
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习狗狗品种识别系统
设计思路
一、课题背景与意义
狗狗种类识别一直是计算机视觉领域的重要研究方向。传统的狗狗种类识别方法通常依赖于手工设计的特征和分类器,存在识别准确率低和对多样性狗狗品种的适应性差的问题。而基于深度学习的狗狗种类识别系统的出现,能够通过深度神经网络自动学习图像特征,极大地提高了识别准确性和泛化能力。
二、算法理论原理
2.1 卷积神经网络
卷积神经网络(CNN)是深度学习中最重要的结构之一。与传统的全连接神经网络相比,CNN利用卷积操作来学习数据中的高阶特征,特别适用于处理具有结构和空间相关性的数据,因此在图像中的物体识别方面表现出色。
CNN的核心思想是通过卷积层进行特征提取和特征映射,然后使用池化层进行空间降采样,最后通过全连接层进行分类或回归。卷积层通过卷积操作在局部感受野上提取特征,并共享权重以捕捉数据的局部结构。这种权重共享的方式大大减少了模型的参数量,使得CNN具有较少的模型复杂度。
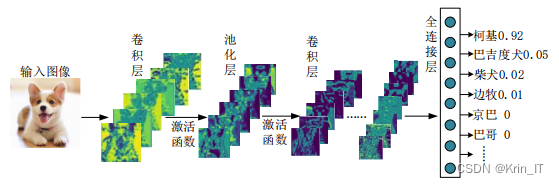
卷积层是CNN的核心组成部分,用于对输入图像进行特征提取。它通过将输入图像转化为矩阵,并与滤波器(也称为卷积核)进行点积操作,生成特征映射。卷积层将输入图像分解为像素值组成的矩阵,在矩阵上滑动卷积核。卷积核是一个小的矩阵,包含了一组权重参数。在每个位置,卷积核的值与其所在窗口中的像素值相乘,并将结果相加,得到一个单一的数值。这个数值表示卷积核在该位置上的响应或特征强度。
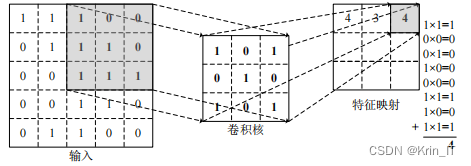
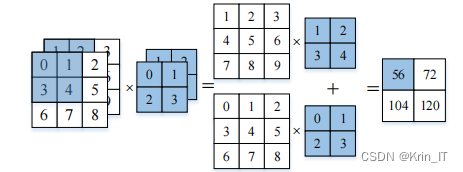
当输入的图片为彩色图像时,每个像素点包含RGB三个通道的信息。为了对彩色图像进行卷积操作,需要使用多维的卷积核。对于彩色图像的卷积操作,需要使用多维的卷积核,对输入图像的RGB三个通道分别进行卷积操作,并将各通道的卷积结果叠加起来得到最终的特征映射。这样可以保留并综合考虑图像在不同通道上的特征信息,提供更丰富和准确的特征表示。
2.2 YOLOv5模型
YOLOv5s在基于深度学习的狗狗分类系统中的优势主要体现在其快速的实时性能、准确的目标检测能力、多目标检测的支持以及轻量级的模型结构,使其成为高效、精确且适用于资源受限设备的解决方案。YOLOv5s采用了轻量级的网络结构,具有较快的推理速度,可以在实时或近实时的情况下对图像中的狗狗进行分类。这对于需要快速响应的应用场景非常重要。能够同时检测和分类图像中的多个狗狗实例,而不需要额外的后处理步骤。这使得它适用于具有多个目标的场景,例如一张图像中有多只狗狗。

多尺度的特征融合方式对于检测和分割网络的效果提升非常明显。浅层特征具有更丰富的像素点信息,如纹理、边缘和颜色等,虽然语义信息较弱,但有助于网络获取更多的细节信息。而深层特征则包含较强的语义信息,能够提供更抽象的特征表示。通过将不同层次的特征融合在一起,可以获得更丰富、更全面的特征信息,使网络能够同时捕捉到细节和语义,从而提高检测和分割任务的准确性和鲁棒性。这种多尺度特征融合的策略有助于充分利用网络的层次结构,提升对图像内容的理解和表示能力,进一步推动计算机视觉任务的发展和性能提升。
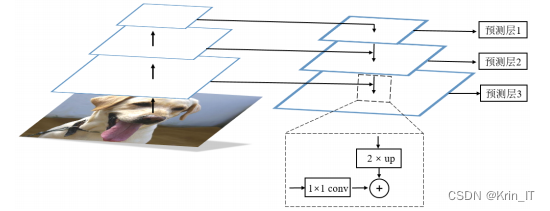
YOLO系列算法通过将图像划分为不同大小的网格来检测目标物体,其中每个网格的尺寸决定了检测到的物体的大小。通过这种不同尺寸的特征图结合,YOLO算法能够同时检测不同尺度的目标物体。在图中,黄色框表示真实目标框,蓝色框表示生成的三个预测框。这种多尺度的特征图设计使得YOLO算法能够在不同尺度的目标物体上具有较好的检测效果,并提高了算法的鲁棒性和适应性。

三、检测的实现
3.1 数据集
由于网络上缺乏合适的现有数据集,我决定亲自收集照片并创建一个全新的数据集,用于基于深度学习的犬类识别系统的研究。这个数据集包含了各种真实场景中的狗狗照片,涵盖了不同品种、姿态和环境条件下的狗狗图像。通过现场拍摄,我能够捕捉到真实且多样化的狗狗样本,为我的研究提供更准确、可靠的数据。这个自制的数据集将为犬类识别系统的研究和发展提供有力的支持,为改善狗狗识别的准确性和鲁棒性做出积极贡献。

数据扩充:
- 镜像翻转:通过
cv2.flip函数对图像进行水平翻转。 - 旋转:使用
cv2.getRotationMatrix2D函数获取旋转矩阵,然后使用cv2.warpAffine函数对图像进行旋转。 - 平移:通过定义平移矩阵,使用
cv2.warpAffine函数对图像进行平移。 - 缩放:使用
cv2.resize函数对图像进行缩放。
import cv2
import numpy as np
# 加载图像
image = cv2.imread('dog_image.jpg')
# 镜像翻转
flipped_image = cv2.flip(image, 1) # 参数1表示水平翻转
# 旋转
angle = 45
rows, cols = image.shape[:2]
rotation_matrix = cv2.getRotationMatrix2D((cols/2, rows/2), angle, 1)
