
文章目录
一、KITTI数据集简介
1.1 介绍
- 文章链接 《Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite (2012)》
- 概述 KITTI数据集是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。 KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。 3D目标检测数据集由7481个训练图像和7518个测试图像以及相应的点云数据组成,包括总共80256个标记对象。
- 数据采集平台
Kitti的数据采集车,顶上是一个64线的velodyne激光雷达,前面有四个摄像头分别是cam0~3,其中0和1是灰度相机,2和3是rgb相机。激光雷达的坐标系遵循右手定则,而相机坐标系遵循左手定则,如图所示。
为了生成双目立体图像,相同类型的摄像头相距54cm安装。由于彩色摄像机的分辨率和对比度不够好,所以还使用了两个立体灰度摄像机,它和彩色摄像机相距6cm安装。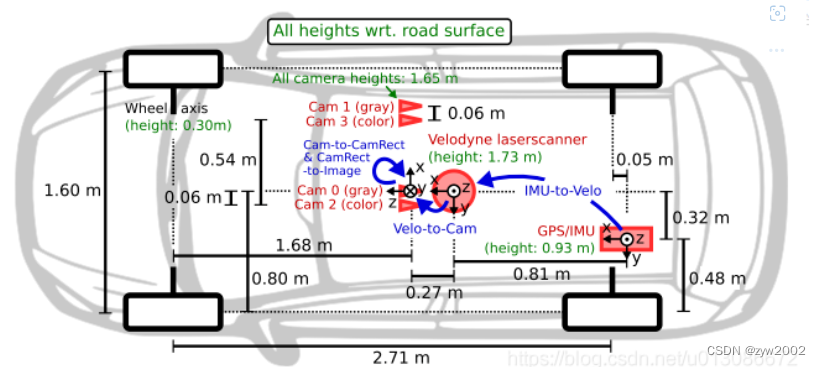
四个相机经过了严格的位置矫正,保证yz同值,x同轴,如果想进行lidar与camera的坐标系转换,默认以cam0为基准,即如果是cam0转到velodyne,就直接转,如果是cam其他转velodyne,则先要转到cam0,再转到velodyne,相机和激光的坐标转换后续会详细说明。
具体的传感器参数如下:
2 × PointGray Flea2 grayscale cameras (FL2-14S3M-C), 1.4 Megapixels, 1/2” Sony ICX267 CCD, global shutter
2 × PointGray Flea2 color cameras (FL2-14S3C-C), 1.4 Megapixels, 1/2” Sony ICX267 CCD, global shutter
4 × Edmund Optics lenses, 4mm, opening angle ∼ 90◦, vertical opening angle of region of interest (ROI) ∼ 35◦
1 × Velodyne HDL-64E rotating 3D laser scanner, 10 Hz, 64 beams, 0.09 degree angular resolution, 2 cm distance accuracy, collecting ∼ 1.3 million points/second, field of view: 360◦ horizontal, 26.8◦ vertical, range: 120 m
1 × OXTS RT3003 inertial and GPS navigation system, 6 axis, 100 Hz, L1/L2 RTK, resolution: 0.02m / 0.1◦
- 坐标系
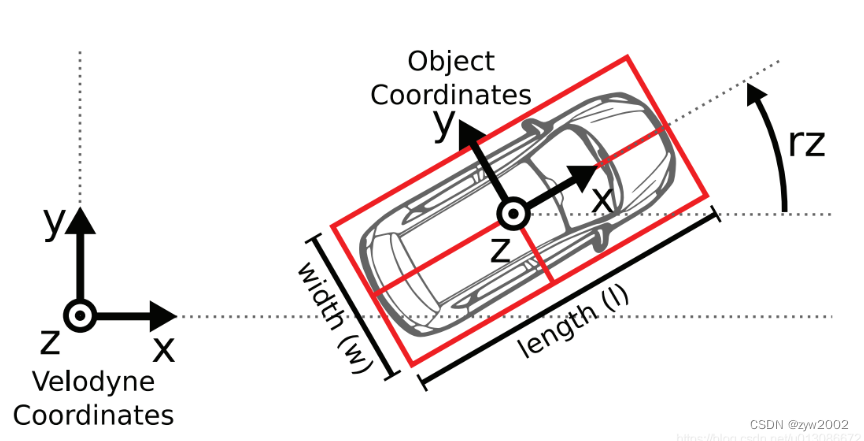
为了方便传感器数据标定,规定坐标系方向如下 :
- camera: x = right, y = down, z = forward
- velodyne: x = forward, y = left, z = up
- GPS/IMU: x = forward, y = left, z = up
1.2 下载
- 数据集官网 数据集官网下载地址
- 百度网盘下载链接 链接:https://pan.baidu.com/s/1-4WchJlcZ2guwcfbHqrdFw 提取码:grys建议使用百度网盘的下载链接(因为文件特别大,而且官网的下载速度很慢。)
进入官网,下图红色框标记的为我们需要的数据:
- 彩色图像数据(12GB)
- 点云数据(29GB)
- 相机矫正数据(16MB)
- 标签数据(5MB)。
其中彩色图像数据、点云数据、相机矫正数据均包含training(7481)和testing(7518)两个部分,标签数据只有training数据。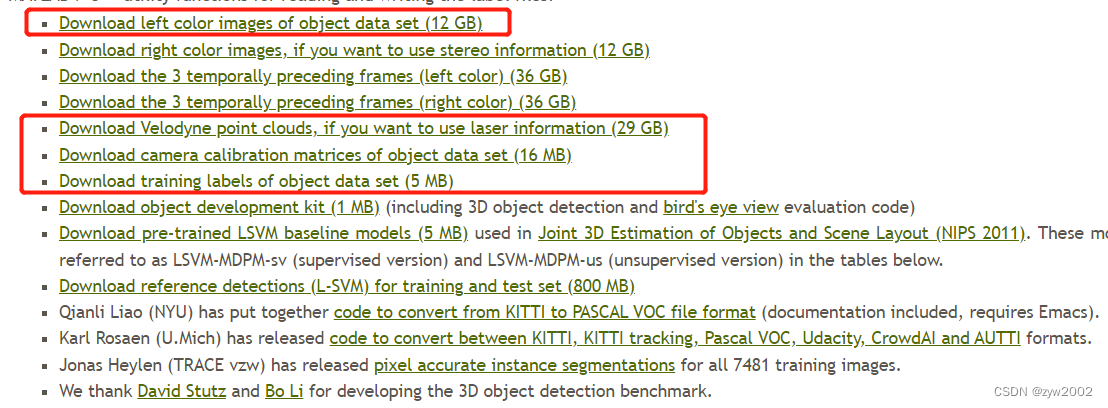
