
目录
本教程是通过示例代码说明DCGAN网络如何设置网络、优化器、如何计算损失函数以及如何初始化模型权重。在本教程中,使用的动漫头像数据集共有70,171张动漫头像图片,图片大小均为96*96
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、原理说明
1.GAN基础原理
生成式对抗网络(Generative Adversarial Networks,GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
最初,GAN由Ian J. Goodfellow于2014年发明,并在论文Generative Adversarial Nets中首次进行了描述,GAN由两个不同的模型组成——生成器和判别器:
生成器的任务是生成看起来像训练图像的“假”图像;
判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。
2.DCGAN原理
DCGAN(深度卷积对抗生成网络,Deep Convolutional Generative Adversarial Networks)是GAN的直接扩展。不同之处在于,DCGAN会分别在判别器和生成器中使用卷积和转置卷积层。
它最早由Radford等人在论文Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks中进行描述。判别器由分层的卷积层、BatchNorm层和LeakyReLU激活层组成。输入是3x64x64的图像,输出是该图像为真图像的概率。生成器则是由转置卷积层、BatchNorm层和ReLU激活层组成。输入是标准正态分布中提取出的隐向量z,输出是3x64x64的RGB图像。
本教程将使用动漫头像数据集来训练一个生成式对抗网络,接着使用该网络生成动漫头像图片。
二、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,可以在昇思教程中进入ModelArts官网
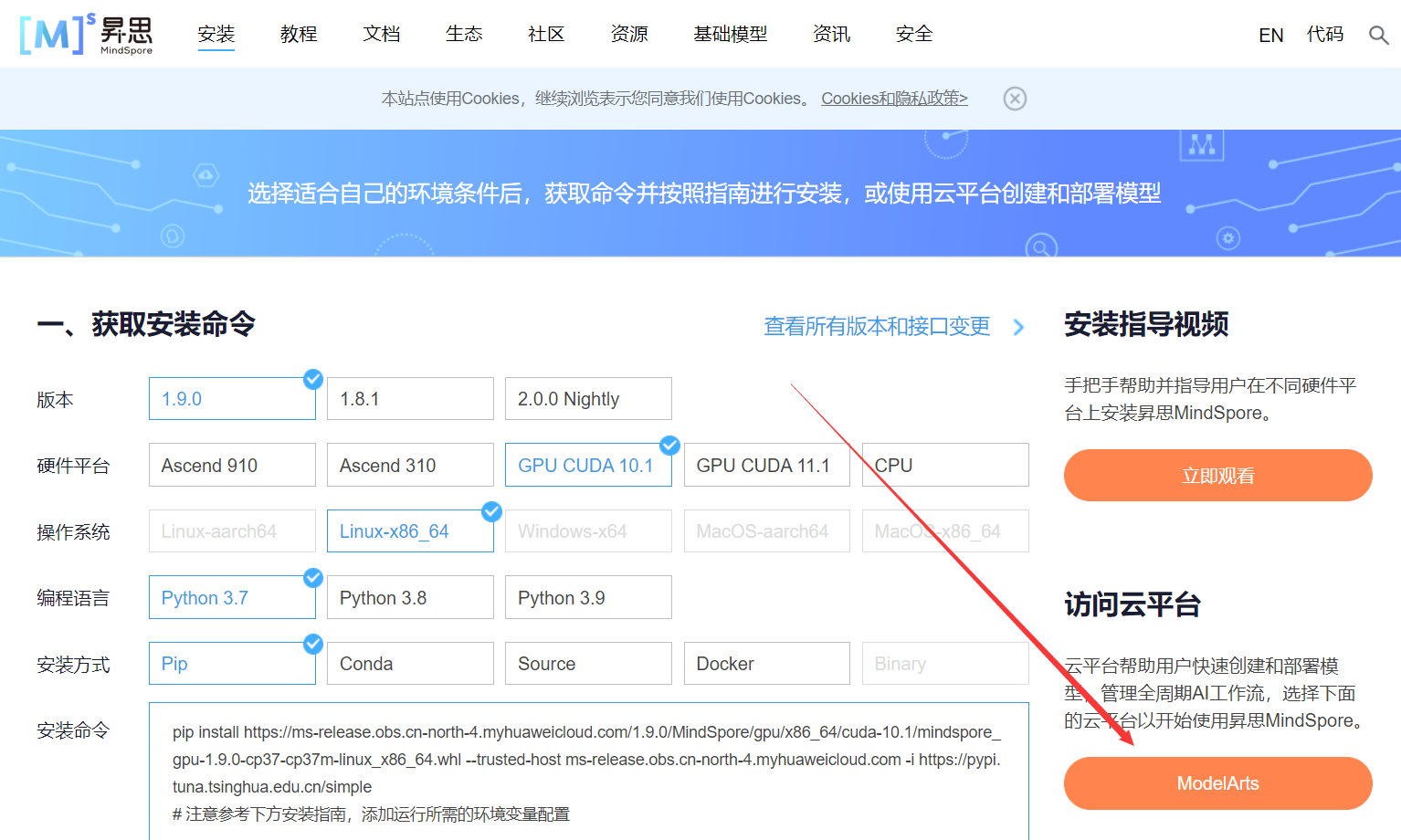
选择下方CodeLab立即体验
等待环境搭建完成
2.使用CodeLab体验Notebook实例
下载NoteBook样例代码,
.ipynb
为样例代码,faces文件夹中有动漫头像数据集共有70,171张动漫头像图片,图片大小均为96*96
选择ModelArts Upload Files上传
.ipynb
文件
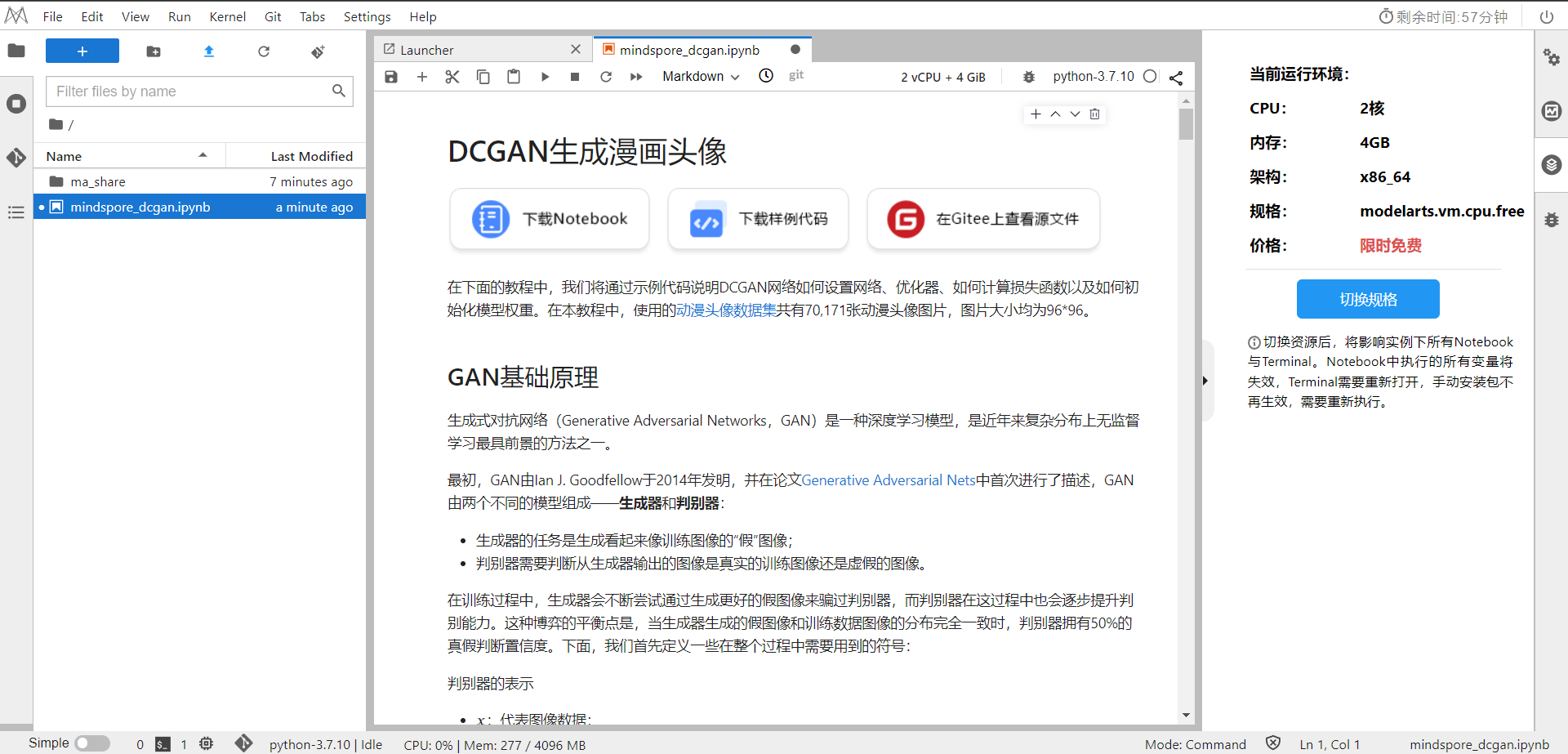
选择Kernel环境
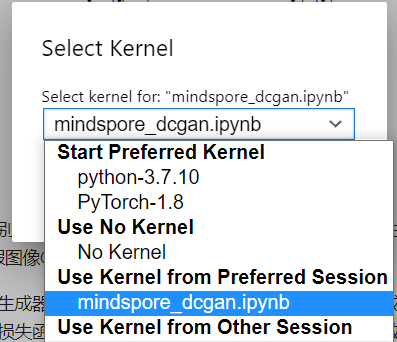
进入昇思MindSpore官网,点击上方的安装

获取安装命令
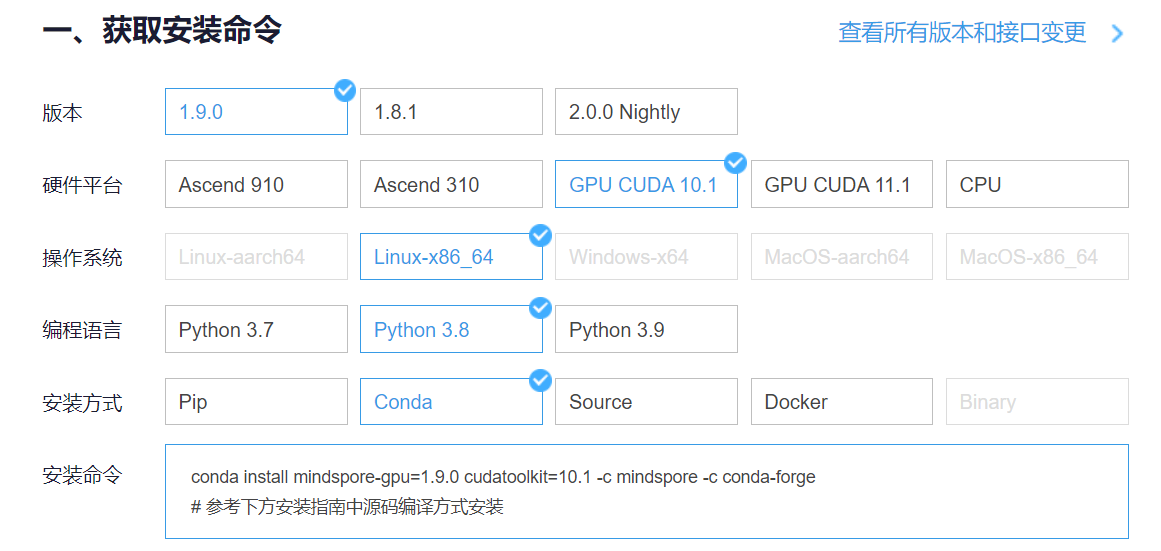
回到Notebook中,在第一块代码前加入三块命令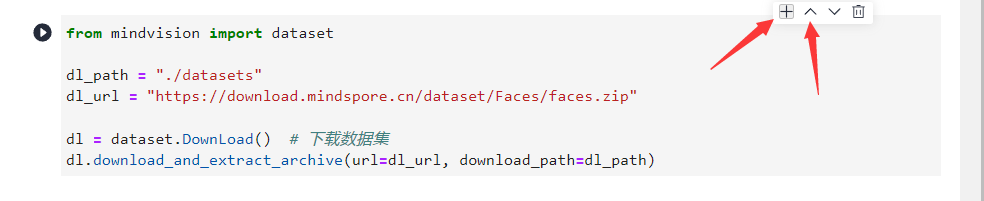
pip install --upgrade pip
conda install mindspore-gpu=1.9.0 cudatoolkit=10.1-c mindspore -c conda-forge
pip install mindvision
依次运行即可
三、数据准备与处理
首先我们将数据集下载到指定目录下并解压。示例代码如下:
from mindvision import dataset
dl_path ="./datasets"
dl_url ="https://download.mindspore.cn/dataset/Faces/faces.zip"
dl = dataset.DownLoad()# 下载数据集
dl.download_and_extract_archive(url=dl_url, download_path=dl_path)

注意:如果这里显示
ImportError: libcudart.so.10.1: cannot open shared object file: No such file or directory说明你选择的MindSpore安装版本有问题,请从头再来,并切换至GPU版本的MindSpore,同时在选择执行模式为图模式,指定训练使用的平台为"GPU"
得到动漫头像数据集
1.数据处理
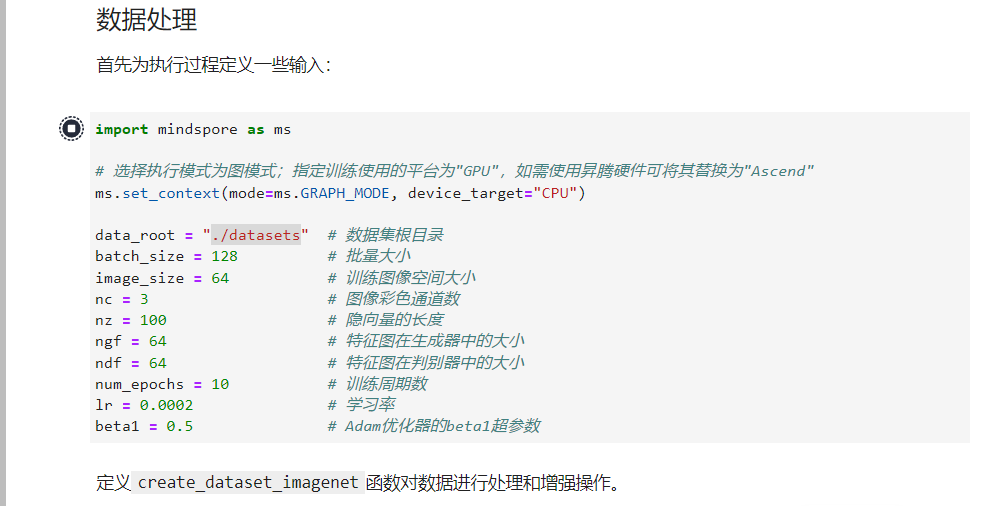
首先为执行过程定义一些输入:
import mindspore as ms
# 选择执行模式为图模式;指定训练使用的平台为"GPU",如需使用昇腾硬件可将其替换为"Ascend"
ms.set_context(mode=ms.GRAPH_MODE, device_target="GPU")
