YOLOV8-gradcam 热力图可视化 即插即用 不需要对源码做任何修改!
yolov8-gradcam热力图可视化,即插即用,不需要对源码做任何修改。代码仓库还有yolov5和yolov7的热力图可视化代码,也是不需要对源码做任何修改喔!
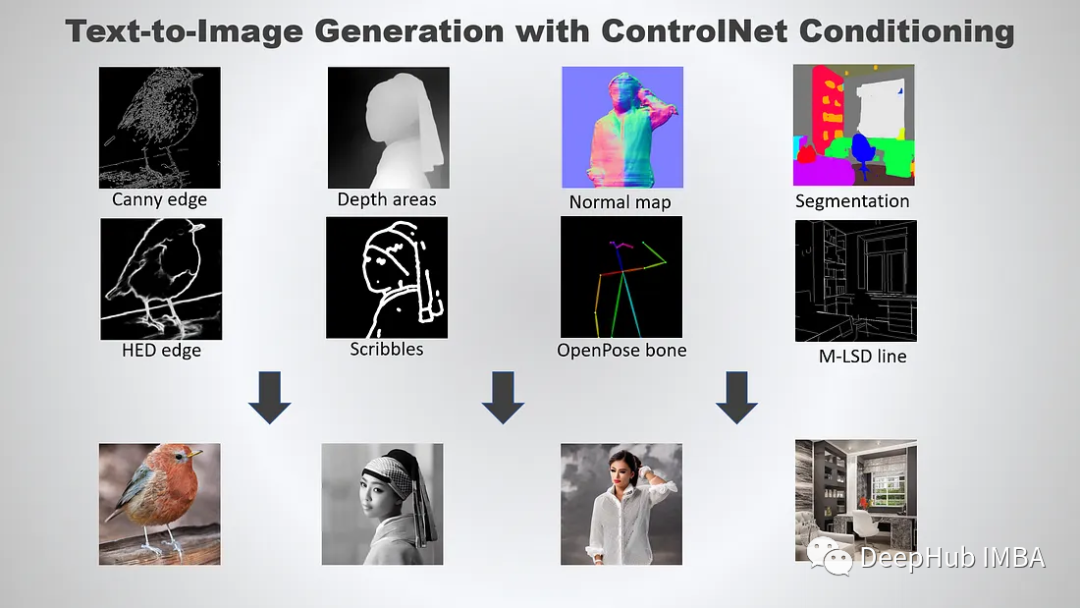
使用ControlNet 控制 Stable Diffusion
本文将要介绍整合HuggingFace的diffusers 包和ControlNet调节生成文本到图像,可以更好地控制文本到图像的生成
SwinIR实战:详细记录SwinIR的训练过程
SwinIR实战:详细记录SwinIR的训练过程。论文地址:https://arxiv.org/pdf/2108.10257.pdf预训练模型下载:https://github.com/JingyunLiang/SwinIR/releases训练代码下载:https://github.com/csz
pytorch模型保存与加载总结
pytorch模型保存与加载方式、打包保存tar、多卡训练遇到的问题、torch.jit、加载预训练模型、保存模型再加载精度损失
LSTM实现时间序列预测(PyTorch版)
为了训练数据,首先定义LSTM模型,然后再定义对应的损失函数,由于我们这里是风速预测,显然是个回归问题,所以采用回归问题常用的MESLoss(),如果可以的话,可以自定义损失函数,针对自己的项目需求定义对应的损失函数。对于优化器来讲,使用的也是目前常用的Adam优化器,对于新手来讲也可以多多尝试其它
GhostNet v2(NeurIPS 2022 Spotlight)原理与代码解析
首先回顾下GhostNet,对于输入 \(X\in \mathbb{R}^{H\times W\times C}\),Ghost module将一个标准的卷积替换成两步。首先用一个1x1卷积生成intrinsic feature。
史上最全学习率调整策略lr_scheduler
学习率是深度学习训练中至关重要的参数,很多时候一个合适的学习率才能发挥出模型的较大潜力。所以学习率调整策略同样至关重要,这篇博客介绍一下Pytorch中常见的学习率调整方法。
NoveAI本地环境搭建、AI作画
AI作画,总结下自己的操作过程
机器学习中的数学原理——模型评估与交叉验证
机器学习中的模型评估与交叉验证!这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下白话机器学习中的数学——模型评估与交叉验证》!
