
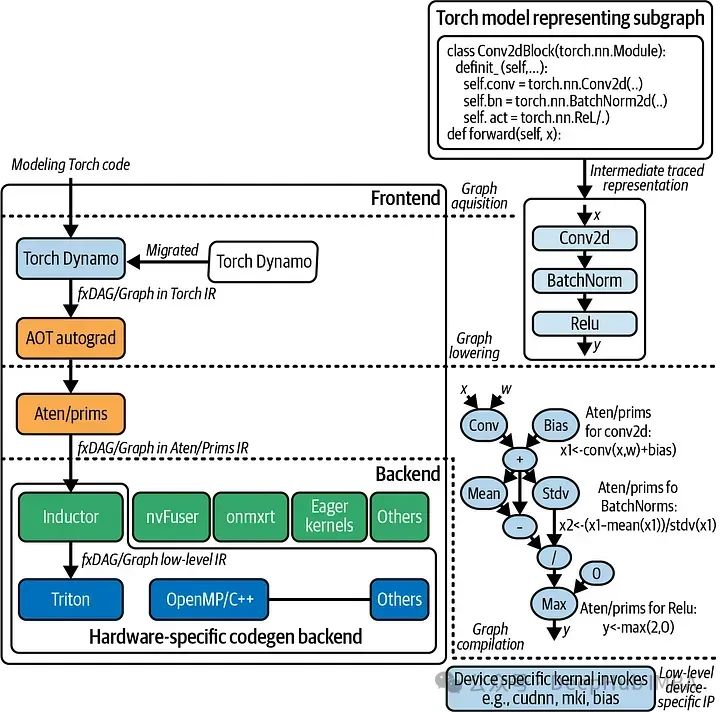
在深度学习中,优化模型性能至关重要,特别是对于需要快速执行和实时推断的应用。而PyTorch在平衡动态图执行与高性能方面常常面临挑战。传统的PyTorch优化技术在处理动态计算图时效果有限,导致训练时间延长和模型性能不佳。TorchDynamo是一种为PyTorch设计的即时(JIT)编译器,通过在运行时拦截Python代码、优化它,并编译成高效的机器代码来解决这一问题。本文通过使用合成数据集展示了TorchDynamo的实际应用,包括特征工程、超参数调整、交叉验证和评估指标。
TorchDynamo简介
TorchDynamo 是一个由 PyTorch 团队开发的编译器前端,它旨在自动优化 PyTorch 程序以提高运行效率。TorchDynamo 的工作原理是在运行时动态分析和转换 PyTorch 的代码,然后将其转发给各种后端编译器(如 TorchScript、TVM、Triton 等),从而实现性能的提升。
特别是在需要实时执行的应用中,如自动驾驶或金融预测等,深度学习模型要求快速执行。传统的优化技术经常需要在处理Python的动态特性时进行修订,这正是TorchDynamo的强项所在。它能够即时捕获计算图,针对特定的工作负载和硬件应用优化,从而减少延迟并提高吞吐量。
TorchDynamo的另外一个突出特点是其易于集成。重写整个代码库以集成新工具可能是一项艰巨的任务。但是TorchDynamo仅需要对现有的PyTorch工作流进行最小的更改。它的简单性和强大的优化能力使它成为经验丰富的研究人员和行业专业人士的有力选择。
将 TorchDynamo 集成到现有的 PyTorch 程序中相对简单,只需要在程序中导入 TorchDynamo 并使用它来包装模型的执行部分。
importtorch
importtorchdynamo
# 定义模型和优化器
model=MyModel()
optimizer=torch.optim.Adam(model.parameters())
# 使用 TorchDynamo 优化模型的训练过程
deftraining_step(input, target):
optimizer.zero_grad()
output=model(input)
loss=loss_fn(output, target)
loss.backward()
optimizer.step()
returnloss
# 使用 torchdynamo.optimize 包装训练步骤
optimized_training_step=torchdynamo.optimize(training_step)
# 训练循环
forinput, targetindata_loader:
loss=optimized_training_step(input, target)
TorchDynamo的工作原理
TorchDynamo通过追踪PyTorch代码的执行,动态地捕获计算图。这个过程涉及理解代码的依赖关系和流程,使其能够识别优化的机会。应用优化
一旦捕获了计算图,TorchDynamo就会应用各种优化技术。这些技术包括操作符融合,它将多个操作合并为一个单一操作以减少开销,以及改进内存管理,最小化数据移动并有效地重用资源。
优化计算图口,TorchDynamo将其编译成高效的机器码。这种编译可以针对不同的后端,如TorchScript或NVFuser,以确保代码在可用的硬件上以最佳方式运行。
在最后的执行阶段。与最初的Python代码相比,上面的优化可以显著提高性能。JIT编译确保在运行时期间应用这些优化,使执行适应不同的工作负载和输入数据。
使用示例
下面我们演示了使用一个合成数据集的TorchDynamo示例,包括特征工程,超参数调优,交叉验证,预测和结果解释。
importtorch
importtorch.nnasnn
importtorch.optimasoptim
importnumpyasnp
importpandasaspd
importmatplotlib.pyplotasplt
fromsklearn.model_selectionimporttrain_test_split, KFold
fromsklearn.metricsimportmean_squared_error, r2_score
fromsklearn.preprocessingimportStandardScaler
fromtorchimport_dynamoastorchdynamo
fromtypingimportList
# Generate synthetic dataset
np.random.seed(42)
torch.manual_seed(42)
# Feature engineering: create synthetic data
n_samples=1000
n_features=10
X=np.random.rand(n_samples, n_features)
[email protected](n_features) +np.random.rand(n_samples) *0.1 # Linear relation with noise
# Split data into train and test sets
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler=StandardScaler()
X_train=scaler.fit_transform(X_train)
X_test=scaler.transform(X_test)
# Convert to PyTorch tensors
X_train=torch.tensor(X_train, dtype=torch.float32)
y_train=torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
X_test=torch.tensor(X_test, dtype=torch.float32)
y_test=torch.tensor(y_test, dtype=torch.float32).view(-1, 1)
# Define the model
classSimpleNN(nn.Module):
def__init__(self, input_dim):
super(SimpleNN, self).__init__()
self.fc1=nn.Linear(input_dim, 64)
self.fc2=nn.Linear(64, 32)
self.fc3=nn.Linear(32, 1)
defforward(self, x):
x=torch.relu(self.fc1(x))
x=torch.relu(self.fc2(x))
x=self.fc3(x)
returnx
# Hyperparameters
input_dim=X_train.shape[1]
learning_rate=0.001
n_epochs=100
# Initialize the model, loss function, and optimizer
model=SimpleNN(input_dim)
criterion=nn.MSELoss()
optimizer=optim.Adam(model.parameters(), lr=learning_rate)
# Define custom compiler
defmy_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print("my_compiler() called with FX graph:")
gm.graph.print_tabular()
returngm.forward # return a python callable
@torchdynamo.optimize(my_compiler)
deftrain_and_evaluate(model, criterion, optimizer, X_train, y_train, X_test, y_test, n_epochs):
# Training loop with K-Fold Cross-Validation
kf=KFold(n_splits=5, shuffle=True, random_state=42)
train_losses_per_epoch=np.zeros(n_epochs)
val_losses_per_epoch=np.zeros(n_epochs)
kf_count=0
fortrain_idx, val_idxinkf.split(X_train):
X_kf_train, X_kf_val=X_train[train_idx], X_train[val_idx]
y_kf_train, y_kf_val=y_train[train_idx], y_train[val_idx]
forepochinrange(n_epochs):
model.train()
optimizer.zero_grad()
y_pred_train=model(X_kf_train)
train_loss=criterion(y_pred_train, y_kf_train)
train_loss.backward()
optimizer.step()
model.eval()
y_pred_val=model(X_kf_val)
val_loss=criterion(y_pred_val, y_kf_val)
train_losses_per_epoch[epoch] +=train_loss.item()
val_losses_per_epoch[epoch] +=val_loss.item()
kf_count+=1
# Average losses over K-Folds
train_losses_per_epoch/=kf_count
val_losses_per_epoch/=kf_count
# Evaluate on test data
model.eval()
y_pred_test=model(X_test)
test_loss=criterion(y_pred_test, y_test).item()
test_r2=r2_score(y_test.detach().numpy(), y_pred_test.detach().numpy())
returntrain_losses_per_epoch, val_losses_per_epoch, test_loss, test_r2
# Run training and evaluation with TorchDynamo optimization
train_losses, val_losses, test_loss, test_r2=train_and_evaluate(model, criterion, optimizer, X_train, y_train, X_test, y_test, n_epochs)
# Print metrics
print(f"Test MSE: {test_loss:.4f}")
print(f"Test R^2: {test_r2:.4f}")
# Plot results
epochs=list(range(1, n_epochs+1))
plt.plot(epochs, train_losses, label='Train Loss')
plt.plot(epochs, val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()
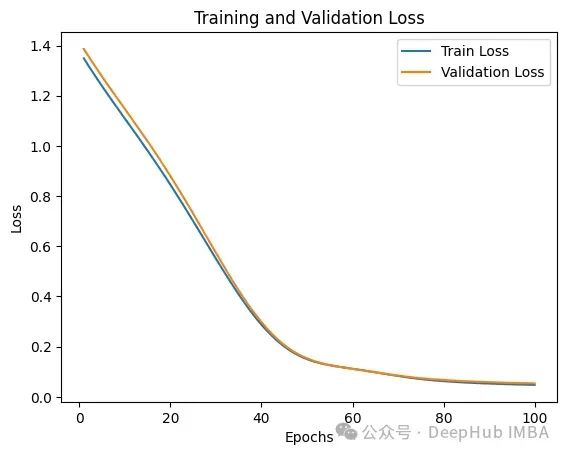
我们使用PyTorch定义了一个具有两个隐藏层的简单神经网络。模型使用K-Fold交叉验证来确保稳健的性能。TorchDynamo用于优化训练循环。在单独的测试集上对模型进行评估,并计算MSE和R²等指标。
最后得到的训练和验证损失如下
我们在代码中my_compiler打印了TorchDynamo相关的内容,我们来看看里面到底是什么:
my_compiler() called with FX graph:
opcode name target args kwargs
------------- ---------------------- ----------------------------------- ------------------------------------------------- --------
call_function train_losses_per_epoch <Wrapped function <original zeros>> (100,) {}
call_function val_losses_per_epoch <Wrapped function <original zeros>> (100,) {}
output output output ((train_losses_per_epoch, val_losses_per_epoch),) {}
my_compiler() called with FX graph:
opcode name target args kwargs
------------- ------------- ------------------------------------------------------- ---------------- --------
placeholder l_x_ L_x_ () {}
call_module l__self___fc1 L__self___fc1 (l_x_,) {}
call_function x <built-in method relu of type object at 0x792eaaa81760> (l__self___fc1,) {}
call_module l__self___fc2 L__self___fc2 (x,) {}
call_function x_1 <built-in method relu of type object at 0x792eaaa81760> (l__self___fc2,) {}
call_module x_2 L__self___fc3 (x_1,) {}
output output output ((x_2,),) {}
my_compiler() called with FX graph:
opcode name target args kwargs
------------- ----------------------- -------------------------------------------------------- ------------------------------------------ --------------------------------
placeholder grad L_self_param_groups_0_params_0_grad () {}
placeholder grad_1 L_self_param_groups_0_params_1_grad () {}
placeholder grad_2 L_self_param_groups_0_params_2_grad () {}
placeholder grad_3 L_self_param_groups_0_params_3_grad () {}
placeholder grad_4 L_self_param_groups_0_params_4_grad () {}
placeholder grad_5 L_self_param_groups_0_params_5_grad () {}
get_attr param self___param_groups_0__params___0 () {}
get_attr param_1 self___param_groups_0__params___1 () {}
get_attr param_2 self___param_groups_0__params___2 () {}
get_attr param_3 self___param_groups_0__params___3 () {}
get_attr param_4 self___param_groups_0__params___4 () {}
get_attr param_5 self___param_groups_0__params___5 () {}
get_attr exp_avg self___state_list_L__self___state_keys____0___exp_avg () {}
get_attr exp_avg_1 self___state_list_L__self___state_keys____1___exp_avg () {}
get_attr exp_avg_2 self___state_list_L__self___state_keys____2___exp_avg () {}
get_attr exp_avg_3 self___state_list_L__self___state_keys____3___exp_avg () {}
get_attr exp_avg_4 self___state_list_L__self___state_keys____4___exp_avg () {}
get_attr exp_avg_5 self___state_list_L__self___state_keys____5___exp_avg () {}
get_attr exp_avg_sq self___state_list_L__self___state_keys____0___exp_avg_sq () {}
get_attr exp_avg_sq_1 self___state_list_L__self___state_keys____1___exp_avg_sq () {}
get_attr exp_avg_sq_2 self___state_list_L__self___state_keys____2___exp_avg_sq () {}
get_attr exp_avg_sq_3 self___state_list_L__self___state_keys____3___exp_avg_sq () {}
get_attr exp_avg_sq_4 self___state_list_L__self___state_keys____4___exp_avg_sq () {}
get_attr exp_avg_sq_5 self___state_list_L__self___state_keys____5___exp_avg_sq () {}
get_attr step_t self___state_list_L__self___state_keys____0___step () {}
get_attr step_t_2 self___state_list_L__self___state_keys____1___step () {}
get_attr step_t_4 self___state_list_L__self___state_keys____2___step () {}
get_attr step_t_6 self___state_list_L__self___state_keys____3___step () {}
get_attr step_t_8 self___state_list_L__self___state_keys____4___step () {}
get_attr step_t_10 self___state_list_L__self___state_keys____5___step () {}
call_function step <built-in function iadd> (step_t, 1) {}
call_method lerp_ lerp_ (exp_avg, grad, 0.09999999999999998) {}
call_method mul_ mul_ (exp_avg_sq, 0.999) {}
call_method conj conj (grad,) {}
call_method addcmul_ addcmul_ (mul_, grad, conj) {'value': 0.0010000000000000009}
call_function pow_1 <built-in function pow> (0.9, step) {}
call_function bias_correction1 <built-in function sub> (1, pow_1) {}
call_function pow_2 <built-in function pow> (0.999, step) {}
call_function bias_correction2 <built-in function sub> (1, pow_2) {}
call_function step_size <built-in function truediv> (0.001, bias_correction1) {}
call_method step_size_neg neg (step_size,) {}
call_method bias_correction2_sqrt sqrt (bias_correction2,) {}
call_method sqrt_1 sqrt (exp_avg_sq,) {}
call_function mul <built-in function mul> (bias_correction2_sqrt, step_size_neg) {}
call_function truediv_1 <built-in function truediv> (sqrt_1, mul) {}
call_function truediv_2 <built-in function truediv> (1e-08, step_size_neg) {}
call_method denom add_ (truediv_1, truediv_2) {}
call_method addcdiv_ addcdiv_ (param, exp_avg, denom) {}
call_function step_1 <built-in function iadd> (step_t_2, 1) {}
call_method lerp__1 lerp_ (exp_avg_1, grad_1, 0.09999999999999998) {}
call_method mul__1 mul_ (exp_avg_sq_1, 0.999) {}
call_method conj_1 conj (grad_1,) {}
call_method addcmul__1 addcmul_ (mul__1, grad_1, conj_1) {'value': 0.0010000000000000009}
call_function pow_3 <built-in function pow> (0.9, step_1) {}
call_function bias_correction1_1 <built-in function sub> (1, pow_3) {}
call_function pow_4 <built-in function pow> (0.999, step_1) {}
call_function bias_correction2_1 <built-in function sub> (1, pow_4) {}
call_function step_size_1 <built-in function truediv> (0.001, bias_correction1_1) {}
call_method step_size_neg_1 neg (step_size_1,) {}
call_method bias_correction2_sqrt_1 sqrt (bias_correction2_1,) {}
call_method sqrt_3 sqrt (exp_avg_sq_1,) {}
call_function mul_1 <built-in function mul> (bias_correction2_sqrt_1, step_size_neg_1) {}
call_function truediv_4 <built-in function truediv> (sqrt_3, mul_1) {}
call_function truediv_5 <built-in function truediv> (1e-08, step_size_neg_1) {}
call_method denom_1 add_ (truediv_4, truediv_5) {}
call_method addcdiv__1 addcdiv_ (param_1, exp_avg_1, denom_1) {}
call_function step_2 <built-in function iadd> (step_t_4, 1) {}
call_method lerp__2 lerp_ (exp_avg_2, grad_2, 0.09999999999999998) {}
call_method mul__2 mul_ (exp_avg_sq_2, 0.999) {}
