
之前尝试了从0到1复现斯坦福羊驼(Stanford Alpaca 7B),Stanford Alpaca 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。
因此, Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降(使用一块 RTX 4090 显卡,只用 5 个小时就训练了一个与 Alpaca 水平相当的模型,将这类模型对算力的需求降到了消费级),还能获得和全模型微调(full fine-tuning)类似的效果。
LoRA 技术原理
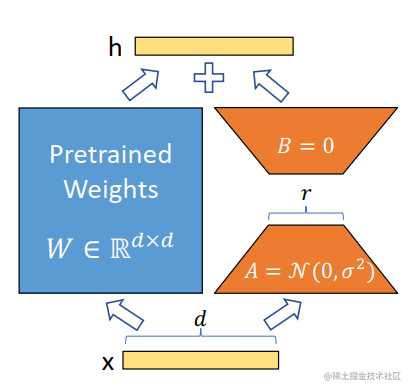
LoRA 的原理其实并不复杂,它的核心思想是在原始预训练语言模型旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank(预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征(low-dimensional intrinsic)子空间中非常少量的几个自由参数)。训练的时候固定预训练语言模型的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B。这样能保证训练开始时,新增的通路BA=0从,而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
LoRA 的最大优势是速度更快,使用的内存更少;因此,可以在消费级硬件上运行。
下面,我们来尝试使用Alpaca-Lora进行参数高效模型微调。
环境搭建
基础环境配置如下:
- 操作系统: CentOS 7
- CPUs: 单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
- GPUs: 8 卡 A800 80GB GPUs
- Python: 3.10 (需要先升级OpenSSL到1.1.1t版本(点击下载OpenSSL),然后再编译安装Python),点击下载Python
- NVIDIA驱动程序版本: 515.65.01,根据不同型号选择不同的驱动程序,点击下载。
- CUDA工具包: 11.7,点击下载
- NCCL: nccl_2.14.3-1+cuda11.7,点击下载
- cuDNN: 8.8.1.3_cuda11,点击下载
上面的NVIDIA驱动、CUDA、Python等工具的安装就不一一赘述了。
创建虚拟环境并激活虚拟环境alpara-lora-venv-py310-cu117:
cd /home/guodong.li/virtual-venv
virtualenv -p /usr/bin/python3.10 alpara-lora-venv-py310-cu117
source /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/bin/activate
离线安装PyTorch,点击下载对应cuda版本的torch和torchvision即可。
pip install torch-1.13.1+cu117-cp310-cp310-linux_x86_64.whl
pip install pip install torchvision-0.14.1+cu117-cp310-cp310-linux_x86_64.whl
安装transformers,目前,LLaMA相关的实现并没有发布对应的版本,但是已经合并到主分支了,因此,我们需要切换到对应的commit,从源代码进行相应的安装。
cd transformers
git checkout 0041be5
pip install .
在 Alpaca-LoRA 项目中,作者提到,为了廉价高效地进行微调,他们使用了 Hugging Face 的 PEFT。PEFT 是一个库(LoRA 是其支持的技术之一,除此之外还有Prefix Tuning、P-Tuning、Prompt Tuning),可以让你使用各种基于 Transformer 结构的语言模型进行高效微调。下面安装PEFT。
git clone https://github.com/huggingface/peft.git
cd peft/
git checkout e536616
pip install .