data_root ="./datasets"# 数据集根目录
batch_size =128# 批量大小
image_size =64# 训练图像空间大小
nc =3# 图像彩色通道数
nz =100# 隐向量的长度
ngf =64# 特征图在生成器中的大小
ndf =64# 特征图在判别器中的大小
num_epochs =10# 训练周期数
lr =0.0002# 学习率
beta1 =0.5# Adam优化器的beta1超参数
定义
create_dataset_imagenet
函数对数据进行处理和增强操作。
import numpy as np
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
from mindspore import nn, ops
defcreate_dataset_imagenet(dataset_path):"""数据加载"""
data_set = ds.ImageFolderDataset(dataset_path,
num_parallel_workers=4,
shuffle=True,
decode=True)# 数据增强操作
transform_img =[
vision.Resize(image_size),
vision.CenterCrop(image_size),
vision.HWC2CHW(),lambda x:((x /255).astype("float32"), np.random.normal(size=(nz,1,1)).astype("float32"))]# 数据映射操作
data_set = data_set.map(input_columns="image",
num_parallel_workers=4,
operations=transform_img,
output_columns=["image","latent_code"],
column_order=["image","latent_code"])# 批量操作
data_set = data_set.batch(batch_size)return data_set
# 获取处理后的数据集
data = create_dataset_imagenet(data_root)# 获取数据集大小
size = data.get_dataset_size()
通过
create_dict_iterator
函数将数据转换成字典迭代器,然后使用
matplotlib
模块可视化部分训练数据。
import matplotlib.pyplot as plt
%matplotlib inline
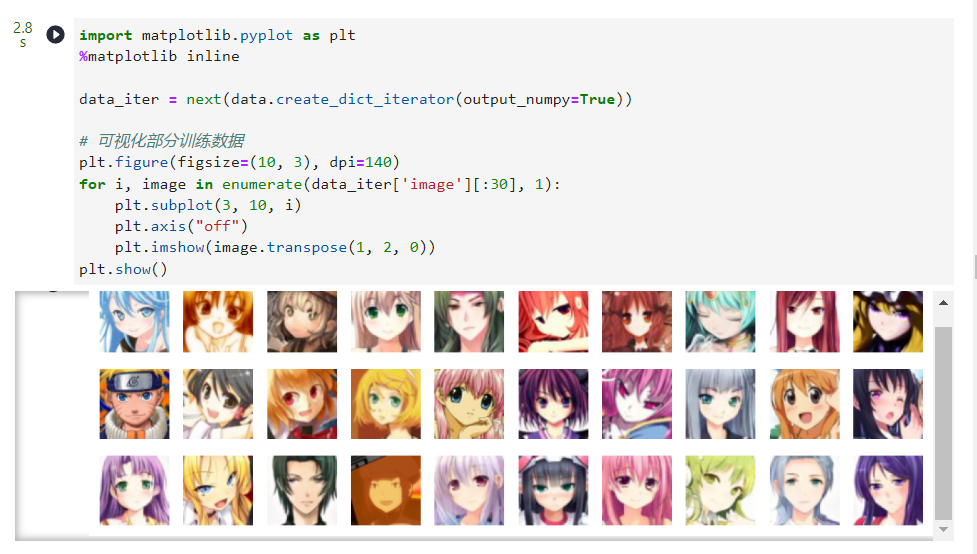
data_iter =next(data.create_dict_iterator(output_numpy=True))# 可视化部分训练数据
plt.figure(figsize=(10,3), dpi=140)for i, image inenumerate(data_iter['image'][:30],1):
plt.subplot(3,10, i)
plt.axis("off")
plt.imshow(image.transpose(1,2,0))
plt.show()

四、创建网络
当处理完数据后,就可以来进行网络的搭建了。按照DCGAN论文中的描述,所有模型权重均应从
mean
为0,
sigma
为0.02的正态分布中随机初始化。
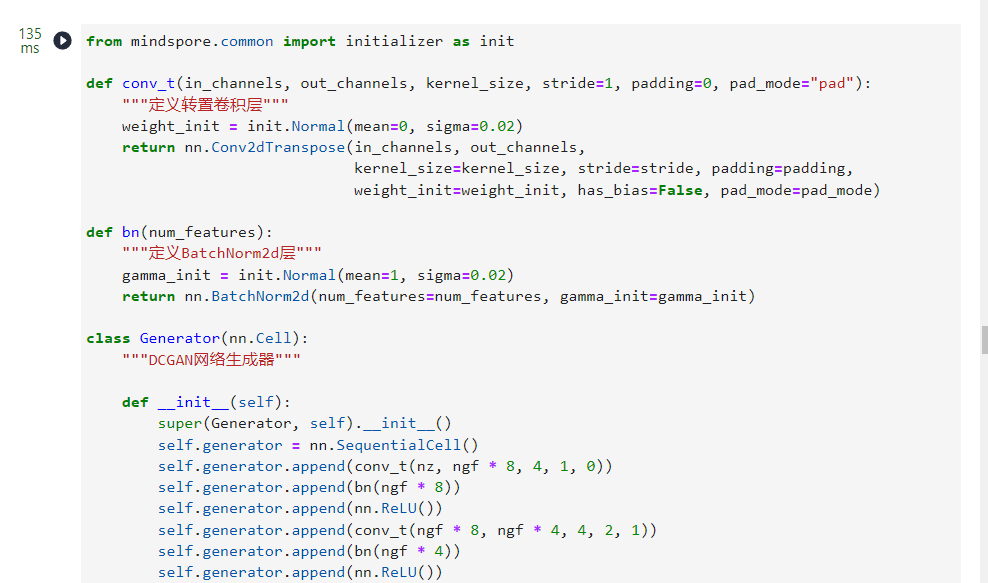
1.生成器
我们通过输入部分中设置的
nz
、
ngf
和
nc
来影响代码中的生成器结构。
nz
是隐向量
z
的长度,
ngf
与通过生成器传播的特征图的大小有关,
nc
是输出图像中的通道数。
from mindspore.common import initializer as init
defconv_t(in_channels, out_channels, kernel_size, stride=1, padding=0, pad_mode="pad"):"""定义转置卷积层"""
weight_init = init.Normal(mean=0, sigma=0.02)return nn.Conv2dTranspose(in_channels, out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
weight_init=weight_init, has_bias=False, pad_mode=pad_mode)defbn(num_features):"""定义BatchNorm2d层"""
gamma_init = init.Normal(mean=1, sigma=0.02)return nn.BatchNorm2d(num_features=num_features, gamma_init=gamma_init)classGenerator(nn.Cell):"""DCGAN网络生成器"""def__init__(self):super(Generator, self).__init__()
self.generator = nn.SequentialCell()
self.generator.append(conv_t(nz, ngf *8,4,1,0))
self.generator.append(bn(ngf *8))
self.generator.append(nn.ReLU())
self.generator.append(conv_t(ngf *8, ngf *4,4,2,1))
self.generator.append(bn(ngf *4))
self.generator.append(nn.ReLU())
self.generator.append(conv_t(ngf *4, ngf *2,4,2,1))
self.generator.append(bn(ngf *2))
self.generator.append(nn.ReLU())
self.generator.append(conv_t(ngf *2, ngf,4,2,1))
self.generator.append(bn(ngf))
self.generator.append(nn.ReLU())
self.generator.append(conv_t(ngf, nc,4,2,1))
self.generator.append(nn.Tanh())defconstruct(self, x):return self.generator(x)# 实例化生成器
netG = Generator()
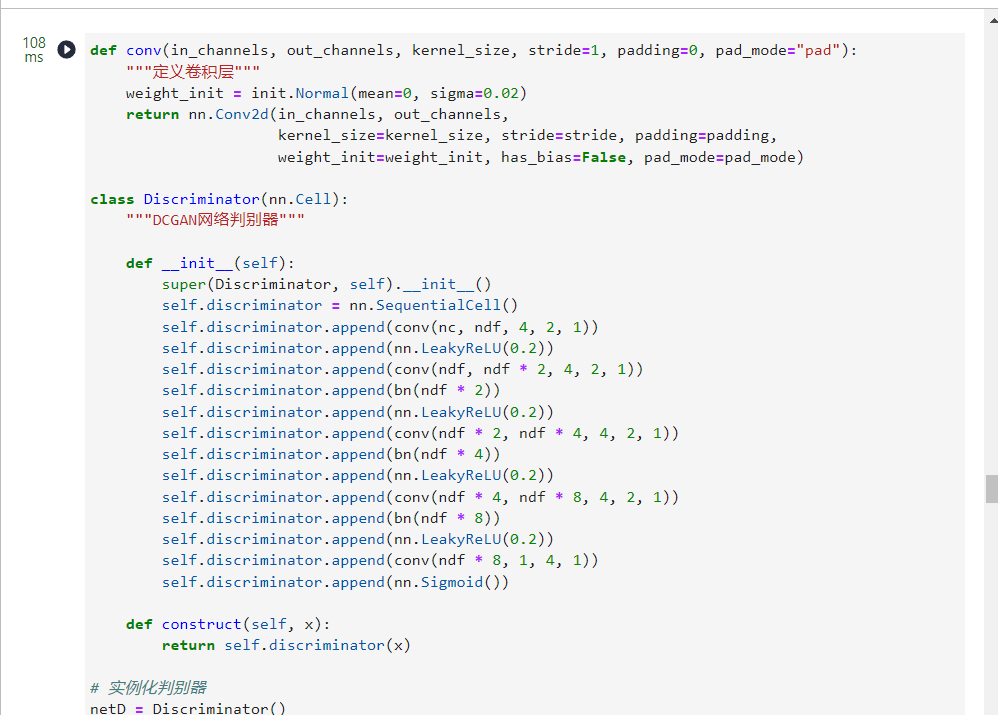
2.判别器
判别器
D
是一个二分类网络模型,输出判定该图像为真实图的概率。通过一系列的
Conv2d
、
BatchNorm2d
和
LeakyReLU
层对其进行处理,最后通过
Sigmoid
激活函数得到最终概率。
DCGAN论文提到,使用卷积而不是通过池化来进行下采样是一个好方法,因为它可以让网络学习自己的池化特征。
判别器的代码实现如下:
defconv(in_channels, out_channels, kernel_size, stride=1, padding=0, pad_mode="pad"):"""定义卷积层"""
weight_init = init.Normal(mean=0, sigma=0.02)return nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
weight_init=weight_init, has_bias=False, pad_mode=pad_mode)classDiscriminator(nn.Cell):"""DCGAN网络判别器"""def__init__(self):super(Discriminator, self).__init__()
self.discriminator = nn.SequentialCell()
self.discriminator.append(conv(nc, ndf,4,2,1))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf, ndf *2,4,2,1))
self.discriminator.append(bn(ndf *2))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf *2, ndf *4,4,2,1))
self.discriminator.append(bn(ndf *4))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf *4, ndf *8,4,2,1))
self.discriminator.append(bn(ndf *8))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf *8,1,4,1))
self.discriminator.append(nn.Sigmoid())defconstruct(self, x):return self.discriminator(x)# 实例化判别器
netD = Discriminator()
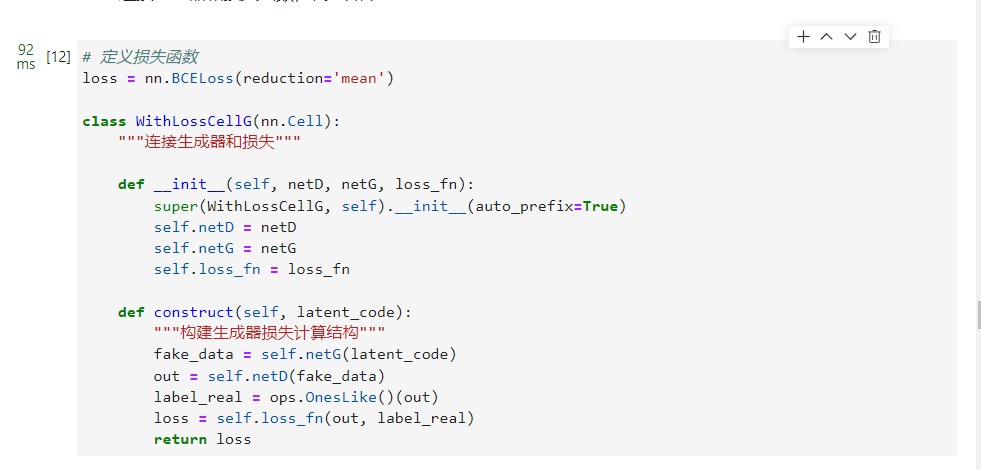
3.损失和优化器
MindSpore将损失函数、优化器等操作都封装到了Cell中,因为GAN结构上的特殊性,其损失是判别器和生成器的多输出形式,这就导致它和一般的分类网络不同。所以我们需要自定义
WithLossCell
类,将网络和Loss连接起来。
损失函数
当定义了
D
和
G
后,接下来将使用MindSpore中定义的二进制交叉熵损失函数BCELoss ,为
D
和
G
加上损失函数和优化器。
连接生成器和损失函数,代码如下:
# 定义损失函数
loss = nn.BCELoss(reduction='mean')classWithLossCellG(nn.Cell):"""连接生成器和损失"""def__init__(self, netD, netG, loss_fn):super(WithLossCellG, self).__init__(auto_prefix=True)
self.netD = netD
self.netG = netG
self.loss_fn = loss_fn
defconstruct(self, latent_code):"""构建生成器损失计算结构"""
fake_data = self.netG(latent_code)
out = self.netD(fake_data)
label_real = ops.OnesLike()(out)
loss = self.loss_fn(out, label_real)return loss
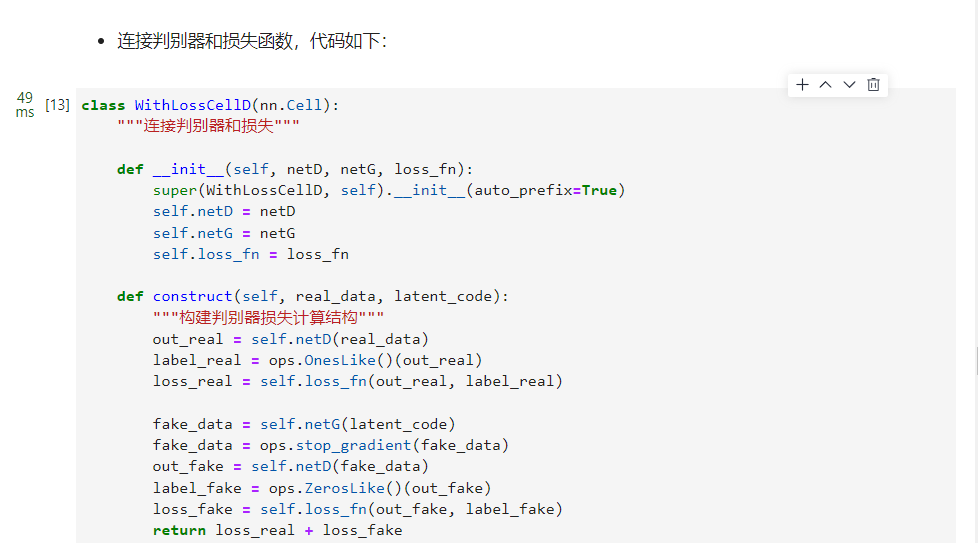
连接判别器和损失函数,代码如下:
classWithLossCellD(nn.Cell):"""连接判别器和损失"""def__init__(self, netD, netG, loss_fn):super(WithLossCellD, self).__init__(auto_prefix=True)
self.netD = netD
self.netG = netG
self.loss_fn = loss_fn
defconstruct(self, real_data, latent_code):"""构建判别器损失计算结构"""
out_real = self.netD(real_data)
label_real = ops.OnesLike()(out_real)
loss_real = self.loss_fn(out_real, label_real)
fake_data = self.netG(latent_code)
fake_data = ops.stop_gradient(fake_data)
out_fake = self.netD(fake_data)
label_fake = ops.ZerosLike()(out_fake)
loss_fake = self.loss_fn(out_fake, label_fake)return loss_real + loss_fake
4.优化器
这里设置了两个单独的优化器,一个用于
D
,另一个用于
G
。这两个都是
lr = 0.0002
和
beta1 = 0.5
的Adam优化器。
为了跟踪生成器的学习进度,在训练的过程中,我们定期将一批固定的遵循高斯分布的隐向量
fixed_noise
输入到
G
中,可以看到隐向量生成的图像。
# 创建一批隐向量用来观察G
np.random.seed(1)
fixed_noise = ms.Tensor(np.random.randn(64, nz,1,1), dtype=ms.float32)# 为生成器和判别器设置优化器
optimizerD = nn.Adam(netD.trainable_params(), learning_rate=lr, beta1=beta1)
optimizerG = nn.Adam(netG.trainable_params(), learning_rate=lr, beta1=beta1)
五、训练模型
训练判别器的目的是最大程度地提高判别图像真伪的概率。按照Goodfellow的方法,是希望通过提高其随机梯度来更新判别器,所以我们要最大化logD(x)+log(1−D(G(z))的值。
训练生成器如DCGAN论文所述,我们希望通过最小化log(1−D(G(z)))来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每个周期结束时进行统计,将
fixed_noise
批量推送到生成器中,以直观地跟踪
G
的训练进度。
下面进行训练:
classDCGAN(nn.Cell):"""定义DCGAN网络"""def__init__(self, myTrainOneStepCellForD, myTrainOneStepCellForG):super(DCGAN, self).__init__(auto_prefix=True)
self.myTrainOneStepCellForD = myTrainOneStepCellForD
self.myTrainOneStepCellForG = myTrainOneStepCellForG
defconstruct(self, real_data, latent_code):
output_D = self.myTrainOneStepCellForD(real_data, latent_code).view(-1)
netD_loss = output_D.mean()
output_G = self.myTrainOneStepCellForG(latent_code).view(-1)
netG_loss = output_G.mean()return netD_loss, netG_loss
实例化生成器和判别器的
WithLossCell
和
TrainOneStepCell
。
# 实例化WithLossCell
netD_with_criterion = WithLossCellD(netD, netG, loss)
netG_with_criterion = WithLossCellG(netD, netG, loss)# 实例化TrainOneStepCell
myTrainOneStepCellForD = nn.TrainOneStepCell(netD_with_criterion, optimizerD)
myTrainOneStepCellForG = nn.TrainOneStepCell(netG_with_criterion, optimizerG)

循环训练网络,每经过50次迭代,就收集生成器和判别器的损失,以便于后面绘制训练过程中损失函数的图像。
# 实例化DCGAN网络
dcgan = DCGAN(myTrainOneStepCellForD, myTrainOneStepCellForG)
dcgan.set_train()# 创建迭代器
data_loader = data.create_dict_iterator(output_numpy=True, num_epochs=num_epochs)
G_losses =[]
D_losses =[]
image_list =[]# 开始循环训练print("Starting Training Loop...")for epoch inrange(num_epochs):# 为每轮训练读入数据for i, d inenumerate(data_loader):
real_data = ms.Tensor(d['image'])
latent_code = ms.Tensor(d["latent_code"])
netD_loss, netG_loss = dcgan(real_data, latent_code)if i %50==0or i == size -1:# 输出训练记录print('[%2d/%d][%3d/%d] Loss_D:%7.4f Loss_G:%7.4f'%(
epoch +1, num_epochs, i +1, size, netD_loss.asnumpy(), netG_loss.asnumpy()))
D_losses.append(netD_loss.asnumpy())
G_losses.append(netG_loss.asnumpy())# 每个epoch结束后,使用生成器生成一组图片
img = netG(fixed_noise)
image_list.append(img.transpose(0,2,3,1).asnumpy())# 保存网络模型参数为ckpt文件
ms.save_checkpoint(netG,"Generator.ckpt")
ms.save_checkpoint(netD,"Discriminator.ckpt")
这里训练时间比较长,请耐心等待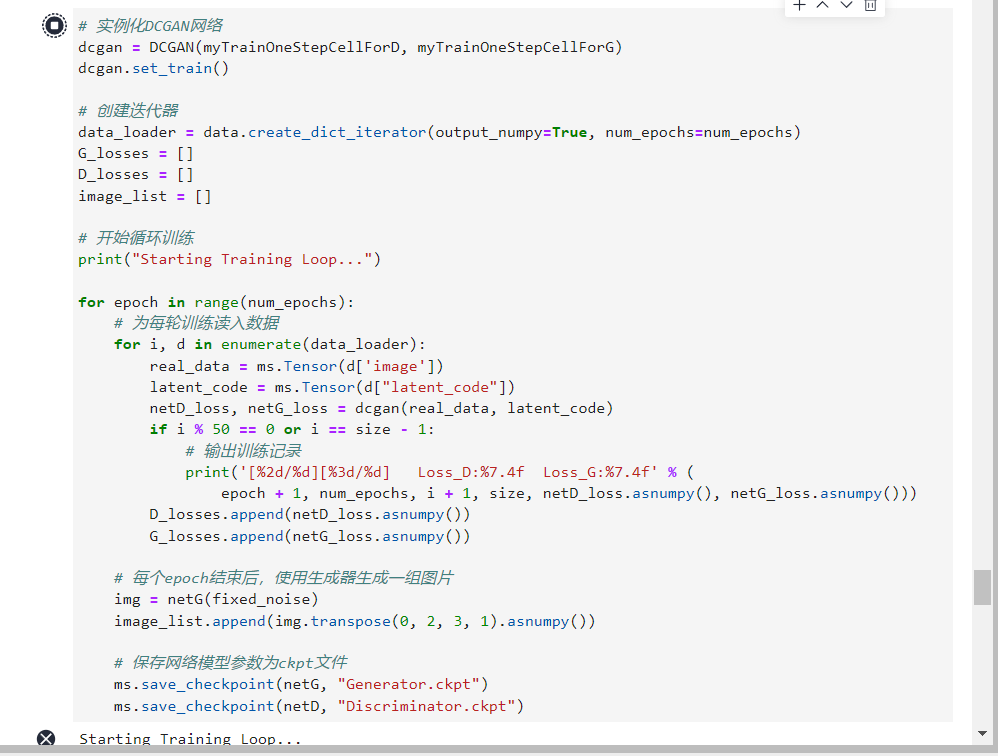
Starting Training Loop...[1/10][1/523] Loss_D:1.3341 Loss_G:4.4303[1/10][51/523] Loss_D:0.0001 Loss_G:27.6309[1/10][101/523] Loss_D:0.0000 Loss_G:27.6309[1/10][151/523] Loss_D:0.0000 Loss_G:27.6309[1/10][201/523] Loss_D:0.0000 Loss_G:27.6309[1/10][251/523] Loss_D:0.0000 Loss_G:27.6308[1/10][301/523] Loss_D:0.0000 Loss_G:27.6309[1/10][351/523] Loss_D:0.0000 Loss_G:27.6306[1/10][401/523] Loss_D:7.1362 Loss_G:10.8959[1/10][451/523] Loss_D:2.7982 Loss_G:1.6938[1/10][501/523] Loss_D:0.5665 Loss_G:3.3509[1/10][523/523] Loss_D:0.8589 Loss_G:5.8118[2/10][1/523] Loss_D:0.7220 Loss_G:3.6486[2/10][51/523] Loss_D:0.9084 Loss_G:3.4355[2/10][101/523] Loss_D:0.7106 Loss_G:3.3597[2/10][151/523] Loss_D:1.2464 Loss_G:3.8619[2/10][201/523] Loss_D:1.4379 Loss_G:1.4148[2/10][251/523] Loss_D:0.5010 Loss_G:2.6713[2/10][301/523] Loss_D:0.8369 Loss_G:3.2203[2/10][351/523] Loss_D:0.8340 Loss_G:2.7246[2/10][401/523] Loss_D:0.7258 Loss_G:3.1784[2/10][451/523] Loss_D:0.6898 Loss_G:3.4755[2/10][501/523] Loss_D:0.9853 Loss_G:3.4425[2/10][523/523] Loss_D:0.8548 Loss_G:2.3108[3/10][1/523] Loss_D:1.1206 Loss_G:6.0529[3/10][51/523] Loss_D:0.6412 Loss_G:3.2571[3/10][101/523] Loss_D:0.7830 Loss_G:3.2050[3/10][151/523] Loss_D:1.0531 Loss_G:4.0849[3/10][201/523] Loss_D:0.4773 Loss_G:3.4415[3/10][251/523] Loss_D:1.0287 Loss_G:5.1689[3/10][301/523] Loss_D:0.7435 Loss_G:4.2903[3/10][351/523] Loss_D:0.7258 Loss_G:3.4914[3/10][401/523] Loss_D:0.9525 Loss_G:1.8072[3/10][451/523] Loss_D:0.7222 Loss_G:2.1848[3/10][501/523] Loss_D:0.4841 Loss_G:3.8900[3/10][523/523] Loss_D:1.3593 Loss_G:1.6790[4/10][1/523] Loss_D:1.3692 Loss_G:6.2913[4/10][51/523] Loss_D:0.8611 Loss_G:3.9655[4/10][101/523] Loss_D:1.3133 Loss_G:2.4826[4/10][151/523] Loss_D:0.6847 Loss_G:5.1198[4/10][201/523] Loss_D:0.6726 Loss_G:3.9191[4/10][251/523] Loss_D:1.3120 Loss_G:2.4799[4/10][301/523] Loss_D:0.5391 Loss_G:2.5938[4/10][351/523] Loss_D:0.5148 Loss_G:3.3189[4/10][401/523] Loss_D:0.5152 Loss_G:2.1859[4/10][451/523] Loss_D:0.4354 Loss_G:3.7258[4/10][501/523] Loss_D:0.8461 Loss_G:1.6059[4/10][523/523] Loss_D:0.8209 Loss_G:1.4153[5/10][1/523] Loss_D:1.3621 Loss_G:8.4941[5/10][51/523] Loss_D:0.6527 Loss_G:3.3710[5/10][101/523] Loss_D:0.4800 Loss_G:3.0760[5/10][151/523] Loss_D:0.5460 Loss_G:2.8898[5/10][201/523] Loss_D:0.7443 Loss_G:2.4008[5/10][251/523] Loss_D:0.9210 Loss_G:5.4013[5/10][301/523] Loss_D:0.5267 Loss_G:3.1586[5/10][351/523] Loss_D:0.5461 Loss_G:4.4159[5/10][401/523] Loss_D:0.5737 Loss_G:3.2949[5/10][451/523] Loss_D:0.9223 Loss_G:1.4930[5/10][501/523] Loss_D:0.9890 Loss_G:5.1565[5/10][523/523] Loss_D:0.8597 Loss_G:5.6968[6/10][1/523] Loss_D:0.8149 Loss_G:1.9866[6/10][51/523] Loss_D:1.3344 Loss_G:8.2650[6/10][101/523] Loss_D:0.5464 Loss_G:2.9574[6/10][151/523] Loss_D:0.5783 Loss_G:3.9141[6/10][201/523] Loss_D:0.5426 Loss_G:4.5565[6/10][251/523] Loss_D:0.5757 Loss_G:2.4842[6/10][301/523] Loss_D:0.7165 Loss_G:4.2469[6/10][351/523] Loss_D:0.5514 Loss_G:1.9710[6/10][401/523] Loss_D:0.5034 Loss_G:3.3386[6/10][451/523] Loss_D:0.5529 Loss_G:2.5434[6/10][501/523] Loss_D:0.5793 Loss_G:4.5730[6/10][523/523] Loss_D:0.4959 Loss_G:2.3813[7/10][1/523] Loss_D:0.5583 Loss_G:4.7816[7/10][51/523] Loss_D:0.4124 Loss_G:3.1867[7/10][101/523] Loss_D:0.5679 Loss_G:2.6333[7/10][151/523] Loss_D:0.4654 Loss_G:3.8254[7/10][201/523] Loss_D:0.6624 Loss_G:1.2572[7/10][251/523] Loss_D:0.6794 Loss_G:4.7149[7/10][301/523] Loss_D:0.5441 Loss_G:4.5748[7/10][351/523] Loss_D:0.5405 Loss_G:4.4008[7/10][401/523] Loss_D:0.8556 Loss_G:5.3858[7/10][451/523] Loss_D:0.8062 Loss_G:1.3542[7/10][501/523] Loss_D:0.7903 Loss_G:1.2369[7/10][523/523] Loss_D:1.0799 Loss_G:1.1563[8/10][1/523] Loss_D:1.1528 Loss_G:6.3701[8/10][51/523] Loss_D:0.5500 Loss_G:2.5632[8/10][101/523] Loss_D:0.8834 Loss_G:5.6649[8/10][151/523] Loss_D:0.4682 Loss_G:1.9880[8/10][201/523] Loss_D:0.8519 Loss_G:2.0310[8/10][251/523] Loss_D:1.5056 Loss_G:7.7112[8/10][301/523] Loss_D:0.4374 Loss_G:3.1714[8/10][351/523] Loss_D:0.3988 Loss_G:3.2287[8/10][401/523] Loss_D:0.6580 Loss_G:3.8090[8/10][451/523] Loss_D:0.5487 Loss_G:3.6912[8/10][501/523] Loss_D:0.5297 Loss_G:3.9933[8/10][523/523] Loss_D:0.7350 Loss_G:4.5166[9/10][1/523] Loss_D:0.8367 Loss_G:1.3991[9/10][51/523] Loss_D:1.0498 Loss_G:5.8035[9/10][101/523] Loss_D:0.5274 Loss_G:2.9916[9/10][151/523] Loss_D:0.9688 Loss_G:1.4680[9/10][201/523] Loss_D:0.4435 Loss_G:3.0589[9/10][251/523] Loss_D:0.4547 Loss_G:3.3577[9/10][301/523] Loss_D:0.5956 Loss_G:3.5646[9/10][351/523] Loss_D:0.4052 Loss_G:2.3165[9/10][401/523] Loss_D:0.4558 Loss_G:2.6287[9/10][451/523] Loss_D:0.8953 Loss_G:5.1640[9/10][501/523] Loss_D:0.5268 Loss_G:2.0344[9/10][523/523] Loss_D:0.4568 Loss_G:2.3330[10/10][1/523] Loss_D:0.6627 Loss_G:4.1249[10/10][51/523] Loss_D:0.6725 Loss_G:3.5604[10/10][101/523] Loss_D:0.7393 Loss_G:2.1902[10/10][151/523] Loss_D:2.1423 Loss_G:6.3001[10/10][201/523] Loss_D:0.6502 Loss_G:1.6308[10/10][251/523] Loss_D:0.6091 Loss_G:3.5198[10/10][301/523] Loss_D:0.3418 Loss_G:3.1872[10/10][351/523] Loss_D:0.9850 Loss_G:1.7839[10/10][401/523] Loss_D:0.6159 Loss_G:1.9957[10/10][451/523] Loss_D:0.4779 Loss_G:2.7053[10/10][501/523] Loss_D:0.6780 Loss_G:2.0838[10/10][523/523] Loss_D:0.5710 Loss_G:3.4589
结果展示
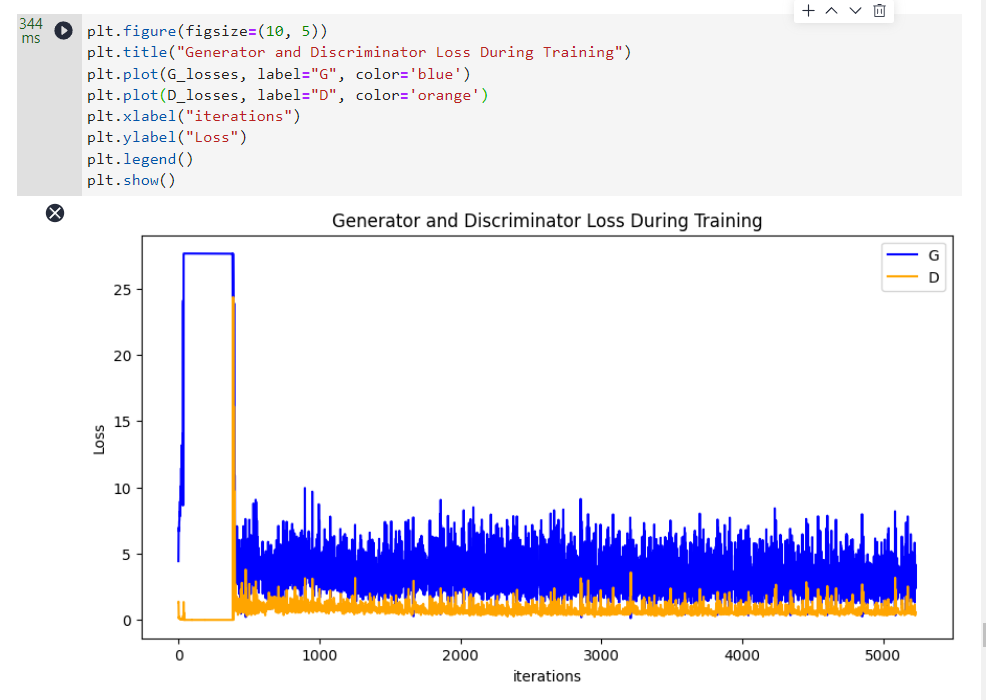
六、结果展示
运行下面代码,描绘
D
和
G
损失与训练迭代的关系图:
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G", color='blue')
plt.plot(D_losses, label="D", color='orange')
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
可视化训练过程中通过隐向量
fixed_noise
生成的图像。
import matplotlib.pyplot as plt
import matplotlib.animation as animation
defshowGif(image_list):
show_list =[]
fig = plt.figure(figsize=(8,3), dpi=120)for epoch inrange(len(image_list)):
images =[]for i inrange(3):
row = np.concatenate((image_list[epoch][i *8:(i +1)*8]), axis=1)
images.append(row)
img = np.clip(np.concatenate((images[:]), axis=0),0,1)
plt.axis("off")
show_list.append([plt.imshow(img)])
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
ani.save('./dcgan.gif', writer='pillow', fps=1)
showGif(image_list)
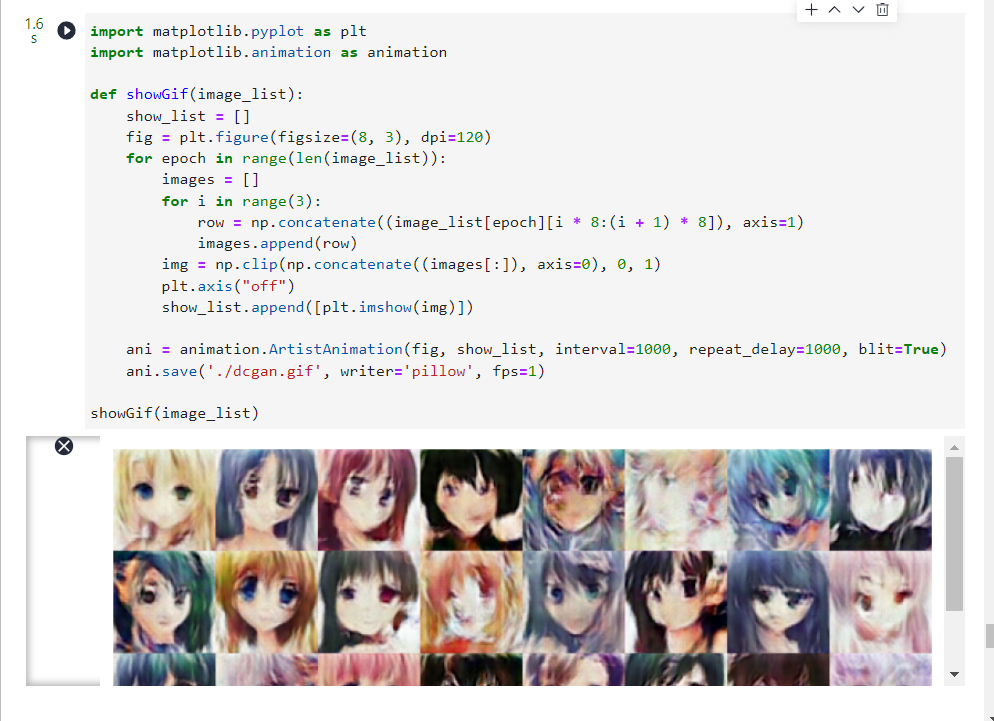

注意:训练到此已经结束,最终图像如上
这是原始图像

随着训练次数的增多,图像质量也越来越好。如果增大训练周期数,当
num_epochs
达到50以上时,生成的动漫头像图片与数据集中的较为相似,下面我们通过加载训练周期为50的生成器网络模型参数文件Generator.ckpt来生成图像,代码如下:
from mindvision import dataset
dl_path ="./netG"
dl_url ="https://download.mindspore.cn/vision/classification/Generator.ckpt"
dl = dataset.DownLoad()# 下载Generator.ckpt文件
dl.download_url(url=dl_url, path=dl_path)# 从文件中获取模型参数并加载到网络中
param_dict = ms.load_checkpoint("./netG/Generator.ckpt", netG)
img64 = netG(fixed_noise).transpose(0,2,3,1).asnumpy()
fig = plt.figure(figsize=(8,3), dpi=120)
images =[]for i inrange(3):
images.append(np.concatenate((img64[i *8:(i +1)*8]), axis=1))
img = np.clip(np.concatenate((images[:]), axis=0),0,1)
plt.axis("off")
plt.imshow(img)
plt.show()

注意:最后这块代码生成的图像是固定的
版权归原作者 Yeats_Liao 所有, 如有侵权,请联系我们删除。