rotated_image = cv2.warpAffine(image, rotation_matrix, (cols, rows))
# 平移
shift_x, shift_y = 50, 70
translation_matrix = np.float32([[1, 0, shift_x], [0, 1, shift_y]])
translated_image = cv2.warpAffine(image, translation_matrix, (cols, rows))
# 缩放
scale_percent = 150 # 增加50%的尺寸
new_width = int(image.shape[1] * scale_percent / 100)
new_height = int(image.shape[0] * scale_percent / 100)
resized_image = cv2.resize(image, (new_width, new_height))
# 显示扩充后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Flipped Image', flipped_image)
cv2.imshow('Rotated Image', rotated_image)
cv2.imshow('Translated Image', translated_image)
cv2.imshow('Resized Image', resized_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
数据标注(Data Annotation)是为数据集中的样本添加标签或注释,以指示样本的类别、位置或其他相关信息。在犬类识别系统中,数据标注可以包括对每个图像进行狗狗的类别标签(如品种)、边界框标注(用于定位狗狗的位置)等。数据标注通常需要人工进行,可以通过众包或专业的标注服务来完成。准确的数据标注对于训练深度学习模型非常重要,因为标注质量直接影响模型的性能和准确度。
# 加载图像
image = cv2.imread('dog_image.jpg')
# 定义边界框的坐标 (x_min, y_min, x_max, y_max)
bbox = (100, 200, 400, 500)
# 在图像上绘制边界框
cv2.rectangle(image, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
# 显示带有边界框的图像
cv2.imshow('Dog Image with Bounding Box', image)
cv2.waitKey(0)
将犬种数据集按照3:1:1的比例划分为训练集、验证集和测试集。
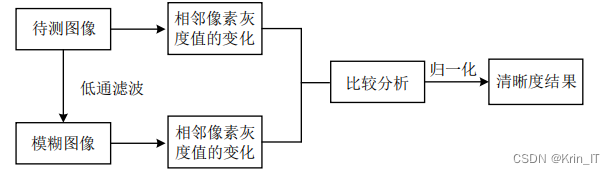
相关代码示例:
# 设置数据集路径
dataset_path = 'path/to/dataset'
# 设置划分后数据集保存路径
train_path = 'path/to/train'
val_path = 'path/to/validation'
test_path = 'path/to/test'
# 设置划分比例
train_ratio = 0.6
val_ratio = 0.2
test_ratio = 0.2
# 获取所有图像文件路径
image_files = []
for root, dirs, files in os.walk(dataset_path):
for file in files:
if file.endswith('.jpg'):
image_files.append(os.path.join(root, file))
# 打乱图像文件列表顺序
random.shuffle(image_files)
# 计算划分后的样本数量
total_images = len(image_files)
train_size = int(total_images * train_ratio)
val_size = int(total_images * val_ratio)
test_size = int(total_images * test_ratio)
# 创建保存划分后数据集的文件夹
os.makedirs(train_path, exist_ok=True)
os.makedirs(val_path, exist_ok=True)
os.makedirs(test_path, exist_ok=True)
# 复制图像文件到训练集文件夹
for i in range(train_size):
shutil.copy(image_files[i], train_path)
# 复制图像文件到验证集文件夹
for i in range(train_size, train_size + val_size):
shutil.copy(image_files[i], val_path)
# 复制图像文件到测试集文件夹
for i in range(train_size + val_size, train_size + val_size + test_size):
shutil.copy(image_files[i], test_path)
print("数据集划分完成!")
