YOLOv8 全家桶再迎新成员!新增Pose Estimation模型!
关注公众号,发现CV技术之美不知不觉间,YOLOv8已经发布三个月了,等待中的YOLOv8论文没来,昨天官方默默又加了新模型:姿态估计。说好的"目标检测"工业界标杆,正向着“CV全家桶”阔步向前。现在你可以用YOLOv8做目标检测、实例分割、图像分类、目标跟踪、姿态估计了,也许还有更多惊喜在后面。要
什么是轴向注意力(Axial Attention)机制
注意力机制之 Axial Attention
深入理解深度学习——正则化(Regularization):正则化和欠约束问题
大多数形式的正则化能够保证应用于欠定问题的迭代方法收敛。例如,当似然的斜率等于权重衰减的系数时,权重衰减将阻止梯度下降继续增加权重的大小。是奇异的,这些方法就会失效。当数据生成分布在一些方向上确实没有差异时,或因为例子较少(即相对输入特征的维数来说)而在一些方向上没有观察到方差时,这个矩阵就是奇异的

使用NLPAUG 进行文本数据的扩充增强
数据增强可以通过添加对现有数据进行略微修改的副本或从现有数据中新创建的合成数据来增加数据量。这种数据扩充的方式在CV中十分常见,因为对于图像来说可以使用很多现成的技术,在保证图像信息的情况下进行图像的扩充。
【模型+代码/保姆级教程】使用Pytorch实现手写汉字识别
保姆级教程,手把手用Pytorch搭建神经网络,识别3755类手写汉字,模型参数、项目完整源码、预处理数据集全部公开。
深入浅出PaddlePaddle函数——paddle.zeros
paddle.zeros
深入浅出Pytorch函数——torch.zeros_like
torch.zeros(input.size, dtype=input.dtype,layout=input.layout,device=input.device)
MultiHeadAttention多头注意力机制的原理
MultiHeadAttention多头注意力作为Transformer的核心组件,其主要由多组自注意力组合构成,Attention Is All You Need,self-attention。

谷歌发布一个免费的生成式人工智能课程
谷歌推出了一个生成式人工智能学习课程,课程涵盖了生成式人工智能入门、大型语言模型、图像生成等主题。
用自己网络添加注意力机制后画出热力图
用自己网络添加注意力机制后画出热力图
【人工智能】期末复习 重点知识点总结
人工智能期末复习考点
SAM 模型真的是强悍到可以“分割一切”了吗?
关注公众号,发现CV技术之美上周,Meta AI发布了 Segment Anything Model(SAM)—— 第一个图像分割基础模型。很多计算机视觉从业者惊呼“这下CV真的不存在了,快跑!”。但是SAM 模型真的是强悍到可以“分割一切”了吗?它在哪些场景或任务中还不能较好地驾驭呢?研究社区已经
chatGPT的API一次多少钱-怎么用chatGPT解决问题
使用ChatGPT解决问题一般需要以下几个步骤:确认问题类型:在使用ChatGPT解决问题前,需要明确问题的类型,如文本生成、文本分类、机器翻译、情感分析等。准备数据和模型:ChatGPT需要数据和模型来进行模型训练或模型 fine-tuning。在准备数据时,需要收集相关的数据,并对其进行清洗和处
【tph-yolov5】论文简读
论文名称: TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios论文下载地址:https://arxiv.org/abs/21
深度学习训练文件批量制作——arcgis pro软件(傻瓜式操作)
想要批量制作深度学习训练文件(特别是遥感文件)在网上找了很久的代码或者方法,发现不怎么适用,或者是说太过复杂了(电脑环境、包的版本等一系列问题,博主的环境可以用,到我电脑上我就一堆版本问题,又不好去改代码),于是找了很久发现arcgis pro这个软件可以满足我的要求,批量且简单。
yolov5-7.0训练自己的VOC数据集
这个笔记可能只适用于7.0版本的,写这个笔记主要是给工作室伙伴参考的,大佬请绕行有错误之处欢迎指出。
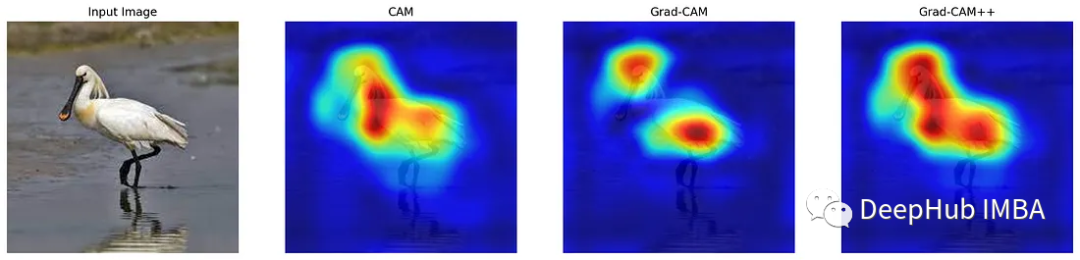
CAM, Grad-CAM, Grad-CAM++可视化CNN方式的代码实现和对比
理解CNN的方法主要有类激活图(Class Activation Maps, CAM)、梯度加权类激活图(Gradient Weighted Class Activation Mapping, Grad-CAM)和优化的 Grad-CAM( Grad-CAM++)。
【代码复现】5秒训练NeRF!英伟达instan-ngp在windows成功复现
主要介绍了在WINDOWS10下运行instant-ngp的方法,并且介绍了自定义数据集创建和运行的方法。
GPU版本的pytorch安装(显卡为3060ti,如何选择对应的cuda版本)
显卡为3060ti g6x,操作系统win10。
yolov8onnx的处理过程
此外,它还存储数据集的变换和大小。n是框的数量,然后对框进行排序(降序),选超参数中设置的max_nms个框,默认为300,最后x仍然是一个(48*6)的tensor,然后对着48个框进行对应类别的conf计算,max=wh表示加入框的大小时对score的影响,最后返回的c是一个(48*1)在xyw