二、数据解析
2.0 数据集结构
按照官方给出的OpenPCDet中的KITTI数据集的组织方法,排布数据集
data
│── kitti
│ │── ImageSets
│ │── testing
│ │ ├── calib & image_2 & velodyne
│ │── training
│ │ ├── calib & image_2 & label_2 & planes & velodyne
image_2即2号彩色相机所拍摄的图片(.png);calib对应每一帧的外参(.txt);label_2是每帧的标注信息(.txt);velodyne是Velodyne64所得的点云文件(.bin)
2.1 ImageSets
数据集列表信息,一般包括如下3部分:
- train.txt:训练集 列表信息
- test.txt:测试集 列表信息
- val.txt:验证集 列表信息
2.2 Testing & Training
2.2.1 calib
calib文件是相机、雷达、惯导等传感器的矫正数据。以“000001.txt”文件为例,内容如下:
P0:7.215377000000e+020.000000000000e+006.095593000000e+020.000000000000e+000.000000000000e+007.215377000000e+021.728540000000e+020.000000000000e+000.000000000000e+000.000000000000e+001.000000000000e+000.000000000000e+00
P1:7.215377000000e+020.000000000000e+006.095593000000e+02-3.875744000000e+020.000000000000e+007.215377000000e+021.728540000000e+020.000000000000e+000.000000000000e+000.000000000000e+001.000000000000e+000.000000000000e+00
P2:7.215377000000e+020.000000000000e+006.095593000000e+024.485728000000e+010.000000000000e+007.215377000000e+021.728540000000e+022.163791000000e-010.000000000000e+000.000000000000e+001.000000000000e+002.745884000000e-03
P3:7.215377000000e+020.000000000000e+006.095593000000e+02-3.395242000000e+020.000000000000e+007.215377000000e+021.728540000000e+022.199936000000e+000.000000000000e+000.000000000000e+001.000000000000e+002.729905000000e-03
R0_rect:9.999239000000e-019.837760000000e-03-7.445048000000e-03-9.869795000000e-039.999421000000e-01-4.278459000000e-037.402527000000e-034.351614000000e-039.999631000000e-01
Tr_velo_to_cam:7.533745000000e-03-9.999714000000e-01-6.166020000000e-04-4.069766000000e-031.480249000000e-027.280733000000e-04-9.998902000000e-01-7.631618000000e-029.998621000000e-017.523790000000e-031.480755000000e-02-2.717806000000e-01
