
之前这篇文章,我分析了一下深度学习中,模型过拟合的主要原因以及解决办法:
过拟合的原因以及解决办法(深度学习)_大黄的博客-CSDN博客
这篇文章中写一下深度学习中,模型欠拟合的原因以及一些常见的解决办法。
也就是为什么我们设计的神经网络它不收敛?
这里还是搬这张图出来,
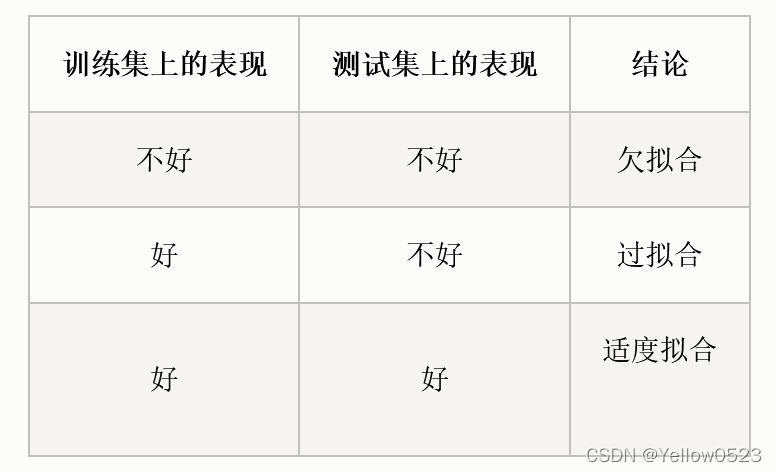
所谓欠拟合(也就是神经网络不收敛),它的表现就是训练集上的性能表现很辣鸡,测试集的表现同样很辣鸡。
一个良好的模型,它应该是训练集上表现很好,测试集上表现也很好的。
下面我列举几种常见的原因以及解决办法:
一.数据未做归一化处理
不同于传统的机器学习模型(比如随机森林,梯度提升回归树等树模型),在神经网络的训练中,对你的数据进行归一化是非常重要且不能省略的步骤。
初学者可能会忽略这个步骤,从而忘记对数据进行归一化。这里我最开始入门的时候也犯了这一错误,导致怎么调模型,它都不收敛,而且性能表现贼差。后来归一化之后,就直接解决了此问题。数据归一化跟不归一化的区别可谓是天壤之别。我们几乎不可能在不进行归一化的前提下可以训练得到一个很好的网络模型这个步骤非常重要,而且在深度学习社区也很有名,所以很少人会提到它,但是对于初学者则是可能会犯下的一个错误。
我们需要对数据进行归一化操作的原因,主要是我们一般假设输入和输出数据都是服从均值为 0,标准差为 1 的正态分布。这种假设在深度学习理论中非常常见,从权重初始化,到激活函数,再到对训练网络的优化算法。
我们常用的归一化方法是**线性函数归一化(Min-Max Scaling)**。它对原始数据进行线性变换,使得结果映射到
[0,1]
的范围,实现对原始数据的等比缩放,公式如下:
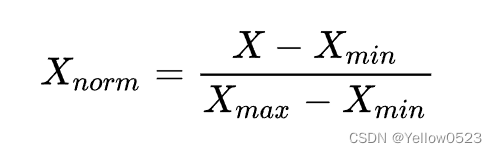
其中 X 是原始数据,Xmax以及Xmin分别表示数据最大值和最小值,Xnorm为归一化后的数值。
二.没有使用任何正则化方法
正则化是现在训练神经网络一个非常重要的方法,通常是以 dropout、噪音或者其他某种随机过程的形式来加入到网络中。即便数据维度比参数更多,或者是在某种情况下不需要在意过拟合或者不可能出现过拟合,加入 dropout 或者某些形式的噪音仍然是很有帮助的。
正则化方法不仅仅是用于控制过拟合,通过在训练过程中引入一些随机过程,在某种程度上是"平滑"了成本格局。这可以加快训练收敛的速度,帮助处理数据中的噪声或异常值,并防止网络的极端权值配置。
最常用的正则化方法就是在卷积层或者全连接层之前采用 dropout 。一般会采用一个较高的概率,比如 0.75 或者 0.9,然后基于网络可能过拟合的概率来调整这个概率值,比如觉得不太可能出现过拟合,那么就把保留神经元的概率设置得非常高,比如 0.99。
数据增强或其他类型的噪音也可以像dropout一样实现正则化,有时候使用了足够的数据增强就可以不用 dropout。通常 dropout 被认为是将许多随机子网络的预测相结合的技术,但也可以将它视为一种数据增强的形式,在训练期间产生许多相似的输入数据变化。正如我们所知,避免过度拟合的最好方法是拥有足够多的数据,使得神经网络永远不会看到同样的数据两次!
