
全文参考:论文阅读笔记:Masked Autoencoders Are Scalable Vision Learners_塔_Tass的博客-CSDN博客
masked autoencoders(MAE)是hekaiming大佬又一新作,其做法很简单,就是随机mask掉一部分patches并重建这部分丢失的像素,可看作是一个可扩展的(scalable)自监督学习器,能极大加速模型的训练速度并提升准确率。下游迁移性能优于有监督预训练,并有良好的的scaling(可扩展性)。
一、介绍
mask autoencoders是一种更一般的去噪方式。
语言的信息密度更高,mask掉部分文字可能使得语义完全不同,这个任务会导致更复杂的语言理解;而图像的冗余度就很高,因此mask掉部分patch,大大减少冗余信息。并创建一个很有挑战性的自监督创建任务,提升对图像的整体理解。
AE的decoder将潜在表示映射回输出,相比于语言的重建,图像像素的重建,语义级别更低。decoder往往仅需要轻量级即可,比编码器更浅更窄。但我们发现,对于图像,decoder的设计很大程度上影响着潜在表示的语义表达水平。
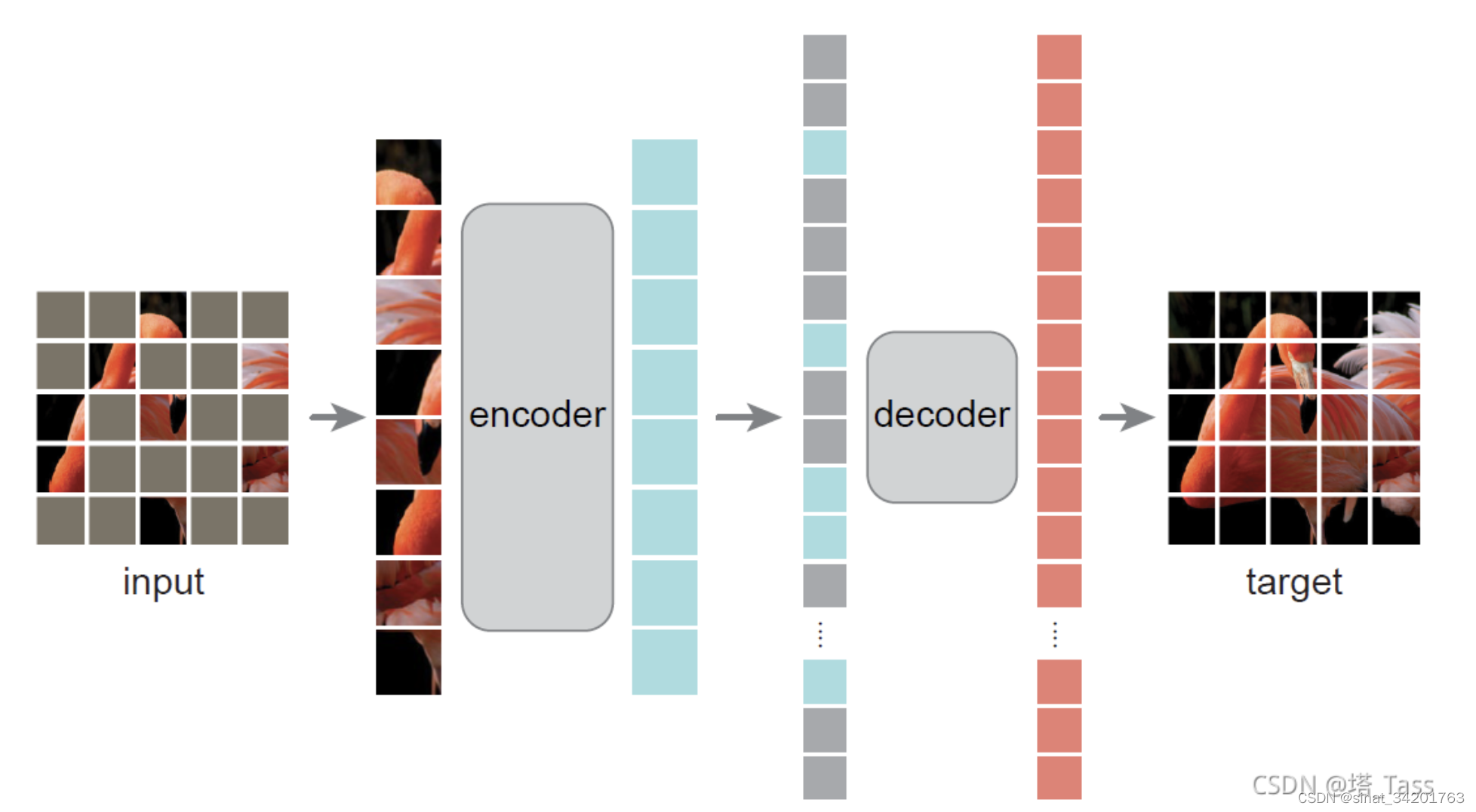
二、网络结构
我们设计的是非对称的encoder decoder,encoder仅在未被mask的patch上进行编码,生成潜在表示,decoder再基于潜在表示和被mask的patch一起重建。