Tr_imu_to_velo:9.999976000000e-017.553071000000e-04-2.035826000000e-03-8.086759000000e-01-7.854027000000e-049.998898000000e-01-1.482298000000e-023.195559000000e-012.024406000000e-031.482454000000e-029.998881000000e-01-7.997231000000e-01
P0~P3P r e c t ( i ) P_{rect}^{(i)} Prect(i) :矫正后的相机投影矩阵 R 3 ∗ 4 R^{3*4} R3∗4 0、1、2、3 代表相机的编号,0表示左边灰度相机,1右边灰度相机,2左边彩色相机,3右边彩色相机。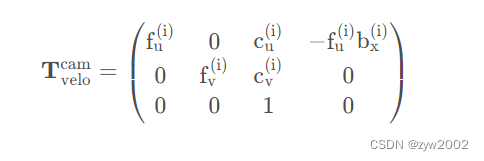 其中 b x ( i ) b_x^{(i)} bx(i)表示相对于参考摄像机0的基准值(以米为单位)
其中 b x ( i ) b_x^{(i)} bx(i)表示相对于参考摄像机0的基准值(以米为单位)R0_rectR r e c t ( i ) R_{rect}^{(i)} Rrect(i) :矫正后的相机旋转矩阵 R 3 ∗ 3 R^{3*3} R3∗3 在实际计算时,需要将该3x3的矩阵扩展为4x4的矩阵,方法为在第四行和第四列添加全为0的向量,并且将(4, 4)的索引值设为1。Tr_velo_to_cam( T v e l o c a m ) (T_{velo}^{cam}) (Tvelocam) :从雷达到相机0的旋转平移矩阵 ( R 3 ∗ 4 R^{3*4} R3∗4) 在实际计算时,需要将该3x4的矩阵扩展为4x4的矩阵,方法为增加第四行向量[0,0,0,1]。这个矩阵其实包括了两个部分,其一是3x3的旋转矩阵,其二是1x3的平移向量。
Tr_imu_to_velo( T i m u v e l o ) (T_{imu}^{velo}) (Timuvelo) : 从惯导或GPS装置到相机的旋转平移矩阵 ( R 3 ∗ 4 R^{3*4} R3∗4) 如果要将激光雷达坐标系中的点x投影到左侧的彩色图像(P2)y中,可使用如下公式: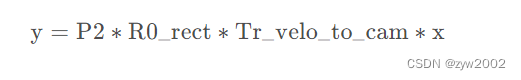 若想将激光雷达坐标系中的点x投射到其他摄像头,只需替换P2矩阵即可(例如右边的彩色相机P3)。
若想将激光雷达坐标系中的点x投射到其他摄像头,只需替换P2矩阵即可(例如右边的彩色相机P3)。
1、将 Velodyne 坐标中的点 x 投影到左侧的彩色图像中 y,使用公式 y = P2 * R0_rect * Tr_velo_to_cam * x
2、将 Velodyne 坐标中的点 x 投影到右侧的彩色图像中 y,使用公式 y = P3 * R0_rect * Tr_velo_to_cam * x
3、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,使用公式 R0_rect * Tr_velo_to_cam * x
4、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,再投影到编号为 2 的相机(左彩色相机)的照片上,使用公式 P2 * R0_rect * Tr_velo_to_cam * x
2.2.2 image_2
image文件以8位PNG格式存储,图集如下:
2.2.3 label_2
label文件是KITTI中object的标签和评估数据,以“000001.txt”文件为例,包含样式如下:
Truck 0.000-1.57599.41156.40629.75189.252.852.6312.340.471.4969.44-1.56
Car 0.0001.85387.63181.54423.81203.121.671.873.69-16.532.3958.491.57
Cyclist 0.003-1.65676.60163.95688.98193.931.860.602.024.591.3245.84-1.55