call_method conj_2 conj (grad_2,) {}
call_method addcmul__2 addcmul_ (mul__2, grad_2, conj_2) {'value': 0.0010000000000000009}
call_function pow_5 <built-in function pow> (0.9, step_2) {}
call_function bias_correction1_2 <built-in function sub> (1, pow_5) {}
call_function pow_6 <built-in function pow> (0.999, step_2) {}
call_function bias_correction2_2 <built-in function sub> (1, pow_6) {}
call_function step_size_2 <built-in function truediv> (0.001, bias_correction1_2) {}
call_method step_size_neg_2 neg (step_size_2,) {}
call_method bias_correction2_sqrt_2 sqrt (bias_correction2_2,) {}
call_method sqrt_5 sqrt (exp_avg_sq_2,) {}
call_function mul_2 <built-in function mul> (bias_correction2_sqrt_2, step_size_neg_2) {}
call_function truediv_7 <built-in function truediv> (sqrt_5, mul_2) {}
call_function truediv_8 <built-in function truediv> (1e-08, step_size_neg_2) {}
call_method denom_2 add_ (truediv_7, truediv_8) {}
call_method addcdiv__2 addcdiv_ (param_2, exp_avg_2, denom_2) {}
call_function step_3 <built-in function iadd> (step_t_6, 1) {}
call_method lerp__3 lerp_ (exp_avg_3, grad_3, 0.09999999999999998) {}
call_method mul__3 mul_ (exp_avg_sq_3, 0.999) {}
call_method conj_3 conj (grad_3,) {}
call_method addcmul__3 addcmul_ (mul__3, grad_3, conj_3) {'value': 0.0010000000000000009}
call_function pow_7 <built-in function pow> (0.9, step_3) {}
call_function bias_correction1_3 <built-in function sub> (1, pow_7) {}
call_function pow_8 <built-in function pow> (0.999, step_3) {}
call_function bias_correction2_3 <built-in function sub> (1, pow_8) {}
call_function step_size_3 <built-in function truediv> (0.001, bias_correction1_3) {}
call_method step_size_neg_3 neg (step_size_3,) {}
call_method bias_correction2_sqrt_3 sqrt (bias_correction2_3,) {}
call_method sqrt_7 sqrt (exp_avg_sq_3,) {}
call_function mul_3 <built-in function mul> (bias_correction2_sqrt_3, step_size_neg_3) {}
call_function truediv_10 <built-in function truediv> (sqrt_7, mul_3) {}
call_function truediv_11 <built-in function truediv> (1e-08, step_size_neg_3) {}
call_method denom_3 add_ (truediv_10, truediv_11) {}
call_method addcdiv__3 addcdiv_ (param_3, exp_avg_3, denom_3) {}
call_function step_4 <built-in function iadd> (step_t_8, 1) {}
call_method lerp__4 lerp_ (exp_avg_4, grad_4, 0.09999999999999998) {}
call_method mul__4 mul_ (exp_avg_sq_4, 0.999) {}
call_method conj_4 conj (grad_4,) {}
call_method addcmul__4 addcmul_ (mul__4, grad_4, conj_4) {'value': 0.0010000000000000009}
call_function pow_9 <built-in function pow> (0.9, step_4) {}
call_function bias_correction1_4 <built-in function sub> (1, pow_9) {}
call_function pow_10 <built-in function pow> (0.999, step_4) {}
call_function bias_correction2_4 <built-in function sub> (1, pow_10) {}