安装bitsandbytes。
git clone [email protected]:TimDettmers/bitsandbytes.git
cd bitsandbytes
CUDA_VERSION=117 make cuda11x
python setup.py install
安装其他相关的库。
cd alpaca-lora
pip install -r requirements.txt
requirements.txt
文件具体的内容如下:
accelerate
appdirs
loralib
black
black[jupyter]
datasets
fire
sentencepiece
gradio
模型格式转换
将LLaMA原始权重文件转换为Transformers库对应的模型文件格式。具体可参考之前的文章:从0到1复现斯坦福羊驼(Stanford Alpaca 7B) 。如果不想转换LLaMA模型,也可以直接从Hugging Face下载转换好的模型。
模型微调
训练的默认值如下所示:
batch_size: 128
micro_batch_size: 4
num_epochs: 3
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
使用默认参数,单卡训练完成大约需要5个小时,且对于GPU显存的消耗确实很低。
1%|█▌ | 12/1170 [03:21<5:24:45, 16.83s/it]
本文为了加快训练速度,将batch_size和micro_batch_size调大并将num_epochs调小了。
python finetune.py \
--base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b' \
--data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json' \
--output_dir '/home/guodong.li/output/lora-alpaca' \
--batch_size 256 \
--micro_batch_size 16 \
--num_epochs 2
当然也可以根据需要微调超参数,参考示例如下:
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-alpaca' \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 2000 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--train_on_inputs \
--group_by_length
运行过程:
python finetune.py \
> --base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b' \
> --data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json' \
> --output_dir '/home/guodong.li/output/lora-alpaca' \
> --batch_size 256 \
> --micro_batch_size 16 \
> --num_epochs 2
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
Training Alpaca-LoRA model with params:
base_model: /data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b
data_path: /data/nfs/guodong.li/data/alpaca_data_cleaned.json
output_dir: /home/guodong.li/output/lora-alpaca
batch_size: 256
micro_batch_size: 16
num_epochs: 2
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:10<00:00, 3.01it/s]
Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 228.95it/s]
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
{'loss': 2.2501, 'learning_rate': 2.6999999999999996e-05, 'epoch': 0.05}
...
{'loss': 0.8998, 'learning_rate': 0.000267, 'epoch': 0.46}
{'loss': 0.8959, 'learning_rate': 0.00029699999999999996, 'epoch': 0.51}
28%|███████████████████████████████████████████▎ | 109/390 [32:48<1:23:14, 17.77s/it]
显存占用:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A800 80G... Off | 00000000:34:00.0 Off | 0 |
| N/A 71C P0 299W / 300W | 57431MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
...
+-------------------------------+----------------------+----------------------+
| 7 NVIDIA A800 80G... Off | 00000000:9E:00.0 Off | 0 |
| N/A 33C P0 71W / 300W | 951MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 55017 C python 57429MiB |
...
| 7 N/A N/A 55017 C python 949MiB |
+-----------------------------------------------------------------------------+
发现GPU的使用率上去了,训练速度也提升了,但是没有充分利用GPU资源,单卡训练(epoch:3)大概3小时即可完成。
因此,为了进一步提升模型训练速度,下面尝试使用数据并行,在多卡上面进行训练。
torchrun --nproc_per_node=8 --master_port=29005 finetune.py \
--base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b' \
--data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json' \
--output_dir '/home/guodong.li/output/lora-alpaca' \
--batch_size 256 \
--micro_batch_size 16 \
--num_epochs 2
运行过程:
torchrun --nproc_per_node=8 --master_port=29005 finetune.py \
> --base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b' \
> --data_path '/data/nfs/guodong.li/data/alpaca_data_cleaned.json' \
> --output_dir '/home/guodong.li/output/lora-alpaca' \
> --batch_size 256 \
> --micro_batch_size 16 \
> --num_epochs 2
WARNING:torch.distributed.run:
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
...
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst')}
...
Training Alpaca-LoRA model with params:
base_model: /data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b
data_path: /data/nfs/guodong.li/data/alpaca_data_cleaned.json
output_dir: /home/guodong.li/output/lora-alpaca
batch_size: 256
micro_batch_size: 16
num_epochs: 2
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:14<00:00, 2.25it/s]
...
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:20<00:00, 1.64it/s]
Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 129.11it/s]
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
Map: 4%|██████▎ | 2231/49942 [00:01<00:37, 1256.31 examples/s]Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 220.24it/s]
...
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
Map: 2%|██▋ | 939/49942 [00:00<00:37, 1323.94 examples/s]Found cached dataset json (/home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 362.77it/s]
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
Loading cached split indices for dataset at /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-d8c5d7ac95d53860.arrow and /home/guodong.li/.cache/huggingface/datasets/json/default-2dab63d15cf49261/0.0.0/fe5dd6ea2639a6df622901539cb550cf8797e5a6b2dd7af1cf934bed8e233e6e/cache-4a34b0c9feb19e72.arrow
{'loss': 2.2798, 'learning_rate': 1.7999999999999997e-05, 'epoch': 0.05}
...
{'loss': 0.853, 'learning_rate': 0.0002006896551724138, 'epoch': 1.02}
{'eval_loss': 0.8590874075889587, 'eval_runtime': 10.5401, 'eval_samples_per_second': 189.752, 'eval_steps_per_second': 3.036, 'epoch': 1.02}
{'loss': 0.8656, 'learning_rate': 0.0001903448275862069, 'epoch': 1.07}
...