DontCare -1-1-10503.89169.71590.61190.13-1-1-1-1000-1000-1000-10
DontCare -1-1-10511.35174.96527.81187.45-1-1-1-1000-1000-1000-10
DontCare -1-1-10532.37176.35542.68185.27-1-1-1-1000-1000-1000-10
DontCare -1-1-10559.62175.83575.40183.15-1-1-1-1000-1000-1000-10
每一行代表一个object,每一行都有16列分别表示不同的含义,具体如下:
- 第1列(字符串):代表物体类别(type) 总共有9类,分别是:Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc、DontCare。 其中DontCare标签表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算precision),将本来是目标物体但是因为某些原因而没有标注的区域统计为假阳性(false positives),评估脚本会自动忽略DontCare区域的预测结果。
- 第2列(浮点数):代表物体是否被截断(truncated) 数值在0(非截断)到1(截断)之间浮动,数字表示指离开图像边界对象的程度。
- 第3列(整数):代表物体是否被遮挡(occluded) 整数0、1、2、3分别表示被遮挡的程度。
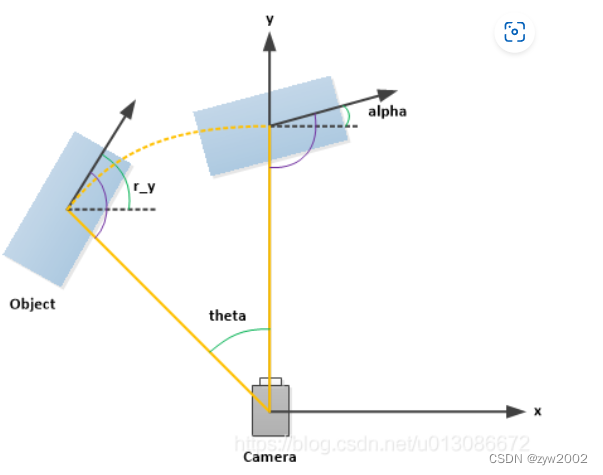
- 第4列(弧度数):物体的观察角度(alpha) 取值范围为:-pi ~ pi(单位:rad),它表示在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,此时物体方向与相机x轴的夹角(如下图所示,y轴垂直与屏幕)
- 第5~8列(浮点数):物体的2D边界框大小(bbox) 四个数分别是xmin、ymin、xmax、ymax(单位:pixel),表示2维边界框的左上角和右下角的坐标。
- 第9~11列(浮点数):3D物体的尺寸(dimensions) 分别是高、宽、长(单位:米)
- 第12-14列(浮点数):3D物体的位置(location) 分别是x、y、z(单位:米),特别注意的是,这里的xyz是在相机坐标系下3D物体的中心点位置。
- 第15列(弧度数):3D物体的空间方向(rotation_y) 取值范围为:-pi ~ pi(单位:rad),它表示,在照相机坐标系下,物体的全局方向角(物体前进方向与相机坐标系x轴的夹角),如下图所示。
- 第16列(浮点数):检测的置信度(score)
2.2.4 planes
#Plane
Width 4
Height 1-1.851372e-02-9.998285e-01-5.362310e-041.678761e+00
2.2.5 velodyne
velodyne文件是激光雷达的测量数据(绕其垂直轴(逆时针)连续旋转),以“000001.bin”文件为例,内容如下:
8D 97924139 B4 483D 5839543F0000000083 C0 92418716 D9 3D 5839543F000000002D 324D 42 AE 47013F FE D4 F8 3F0000000037899241 D3 4D 623E 5839543F00000000
E5 D0 92411283803E E1 7A 543F EC 51 B8 3D
7B 1470412B 87963E 508D 373F CD CC 4C 3E
96436F417B 14 AE 3E 3D 0A 373F E1 7A 143F2F DD 72415E BA C9 3E 8716393F00000000
FA 7E 92415E BA 093F5839543F0000000066669241 EC 51183F CF F7 533F00000000
A4 70924177 BE 1F3F CF F7 533F00000000
A4 7092418D 972E 3F5839543F00000000...
点云数据以浮点二进制文件格式存储,每行包含8个数据,每个数据由四位十六进制数表示(浮点数),每个数据通过空格隔开。一个点云数据由四个浮点数数据构成,分别表示点云的x、y、z、r(强度 or 反射值),点云的存储方式如下表所示: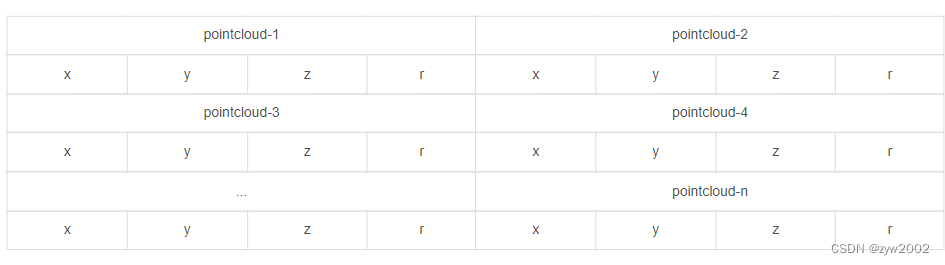
三、数据集的下载和组织
- 百度网盘下载链接 链接:https://pan.baidu.com/s/1-4WchJlcZ2guwcfbHqrdFw 提取码:grys
从百度网盘下载如下框出的文件。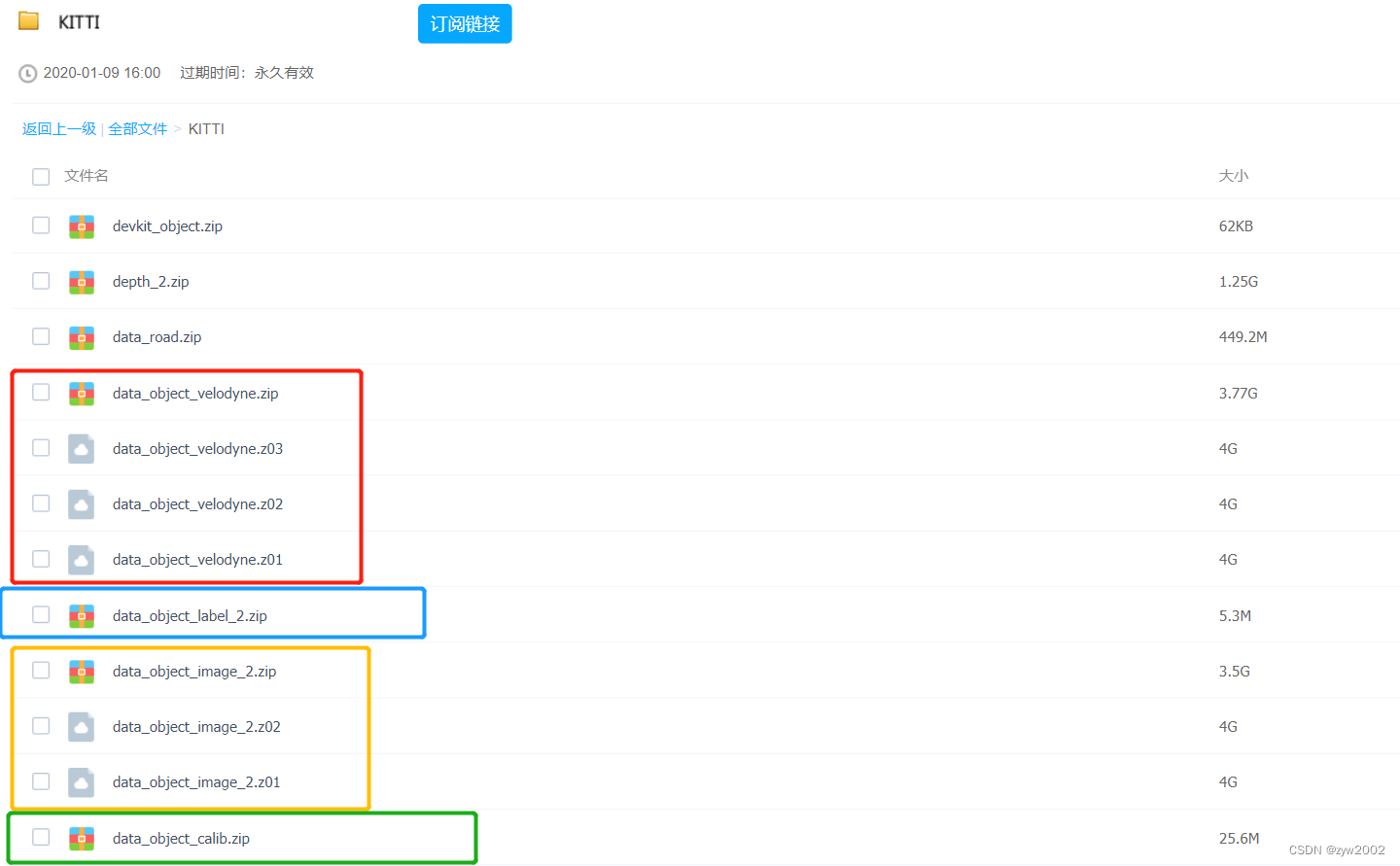
其中
xxx.zip和
xxx.z01、
xxx.z02、
xxx.z03是分包文件,必须全部下载后才能够解压。
然后通过xftp把下载的压缩包全部上传到云服务器上。
分包文件的解压方法,以
data_object_image_2.zip
为例子。
# 先将压缩包合并zip -s 0 data_object_image_2.zip --out image_02.zip
# 再次解压unzip image_02.zip
解压之后的文件结构如下所示。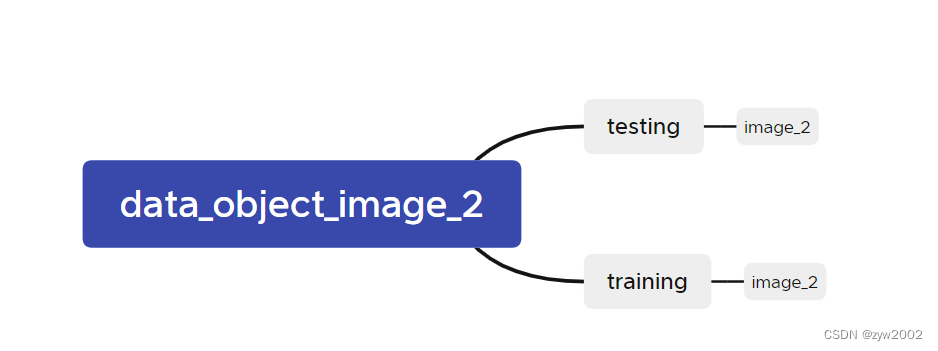