call_function step_size_4 <built-in function truediv> (0.001, bias_correction1_4) {}
call_method step_size_neg_4 neg (step_size_4,) {}
call_method bias_correction2_sqrt_4 sqrt (bias_correction2_4,) {}
call_method sqrt_9 sqrt (exp_avg_sq_4,) {}
call_function mul_4 <built-in function mul> (bias_correction2_sqrt_4, step_size_neg_4) {}
call_function truediv_13 <built-in function truediv> (sqrt_9, mul_4) {}
call_function truediv_14 <built-in function truediv> (1e-08, step_size_neg_4) {}
call_method denom_4 add_ (truediv_13, truediv_14) {}
call_method addcdiv__4 addcdiv_ (param_4, exp_avg_4, denom_4) {}
call_function step_5 <built-in function iadd> (step_t_10, 1) {}
call_method lerp__5 lerp_ (exp_avg_5, grad_5, 0.09999999999999998) {}
call_method mul__5 mul_ (exp_avg_sq_5, 0.999) {}
call_method conj_5 conj (grad_5,) {}
call_method addcmul__5 addcmul_ (mul__5, grad_5, conj_5) {'value': 0.0010000000000000009}
call_function pow_11 <built-in function pow> (0.9, step_5) {}
call_function bias_correction1_5 <built-in function sub> (1, pow_11) {}
call_function pow_12 <built-in function pow> (0.999, step_5) {}
call_function bias_correction2_5 <built-in function sub> (1, pow_12) {}
call_function step_size_5 <built-in function truediv> (0.001, bias_correction1_5) {}
call_method step_size_neg_5 neg (step_size_5,) {}
call_method bias_correction2_sqrt_5 sqrt (bias_correction2_5,) {}
call_method sqrt_11 sqrt (exp_avg_sq_5,) {}
call_function mul_5 <built-in function mul> (bias_correction2_sqrt_5, step_size_neg_5) {}
call_function truediv_16 <built-in function truediv> (sqrt_11, mul_5) {}
call_function truediv_17 <built-in function truediv> (1e-08, step_size_neg_5) {}
call_method denom_5 add_ (truediv_16, truediv_17) {}
call_method addcdiv__5 addcdiv_ (param_5, exp_avg_5, denom_5) {}
output output output ((),) {}
my_compiler() called with FX graph:
opcode name target args kwargs
------------- ------------- ------------------------------------------------------- ---------------- --------
placeholder s0 s0 () {}
placeholder l_x_ L_x_ () {}
call_module l__self___fc1 L__self___fc1 (l_x_,) {}
call_function x <built-in method relu of type object at 0x792eaaa81760> (l__self___fc1,) {}
call_module l__self___fc2 L__self___fc2 (x,) {}
call_function x_1 <built-in method relu of type object at 0x792eaaa81760> (l__self___fc2,) {}
call_module x_2 L__self___fc3 (x_1,) {}
output output output ((x_2,),) {}
FX图的输出表明了模型的结构和操作是如何组织的:
输入0和L_x_是表示输入数据的占位符。
模型通过全连接层
L__self___fc1
,
L__self___fc2
,
L__self___fc3
传递输入,这是神经网络的三层。
在前两层之后应用ReLU激活函数。
在第三层完全连接后产生最终输出。
总结
对于研究人员和工程师来说,训练大型和复杂的模型可能很耗时。TorchDynamo通过优化计算图和加速执行来减少这种训练时间,允许在更短的时间内进行更多的迭代和实验。在需要实时处理的应用程序中,如视频流或交互式人工智能系统,延迟是至关重要的。TorchDynamo在运行时优化和编译代码的能力确保了这些系统可以平稳运行并快速响应新数据。
TorchDynamo在支持多个后端和硬件架构方面的灵活性使其非常适合在各种环境中部署。无论是在高性能gpu或边缘设备上运行,TorchDynamo适应提供最佳性能。