{'loss': 0.8462, 'learning_rate': 6.620689655172413e-05, 'epoch': 1.69}
{'loss': 0.8585, 'learning_rate': 4.137931034482758e-06, 'epoch': 1.99}
{'loss': 0.8549, 'learning_rate': 0.00011814432989690721, 'epoch': 2.05}
{'eval_loss': 0.8465630412101746, 'eval_runtime': 10.5273, 'eval_samples_per_second': 189.983, 'eval_steps_per_second': 3.04, 'epoch': 2.05}
{'loss': 0.8492, 'learning_rate': 0.00011195876288659793, 'epoch': 2.1}
...
{'loss': 0.8398, 'learning_rate': 1.2989690721649484e-05, 'epoch': 2.92}
{'loss': 0.8473, 'learning_rate': 6.804123711340206e-06, 'epoch': 2.97}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 585/585 [23:46<00:00, 2.38s/it]
{'train_runtime': 1426.9255, 'train_samples_per_second': 104.999, 'train_steps_per_second': 0.41, 'train_loss': 0.9613736364576552, 'epoch': 2.99}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 585/585 [23:46<00:00, 2.44s/it]
模型文件:
> tree /home/guodong.li/output/lora-alpaca
/home/guodong.li/output/lora-alpaca
├── adapter_config.json
├── adapter_model.bin
└── checkpoint-200
├── optimizer.pt
├── pytorch_model.bin
├── rng_state_0.pth
├── rng_state_1.pth
├── rng_state_2.pth
├── rng_state_3.pth
├── rng_state_4.pth
├── rng_state_5.pth
├── rng_state_6.pth
├── rng_state_7.pth
├── scaler.pt
├── scheduler.pt
├── trainer_state.json
└── training_args.bin
1 directory, 16 files
我们可以看到,在数据并行的情况下,如果epoch=3(本文epoch=2),训练仅需要20分钟左右即可完成。目前,tloen/Alpaca-LoRA-7b提供的最新“官方”的Alpaca-LoRA adapter于 3 月 26 日使用以下超参数进行训练。
- Epochs: 10 (load from best epoch)
- Batch size: 128
- Cutoff length: 512
- Learning rate: 3e-4
- Lora r: 16
- Lora target modules: q_proj, k_proj, v_proj, o_proj
具体命令如下:
python finetune.py \
--base_model='decapoda-research/llama-7b-hf' \
--num_epochs=10 \
--cutoff_len=512 \
--group_by_length \
--output_dir='./lora-alpaca' \
--lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \
--lora_r=16 \
--micro_batch_size=8
模型推理
运行命令如下:
python generate.py \
--load_8bit \
--base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b' \
--lora_weights '/home/guodong.li/output/lora-alpaca'
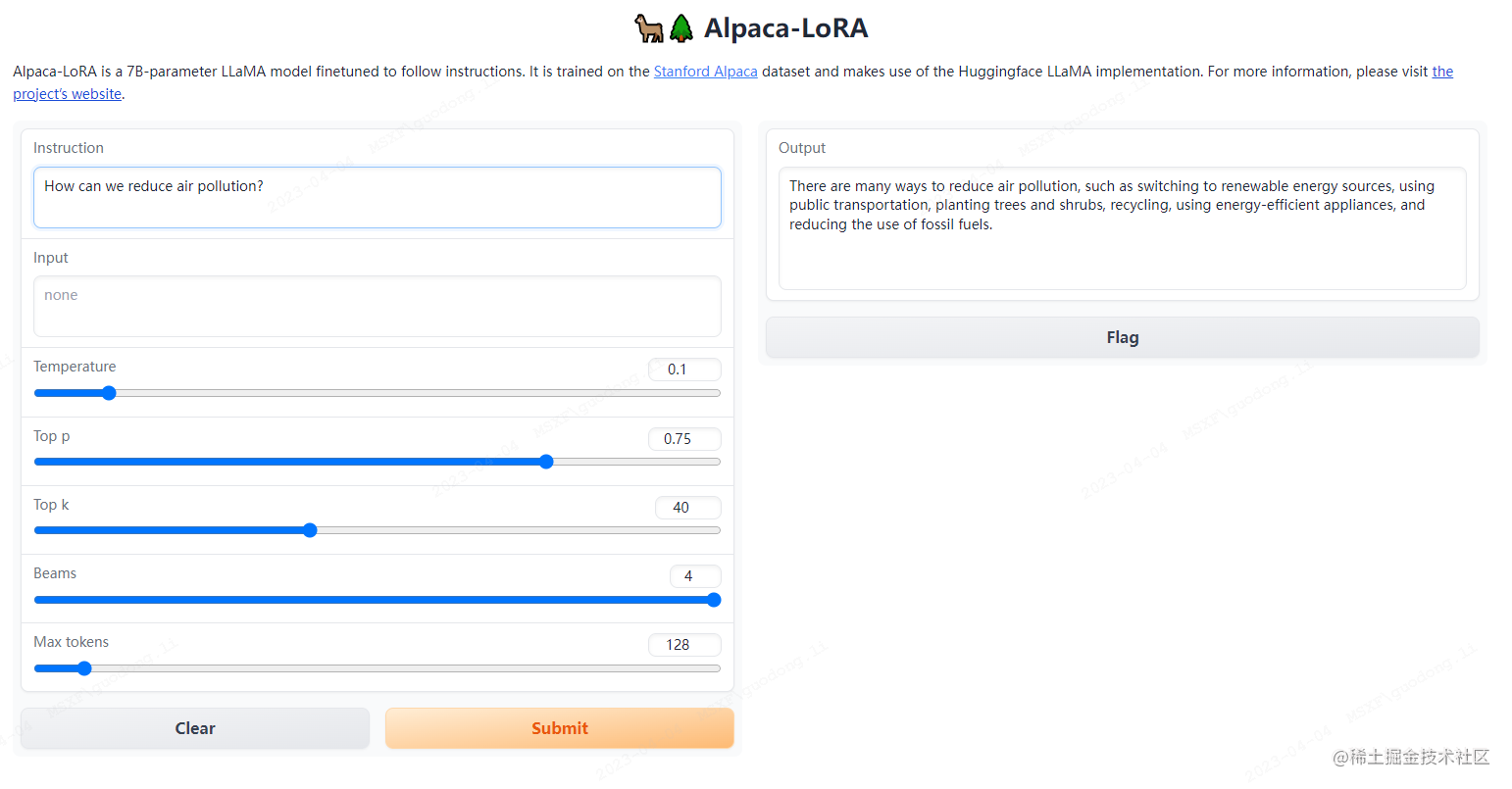
运行这个脚本会启动一个gradio服务,你可以通过浏览器在网页上进行测试。
运行过程如下所示:
python generate.py \
> --load_8bit \
> --base_model '/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b' \
> --lora_weights '/home/guodong.li/output/lora-alpaca'
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:12<00:00, 2.68it/s]
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/gradio/inputs.py:27: UserWarning: Usage of gradio.inputs is deprecated, and will not be supported in the future, please import your component from gradio.components
warnings.warn(
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/gradio/deprecation.py:40: UserWarning: `optional` parameter is deprecated, and it has no effect
warnings.warn(value)
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/gradio/deprecation.py:40: UserWarning: `numeric` parameter is deprecated, and it has no effect
warnings.warn(value)
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
显存占用:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A800 80G... Off | 00000000:34:00.0 Off | 0 |
| N/A 50C P0 81W / 300W | 8877MiB / 81920MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 7837 C python 8875MiB |
+-----------------------------------------------------------------------------+
打开浏览器输入IP+端口进行测试。
将 LoRA 权重合并回基础模型
下面将 LoRA 权重合并回基础模型以导出为 HuggingFace 格式和 PyTorch state_dicts。以帮助想要在 llama.cpp 或 alpaca.cpp 等项目中运行推理的用户。
导出为 HuggingFace 格式:
修改
export_hf_checkpoint.py
文件:
import os
import torch
import transformers
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: F402
BASE_MODEL = os.environ.get("BASE_MODEL", None)
# TODO
LORA_MODEL = os.environ.get("LORA_MODEL", "tloen/alpaca-lora-7b")
HF_CHECKPOINT = os.environ.get("HF_CHECKPOINT", "./hf_ckpt")
assert (
BASE_MODEL
), "Please specify a value for BASE_MODEL environment variable, e.g. `export BASE_MODEL=decapoda-research/llama-7b-hf`" # noqa: E501
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()
lora_model = PeftModel.from_pretrained(
base_model,
# TODO
# "tloen/alpaca-lora-7b",
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
...