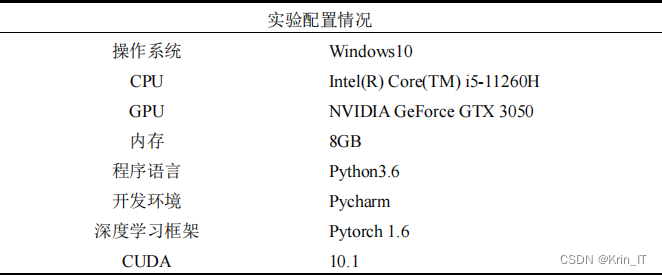
3.2 实验环境搭建
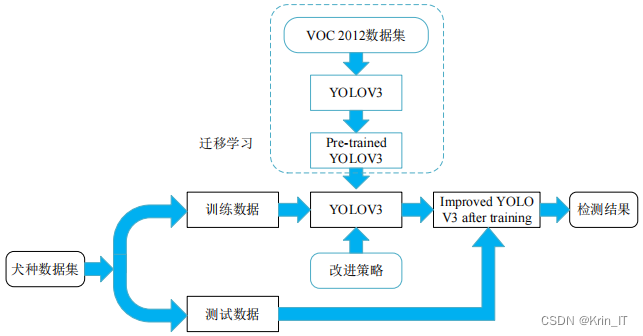
3.3 实验及结果分析
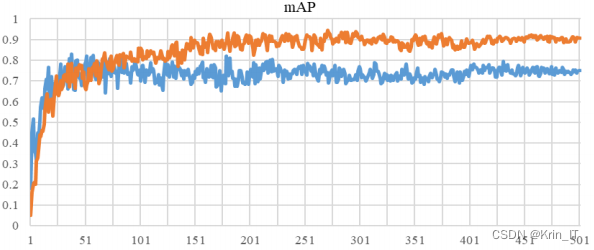
采用了四个评价指标来评估检测方法的性能,包括精确率(Precision)、召回率(Recall)、平均精度(mAP)和每秒处理帧数(FPS)。为了提高网络模型的学习效率并节省模型训练时间,本文采用了迁移学习的策略。提出的改进策略被添加到初始化参数之后的YOLOv5s模型上。最后,使用自己构建的数据集对模型进行训练,以获得性能更优秀的网络模型。通过这个迁移学习的策略,能够充分利用已有模型的知识,从而加速模型的收敛并提高检测性能。
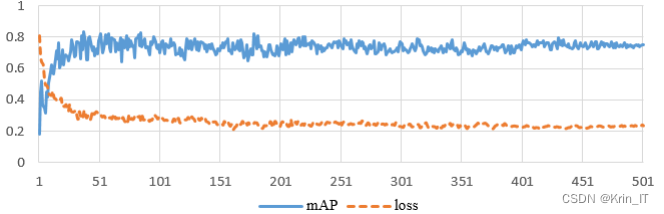
在使用的数据集上,当迭代次数达到500次时,观察到模型的震荡幅度减小,mAP和损失函数的曲线趋于平稳,表明网络已经达到了收敛状态。当批量大小(batch size)选择为8时,模型的准确率达到最高点,网络达到最优状态。因此,使用批量大小为8的配置能够获得最佳的性能表现。
改进后的模型在犬种图像的检测质量和检测完整性方面都有明显提高。mAP的提高达到了15%,表明模型的整体检测效果得到了显著改善,表现出更好的性能。
相关代码示例:
import torch
import torchvision.transforms as transforms
from PIL import Image
from pathlib import Path
# 加载YOLO模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 设置图像转换
transform = transforms.Compose([
transforms.Resize((640, 640)), # 调整图像大小
transforms.ToTensor() # 转换为张量
])
# 设置类别标签
class_labels = ['dog']
# 加载图像
image_path = 'path/to/image.jpg'
image = Image.open(image_path).convert('RGB')
# 进行图像转换和模型推理
input_image = transform(image).unsqueeze(0)
results = model(input_image)
# 获取预测结果
predictions = results.pandas().xyxy[0]
# 输出预测结果
for _, prediction in predictions.iterrows():
label = class_labels[int(prediction['class'])]
confidence = prediction['confidence']
bbox = prediction[['xmin', 'ymin', 'xmax', 'ymax']].values.tolist()
print(f'类别: {label}, 置信度: {confidence}, 边界框: {bbox}')
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
本文转载自: https://blog.csdn.net/2301_79555157/article/details/135001316
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Krin_IT 所有, 如有侵权,请联系我们删除。