导数与微分总复习——“高等数学”
导数与微分噢
Wise-IoU 作者导读:基于动态非单调聚焦机制的边界框损失
目标检测作为计算机视觉的核心问题,其检测性能依赖于损失函数的设计。边界框损失函数作为目标检测损失函数的重要组成部分,其良好的定义将为目标检测模型带来显著的性能提升。近年来的研究大多假设训练数据中的示例有较高的质量,致力于强化边界框损失的拟合能力。但我们注意到目标检测训练集中含有低质量示例,如果一味地
YOLO-V4经典物体检测算法介绍
YOLO-V4经典物体检测算法介绍
Tensorflow-gpu安装教程(详细)!!!
在安装过程中呢,最重要的莫过于tensorflow,python及其依赖项的版本对应了,如果安装了版本不对应的cuda或者cudnn,可能会导致一系列的问题而最终不能正常地调用设备的GPU进行工作了。所以我们在安装的时候必须时刻注意它们之间的版本对应关系,如果说在安装过程中出现了与之前安装的tens
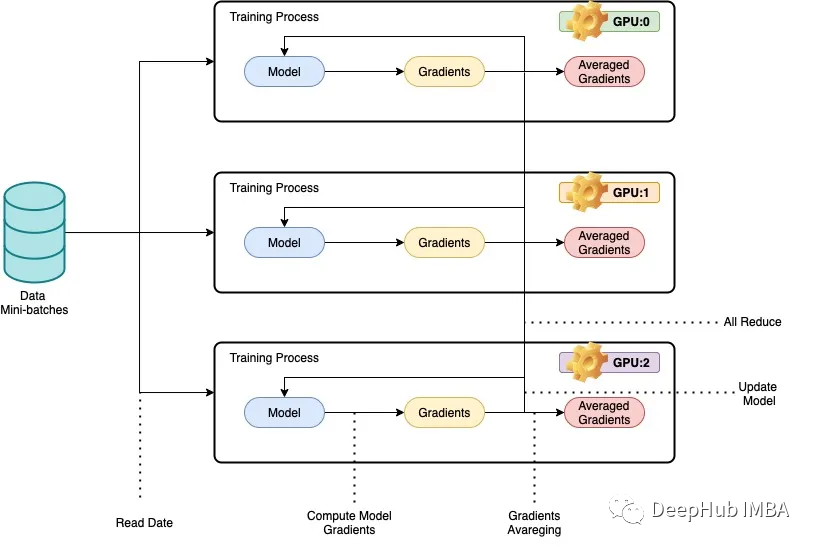
PyTorch 并行训练 DistributedDataParallel完整代码示例
使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。在本文中我们将演示使用 PyTorch 的数据并行性和模型并行性。
关于 ChatGPT 必看的 10 篇论文
2022年11月,OpenAI推出人工智能聊天原型ChatGPT,再次赚足眼球,为AI界引发了类似AIGC让艺术家失业的大讨论。ChatGPT 是一种专注于对话生成的语言模型。它能够根据用户的文本输入,产生相应的智能回答。这个回答可以是简短的词语,也可以是长篇大论。其中 GPT 是 Generati
Python CNN卷积神经网络实例讲解,CNN实战,CNN代码实例,超实用
Python CNN卷积神经网络实例讲解,CNN实战,CNN代码实例,套用简单
Transformer与看图说话
Transformer与看图说话
YOLO_V8训练自己的数据集
YOLO_V8训练自己的数据集
计算机视觉框架OpenMMLab开源学习(六):语义分割基础
本系列第六篇文章主要介绍语义分割知识,了解计算机视觉框架OpenMMLab的MMSegmentation工具基本原理及使用,为后续语义分割实战做铺垫。
YOLOv5-7.0实例分割训练自己的数据,切分mask图并摆正
1、YOLOv5-7.0实例分割训练自己的数据2、取出分割的mask图并旋转摆正
23年 yolov5车辆识别+行人识别+车牌识别+车速检测代码(python)
行人识别yolov5和v7对比yolo车距yolo车距1。
YOLOv8训练自己的数据集
YOLOv8发布,撸起袖子加油卷
改进YOLOv5/YOLOv7——魔改YOLOv5/YOLOv7提升检测精度(涨点必备)
🎄🎄魔改YOLOv5/YOLOv7目标检测算法——各位小伙伴可根据自身研究方向及专业领域自主搭配各类创新新颖且行之有效的网络结构,以此实现论文实验高效涨点。主要包括主干网络改进、轻量化网络、注意力机制、检测头部改进、空间金字塔池化、损失函数及NMS改进、视觉顶会创新点改进以及算法训练相关项目等等
【深度学习时间序列预测案例】零基础入门经典深度学习时间序列预测项目实战(附代码+数据集+原理介绍)
本专栏整理了《深度学习时间序列预测案例》,内包含了各种不同的基于深度学习模型的时间序列预测方法,例如LSTM、GRU、CNN(一维卷积、二维卷积)、LSTM-CNN、BiLSTM、Self-Attention、LSTM-Attention、Transformer等经典模型,包含项目原理以及源码,每一
YOLOv5/v7 更换骨干网络之 MobileNetV3
YOLOv5 框架引入 Google 轻量化网络 MobileNet V3
AAAI | 达摩院经典自适应多域联合优化训练框架及其应用
本文简要介绍一下我们在AAAI上的论文"Robust Optimization over Multiple Domains"。在这篇文章中,我们提出了一种新的优化方法,通过自适应的多域联合优化框架使得模型在多个域上都能取得较好的识别效果。
23年 车辆检测+车距检测+行人检测+车辆识别+车距预测(附yolo v5最新版源码)
运用yolov5进行车距检测,车辆识别,行人识别,车牌检测!
扩散模型diffusion model用于图像恢复任务详细原理 (去雨,去雾等皆可),附实现代码
扩散模型原理公式推导,以及如何将扩散模型应用于图像恢复任务,包括可运行实现代码
YOLOv7保姆级教程(个人踩坑无数)----训练自己的数据集
从零开始,保姆级yolov7教程助你脱离新手村。