# TODO
LlamaForCausalLM.save_pretrained(
base_model, HF_CHECKPOINT , state_dict=deloreanized_sd, max_shard_size="400MB"
)
运行命令:
BASE_MODEL=/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b \
LORA_MODEL=/home/guodong.li/output/lora-alpaca \
HF_CHECKPOINT=/home/guodong.li/output/hf_ckpt \
python export_hf_checkpoint.py
运行过程:
BASE_MODEL=/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b \
> LORA_MODEL=/home/guodong.li/output/lora-alpaca \
> HF_CHECKPOINT=/home/guodong.li/output/hf_ckpt \
> python export_hf_checkpoint.py
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
/home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/cuda_setup/main.py:136: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/opt/rh/devtoolset-7/root/usr/lib/dyninst'), PosixPath('/opt/rh/devtoolset-9/root/usr/lib/dyninst')}
warn(msg)
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.7/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.0
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/guodong.li/virtual-venv/alpara-lora-venv-py310-cu117/lib/python3.10/site-packages/bitsandbytes-0.37.2-py3.10.egg/bitsandbytes/libbitsandbytes_cuda117.so...
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:05<00:00, 5.99it/s]
查看模型输出文件:
> tree /home/guodong.li/output/hf_ckpt
/home/guodong.li/output/hf_ckpt
├── config.json
├── generation_config.json
├── pytorch_model-00001-of-00039.bin
├── pytorch_model-00002-of-00039.bin
...
├── pytorch_model-00038-of-00039.bin
├── pytorch_model-00039-of-00039.bin
└── pytorch_model.bin.index.json
0 directories, 42 files
导出为PyTorch state_dicts:
修改
export_state_dict_checkpoint.py
文件:
import json
import os
import torch
import transformers
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: E402
BASE_MODEL = os.environ.get("BASE_MODEL", None)
LORA_MODEL = os.environ.get("LORA_MODEL", "tloen/alpaca-lora-7b")
PTH_CHECKPOINT_PREFIX = os.environ.get("PTH_CHECKPOINT_PREFIX", "./ckpt")
assert (
BASE_MODEL
), "Please specify a value for BASE_MODEL environment variable, e.g. `export BASE_MODEL=decapoda-research/llama-7b-hf`" # noqa: E501
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
lora_model = PeftModel.from_pretrained(
base_model,
# todo
#"tloen/alpaca-lora-7b",
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
...
os.makedirs(PTH_CHECKPOINT_PREFIX, exist_ok=True)
torch.save(new_state_dict, PTH_CHECKPOINT_PREFIX+"/consolidated.00.pth")
with open(PTH_CHECKPOINT_PREFIX+"/params.json", "w") as f:
json.dump(params, f)
运行命令:
BASE_MODEL=/data/nfs/guodong.li/pretrain/hf-llama-model/llama-7b \
LORA_MODEL=/home/guodong.li/output/lora-alpaca \
PTH_CHECKPOINT_PREFIX=/home/guodong.li/output/ckpt \
python export_state_dict_checkpoint.py
查看模型输出文件:
tree /home/guodong.li/output/ckpt
/home/guodong.li/output/ckpt
├── consolidated.00.pth
└── params.json
当然,你还可以封装为Docker镜像来对训练和推理环境进行隔离。
封装为Docker镜像并进行推理
- 构建Docker镜像:
docker build -t alpaca-lora .
- 运行Docker容器进行推理 (您还可以使用
finetune.py及其上面提供的所有超参数进行训练):
docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${HOME}/.cache:/root/.cache --rm alpaca-lora generate.py \
--load_8bit \
--base_model 'decapoda-research/llama-7b-hf' \
--lora_weights 'tloen/alpaca-lora-7b'
- 打开浏览器,输入URL:
https://localhost:7860进行测试。
结语
从上面可以看到,在一台8卡的A800服务器上面,基于Alpaca-Lora针对
alpaca_data_cleaned.json
指令数据大概20分钟左右即可完成参数高效微调,相对于斯坦福羊驼训练速度显著提升。
参考文档:
- LLaMA
- Stanford Alpaca:斯坦福-羊驼
- Alpaca-LoRA
版权归原作者 李国冬 所有, 如有侵权,请联系我们删除。