1. encoder
这里,encoder对于被mask的patch,并不是用0填充,而是直接忽略,因此patch数量的减少,能直接降低计算量,加快训练速度(75%的mask率就相当于加速3倍),且降低了内存消耗使得可以用更大模型。
2. decoder
而decoder仅在预训练阶段进行重构任务(即在下游任务finetune的时候是不需要decoder的),因此decoder的设计可以灵活。
encoder的加深有利于潜在表示能表达更抽象的语义信息,而decoder可以设计的更浅更窄,我们使用单个的transfomer这种小型解码器也可以表现出色,且速度快。
3. LOSS
我们使用原始图像与重构图像在mask patch部分的MSE损失(均方误差)。一个变体是,用每个patch的mean std进行归一化后,计算每一个patch的归一化像素的MSE,这个可以明显提高表示质量。
三、实验
(与有监督/无监督的预训练方法进行比较)
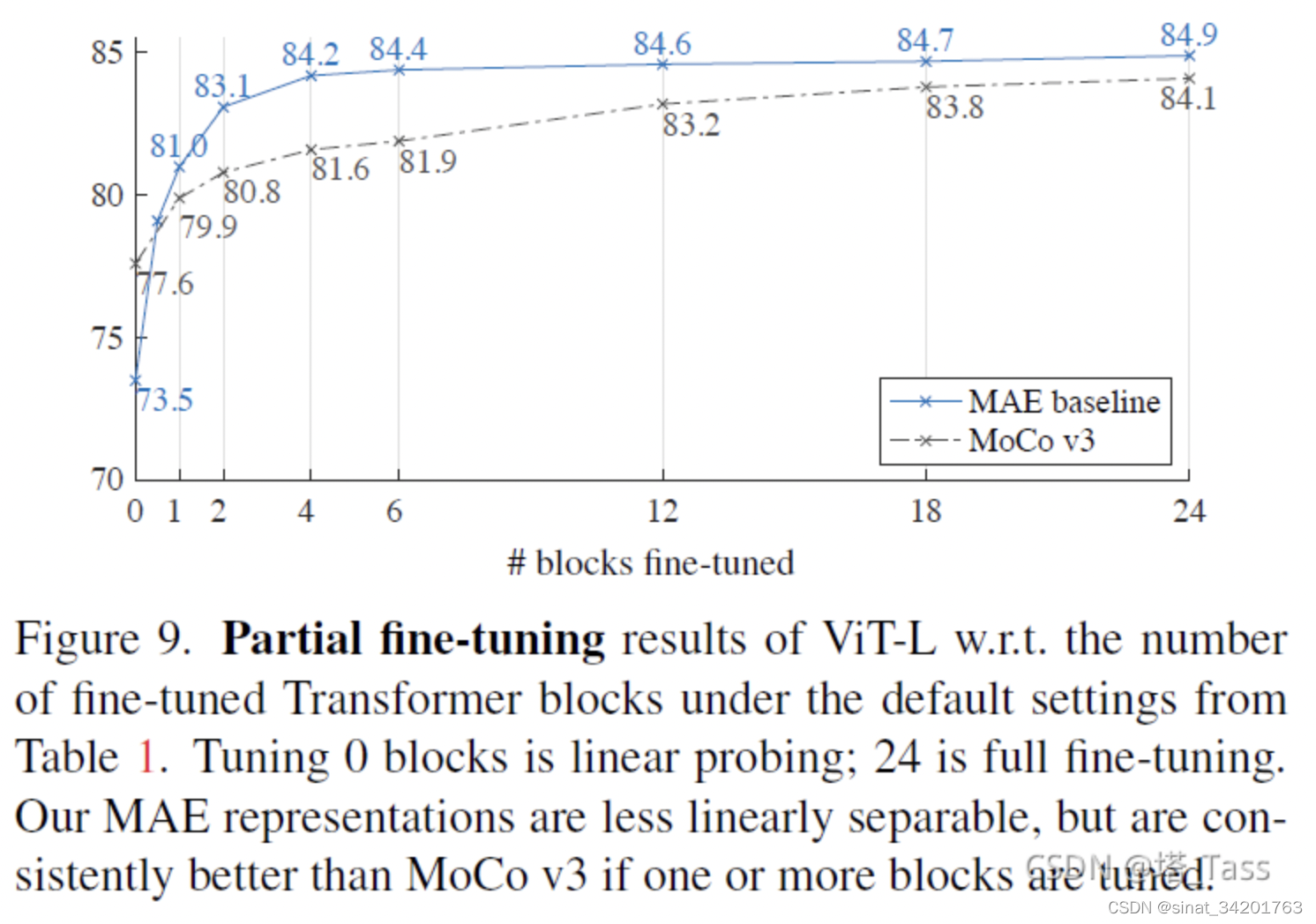
1)比MOCOv3的预训练finetune效果更好
2)在目标检测任务中,ViT与FPN搭配更好,与有监督的预训练相比,MAE要更优。
自己的总结:MAE是一种很好的自监督训练器,其训练的预训练模型,比有监督的、MOCO自监督的,在下游任务finetune上都取得更好的效果
版权归原作者 小白在进步 所有, 如有侵权,请联系我们删除。