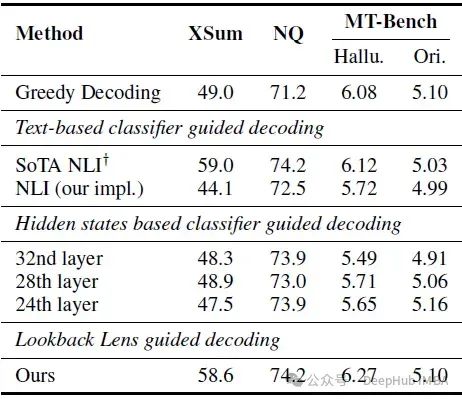
回看透镜引导解码可以提高领域内任务(XSum,提高了9.6%)和领域外任务(NQ,提高了3%)的性能。这一结果与使用SoTA NLI(自然语言推理)引导解码的效果相当,其中SoTA NLI在大约731k个注释的摘要示例上进行训练,这比论文的1k训练集大700倍。
由隐藏状态或NLI分类器引导的解码,这两者都是在相同数据上训练的,只能略微提高NQ的性能,但对XSum没有效果,这可能是由于分布偏移的问题,凸显了回看透镜在泛化能力上的优势。解码方法可以在幻觉设置中提高性能,同时保持在原始设置中的相同性能,这表明论文的解码方法在减少幻觉的同时不会影响整体生成质量。
跨模型迁移
使用回看比率捕捉用于幻觉检测的高级模型模式,突出了其在跨模型转移中的潜力。用一个模型的回看比率训练的分类器可以应用到另一个模型而无需重新训练,前提是目标模型的注意力模式与原始模型的注意力模式之间存在相关性。
在注意力图上训练的回看透镜可以从LLaMA-2–7B-Chat转移到LLaMA-2–13B-Chat而无需任何重新训练。下表显示了在检测任务上的跨模型转移结果。
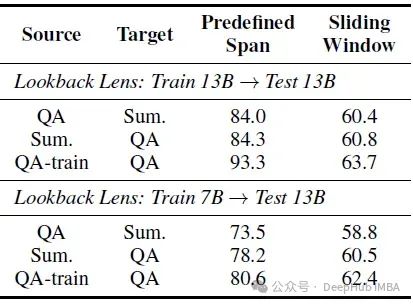
虽然与同一模型迁移相比,跨模型迁移产生的结果略差,但AUROC分数仍然很高。下表显示了使用贪婪解码和分类器引导采样方法(块大小为8)从LLaMA-2-7B-chat到LLaMA-2-13B-chat的交叉模型迁移。
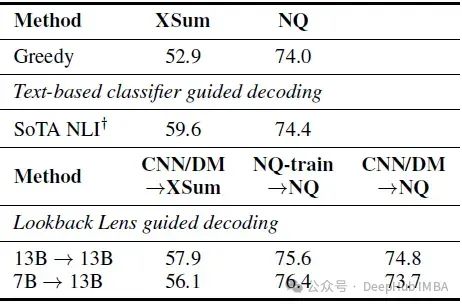
观察到使用13B本身或使用应用于13B解码的SoTA NLI模型进行同模型转移时的性能改善类似。然而,在跨任务+跨模型转移设置中:从CNN/DM(7B)到NQ(13B),我们没有观察到显著的改善,作者将其归因于较大的分布偏移。
限制
回看透镜引导解码的性能上限受到LLM自身采样能力的限制。尽管回看透镜是一个轻量级分类器,具有可以忽略不计的推理时间,但从LLM中采样多个候选者的需求增加了总推理时间。并且回看透镜依赖于大约1k-2k的注释示例来训练分类器。
总结
回看透镜是一个轻量级分类器,通过利用回看比率来检测上下文幻觉,回看比率仅从注意力权重中计算得出。这个分类器不仅有效地识别上下文幻觉,而且还通过从LLM的回看镜头引导解码来缓解它们。该方法可以在不同任务之间转移,甚至在映射其注意力头部后可以跨模型转移。
论文:
https://arxiv.org/abs/2407.07071
代码: