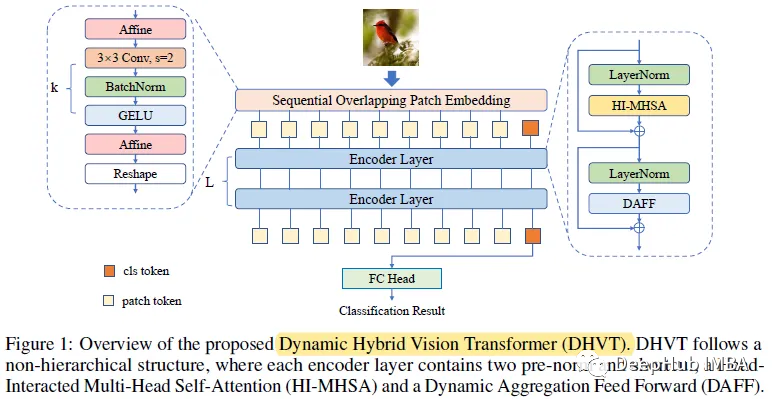
DHVT:在小数据集上降低VIT与卷积神经网络之间差距,解决从零开始训练的问题
VIT在归纳偏置方面存在空间相关性和信道表示的多样性两大缺陷。所以论文提出了动态混合视觉变压器(DHVT)来增强这两种感应偏差。
Yolov5 激活函数
activation.py文件
深入浅出PaddlePaddle函数——paddle.to_tensor
paddle.to_tensor
yolov5模型(.pt)在RK3588(S)上的部署(实时摄像头检测)
yolov5模型(.pt)在RK3588(S)上的部署(实时摄像头检测)
手把手教你训练一个VAE生成模型一生成手写数字
本文将教你设计并训练一个VAE变分自编码器模型,用于生成指定的手写数字图像
【深度学习:入门】如何配置CUDA,使用gpu本地训练
由于显卡的不同,需要先查看我们显卡及驱动最高支持的cuda。进入cmd输入版本支持向下兼容,为了保证能够和其他开发库版本兼容,这里使用的CUDN版本为11.6.
【AIGC】AI欺诈,做好以下几点,无需忧虑
近年来,人工智能(AI)技术的飞速发展为我们的生活带来了诸多便利。然而,一枚硬币总有两面。随着AI技术的广泛应用,AI诈骗也逐渐成为了一个值得关注的问题。最近一则Ai换脸诈骗的新闻,传遍全网,值得我们所有人注意与防范。如果大家对相关文章感兴趣,可以关注公众号"架构殿堂",会持续更新AIGC,java
深入浅出PaddlePaddle函数——paddle.ones_like
paddle.ones_like
YOLO v5结合热力图并可视化以及网络各层的特征图
YOLO v5结合热力图并可视化以及网络各层的特征图
AIGC图像生成的原理综述与落地畅想
AIGC,这个当前的现象级词语。本文尝试从文生图的发展、对其当前主流的 Stable Diffusion 做一个综述。以下为实验按要求生成的不同场景、风格控制下的生成作品。概述▐技术演进一:昙花初现 GAN 家族GAN 系列算法开启了图片生成的新起点。GAN的主要灵感来源于博弈论中零和博弈的思想,通
YOLOV5实战教程(超级详细图文教程)!!!
1.本文的目的在于帮助读者实现yolov5的训练,测试以及使用,偏重应用,将有较少代码讲解2.本文将首先示范使用coco128数据集进行训练,向读者展示整个模型的使用过程,之后介绍如何制作自己的数据集并进行训练3.本文使用的数据集coco128放在网盘里了,如果没有这个数据集的话可以去网盘上下载,y
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
在本节中,我们将了解传统机器学习与人工神经网络间的差异,并了解如何在实现前向传播之前连接网络的各个层,以计算与网络当前权重对应的损失值;实现反向传播以优化权重达到最小化损失值的目标。并将实现网络的所有关键组成——前向传播、激活函数、损失函数、链式法则和梯度下降,从零开始构建并训练了一个简单的神经网络
Segment anything(SAM)论文及demo使用保姆级教程
解读segment anything(SAM)论文并提供SAM模型demo的保姆级使用教程
【AI】AI 工具合集
ai 工具集合, 包括 AI文本、AI 视频、AI 音频、AI 绘画
基于深度强化学习的目标驱动型视觉导航泛化模型
目标是仅使用视觉输入就能导航并到达用户指定目标的机器人,对于此类问题的解决办法一般有两种。基于地图的导航算法或者SLAM系统与最先进的物体检测或图像识别模型的局限性深度卷积神经网络(cnn)与强化学习(RL)相结合的方法优势 深度强化学习(DRL)确实允许以自然的方式管理视觉和运动之间的关系,
YOLOv8:车辆检测技术及优化
随着自动驾驶汽车和智能交通系统的发展,车辆检测技术在近年来变得越来越重要。为了解决这一问题,YOLO (You Only Look Once) 是一种实时目标检测算法,自从2016年推出以来,它已经经历了多个版本的更新。本文将详细介绍YOLOv8,这是一个最新的、高效的车辆检测方法,并附有Pytho
过拟合解决
常见过拟合问题解决
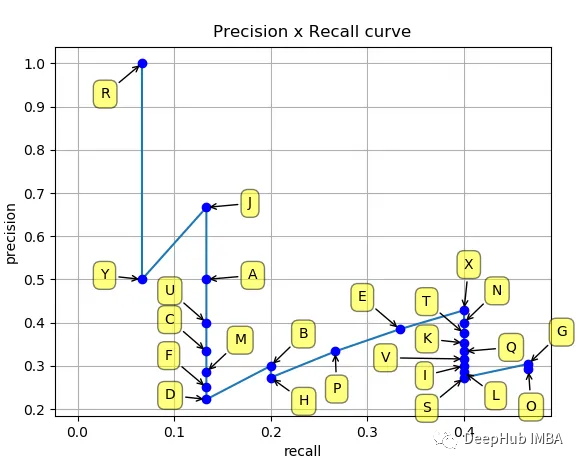
深入了解平均精度(mAP):通过精确率-召回率曲线评估目标检测性能
平均精度(Average Precision,mAP)是一种常用的用于评估目标检测模型性能的指标。
Pytorch:手把手教你搭建简单的全连接网络
利用pytorch搭建简单全连接网络的步骤,适合初学者快速上手
使用pytorch实现LSTM自动AI作诗(藏头诗和首句续写)
数据来源于chinese-poetry,最全中文诗歌古典文集数据库最全的中华古典文集数据库,包含 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗 人包括唐宋两朝近 1.4 万古诗人,和两宋时期 1.5 千古词人。实验使用预处理过的二进制文件tang.npz作为数据集,含有575