最后,像训练神经网络其他方面一样,你需要小心你使用的正则化。请记住,在预测期间将其关闭,并注意,一旦它被关闭,您通常会得到略有不同的结果。在你需要极其精确的数字预测的情况下,某些形式的正则化有时会使这一切变得困难。
三.使用了一个太大的batch size
使用一个太大的batch size会因为降低了梯度下降的随机性,导致降低了网络的准确度。
解决办法:使用较小的batch大小,因为较小的batch大小会产生波动更小,更随机的权重值更新,这有两个好处。
- 首先,在训练的时候它可以有助于“跳出”以前可能会陷入的局部最优值。
- 其次,它可以将训练进入到极小值中,这表示其有更好的泛化能力。
在训练的时候,可以找到一个可以容忍的最小的batch大小。让GPU并行使用最优的batch大小未必得到最好的准确度,因为更大的batch可能需要训练更多时间才能达到相同的准确率。所以建议从一个很小的batch大小开始训练,比如16,8,4甚至是1。
总体而言,重要的是考虑每次迭代中最终梯度更新的平均值,并确保您平衡其不利影响与尽可能多地使用 GPU 潜在并行性的必要性。
四.使用了一个错误的学习率
学习率对训练网络的容易程度以及准确度有很大的影响。而学习率的设置往往比较困难,幸运的是,常见的深度学习框架中已经提供好了学习率的默认选项。
许多深度学习框架在默认情况下启用梯度裁剪。这个操作是通过在训练中的每一步中改变一个最大数量的权值来防止出现梯度爆炸的情况。这可能很有用——特别是当你的数据包含许多异常值,这会产生很大的误差,从而产生很大的梯度和权重更新,但默认设置也会使手工找到最佳学习率变得非常困难。我发现大多数刚接触深度学习的人都将学习速率设置得过高,并通过梯度裁剪来解释这一点,使整体训练速度变慢,并且改变学习率的效果不可预测。
解决办法:不采用梯度裁剪。找出在训练过程中不会导致误差爆炸的最大学习率。将学习率设置为比这个低一个数量级,这可能是非常接近最佳学习率。如果你已经正确地清理了你的数据,删除了大部分的异常值,并正确地设置了学习速率,那么你真的不应该需要梯度剪裁。如果没有它,你会发现你的训练误差偶尔变得非常大,那么请使用梯度裁剪,但是请记住,看到你的训练错误爆发几乎总是表明你的一些数据有其他错误,梯度裁剪只是一个临时措施。
五.在最后一层使用错误的激活函数
在最后一层使用激活函数有时候会导致网络不能生成要求数值的完整范围,比如最常见的错误就是在最后一层采用 ReLU ,它会导致网络只能输出正数。
想想你模型的输出值是什么,最有可能的情况是,你的输出值是无限的正数或负数(回归任务),在这种情况下,不应该在最后一层使用激活功能。
如果输出值可能只在某个范围内有意义,例如它由范围 0-1 中的概率组成,则很可能在最后一层(如 sigmoid 激活功能)上应使用特定的激活功能(分类任务)。
一般来说,对于回归任务,在最后一层不应该使用任何激活功能。
六. 使用了一个太深的神经网络
网络是越深越好吗?实际上并总是这样的,越深越好一般是在做基准实验或者是希望在某些任务上尝试增加 1%甚至更多的准确率。但是如果 3,4,5 层的网络都学不到任何东西,那么使用 100+的网络层也会同样失败, 甚至更加糟糕。
虽然看起来是这样,但神经网络并不是在某人决定堆叠数百层的时候就突然开始获得突破性的结果的。过去十年里对神经网络所做的所有改进都是微小的、根本性的改变,这些改变既适用于深度网络,也适用于小型网络。如果你的网络不工作,更有可能是其他问题,而不是网络的深度问题。
解决办法:从一个2到8层的神经网络开始。只有当训练的网络有不错的性能,并开始研究如何提高准确性时,才开始尝试更深层次的网络。
从小处开始也意味着训练你的网络会更快,推理会更快,迭代不同的设计和设置会更快。最初,所有这些东西对网络的准确性的影响要比简单地堆叠更多的网络层大得多。
七. 隐藏层神经元的数量设置不正确
在某些情况下,使用过多或过少的隐藏神经元会让网络难以训练。
- 神经元数量过少,它可能无法表达所需的任务,模型需要迭代的次数会更多;
- 而神经元数量过多,它可能变得缓慢而笨拙,每次训练所花费的时间变长,难以去除残余噪声进行训练。
在决定要使用的隐藏神经元的数量时,关键是要大致考虑你认为表达你希望通过网络传递的信息所需的实际值的最少数量。然后你应该把这个数字放大一点。这将允许 dropout,以便网络使用更冗余的表示,并在你的估计中有一点余地。
如果你在做分类,你可能会使用类数量的5到10倍作为一个好的初始猜测,而如果你在做回归,你可能会使用输入或输出变量数量的 2 到 3 倍。当然,所有这些都高度依赖于环境,并且不存在简单的自动解决方案,良好的直觉仍然是决定隐藏层神经元数量的最重要因素。
从256到1024个隐藏神经元数量开始。然后,看看其他研究人员在相似应用上使用的数字,并以此为灵感。如果其他研究人员使用的数字与上面给出的数字有很大不同,那么可能有一些具体的原因,这可能对你来说很重要。
在现实中,与其他因素相比,隐藏神经元的数量往往对神经网络的性能有相当小的影响,在很多情况下,高估所需的隐藏神经元的数量只会使训练变慢,而没有什么负面影响。一旦网络开始工作,如果你仍然担心,就尝试一大堆不同的数字,并测量其准确性,直到找到最有效的一个。
版权归原作者 Yellow0523 所有, 如有侵权,请联系我们删除。