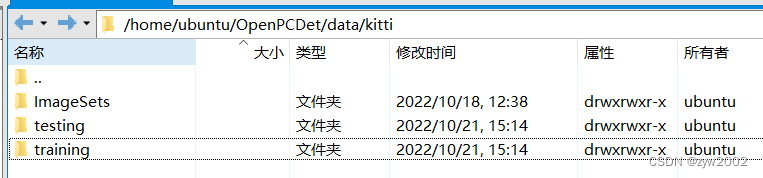
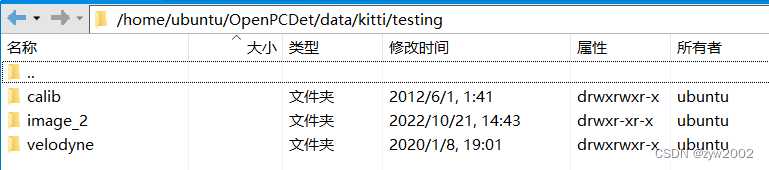
如下所示,在kitti文件夹下新建
testing
和
training
目录。然后把上一步解压后得到的
data_object_image2/testing/image_2
文件放入到
data/kitti/testing
文件夹下;把上一步解压后得到的
data_object_image2/training/image_2
文件放入到
data/kitti/training
文件夹下。
最终的组织架构如下图所示:
参考
参考博客:
【1】https://blog.csdn.net/i6101206007/article/details/11225682
【2】https://blog.csdn.net/u013086672/article/details/103913361
版权归原作者 zyw2002 所有, 如有侵权,请联系我们删除。