结合基于规则和机器学习的方法构建强大的混合系统
在本文中,将介绍如何将手动规则和ML结合使得我们的方案变得更好。
DCGAN理论讲解及代码实现
DCGAN也叫深度卷积生成对抗网络,DCGAN就是将CNN与GAN结合在一起,生成模型和判别模型都运用了深度卷积神经网络的生成对抗网络。DCGAN将GAN与CNN相结合,奠定了之后几乎所有GAN的基本网络架构。DCGAN极大地提升了原始GAN训练的稳定性以及生成结果的质量...
【pytorch】有关nn.EMBEDDING的简单介绍
假设有一本字典,就一共只有10单词,每个单词有5个字母组成。每一页上只写一个单词,所以这10页纸上分别写了这10个单词。内如如下,我们假定这本字典叫, 这里的10和5即上面介绍的含义,10个单词,每个单词5个字母;现在我要查看第2页和第3页(从0开始),那么我会得到 [s,m,a,l,l], [w,
AI生成图像竟如此真实了?Stable Diffusion Model本地部署教程
Stable Diffusion Model 是一个基于扩散模型的图像生成模型。stable-diffusion-webui 是 AUTOMATIC1111 大佬在 Github 上开源的一个专用于图片生成模型的 WebUI,可以在本地部署,支持导入模型和自己训练。重要的是,该项目的部署方式非常简单
Pytorch文档解读|torch.nn.MultiheadAttention的使用和参数解析
整体称为一个单注意力头,因为运算结束后只对每个输入产生一个输出结果,一般在网络中,输出可以被称为网络提取的特征,那我们肯定希望提取多种特征,[ 比如说我输入是一个修狗狗图片的向量序列,我肯定希望网络提取到特征有形状、颜色、纹理等等,所以单次注意肯定是不够的 ]因为是拼接而成的,所以每个单注意力头其实
rk3588使用npu进行模型转换和推理,加速AI应用落地
本来想使用tensorrt进行加速推理,但是前提需要cuda,rk的板子上都是Arm的手机gpu,没有Nvidia的cuda,所以这条路行不通。使用该NPU需要下载RKNN SDK,RKNN SDK 为带有 NPU 的RK3588S/RK3588 芯片平台提供编程接口,能够帮助用户部署使用 RKNN
GPT系列学习笔记:GPT、GPT2、GPT3
GPT、GPT2、GPT3的区别和联系。
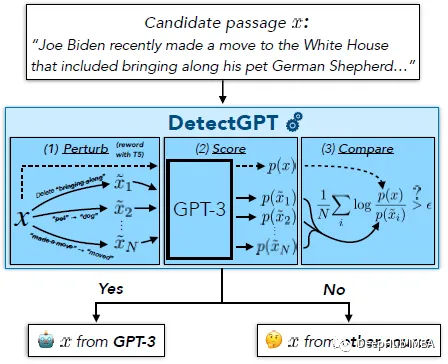
DetectGPT:使用概率曲率的零样本机器生成文本检测
DetectGPT的目的是确定一段文本是否由特定的llm生成,例如GPT-3。
自注意力(Self-Attention)与Multi-Head Attention机制详解
self-attention,multi-head attention原理详解
手把手YOLOv5输出热力图
YOLO 手把手教你输出热力图
yolov5s模型剪枝详细过程(v6.0)
基于yolov5s(v6.0)的模型剪枝实战分享,参考github教程带链接带源码。



