nerfstudio安装
nerfstudio安装
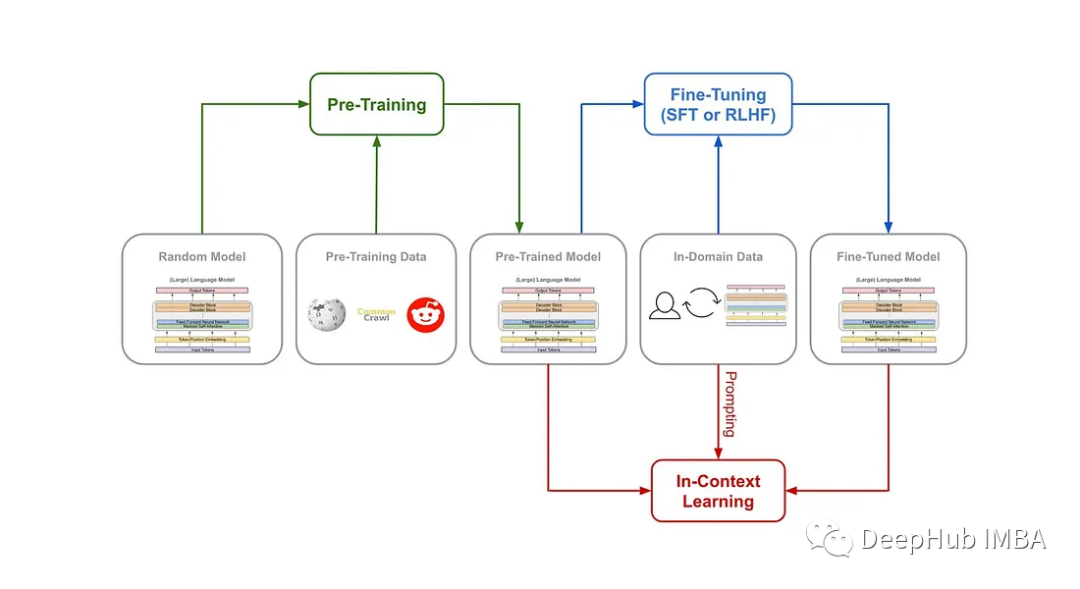
预训练、微调和上下文学习
最近语言模型在自然语言理解和生成方面取得了显著进展。这些模型通过预训练、微调和上下文学习的组合来学习。在本文中将深入研究这三种主要方法,了解它们之间的差异,并探讨它们如何有助于语言模型的学习过程。
深入浅出Pytorch函数——torch.full_like
torch.full_like(input, fill_value, \*, dtype=None, layout=torch.strided, device=None, requires_grad=False, memory_format=torch.preserve_format) → Tens
堆叠式自动编码器(SAE)--学习笔记
堆叠式自动编码器(SAE)--学习笔记
最新版本 Stable Diffusion 开源 AI 绘画工具之 ControlNet 篇
让AI绘画向生产力工具进步的神级工具
【杂物间3】AI,ML,RL,DL,NLP,CV…搞清了这些是啥
一文搞清(for me)AI-ML-RL-DL-NLP/CV/GNN之间的关系。
有关于pytorch单精度bfloat16位
BF16是brain float的简称(来源于google brain)。不同于普通的单精度浮点数FP16(i.e., torch.float16),BF16是介于FP16和FP32之间的一种浮点数格式。BF16的指数位比FP16多,跟FP32一样,不过小数位比较少。即,BF16尝试采用牺牲精度的方
ChatGPT对未来编程语言发展的影响与展望
ChatGPT是一种基于自然语言处理技术的语言模型,由美国OpenAI团队研发。它是构建在生成式预训练变换模型(Generative Pre-trained Transformer,简称GPT)之上,具有强大的自然语言理解和生成能力。GPT模型以大规模文本数据为输入进行训练,从而学习到了丰富的语言知
通俗解释EMA
EMA,全称是指数移动平均,是一种给予近期数据更高权重的平均方法,详细的介绍可以参考:深度学习: 指数加权平均。 深度学习中常见的Adam、RMSProp和Momentum等优化算法内部都使用了EMA,由于使用了EMA这些算法常被称为自适应优化算法,可以随着训练过程的推移,自适应的调整参数的优
【论文合集】Awesome Anomaly Detection
Anomaly Detection: The process of detectingdata instances that significantly deviate from the majority of the whole dataset.
目标检测算法——YOLOv5/YOLOv7改进之结合GAMAttention
论文题目:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions作者设计一种减少信息缩减并放大全局维度交互特征的机制,采用了CBAM中的顺序通道-空间注意机制,并对子模块进行了重新设

漫画风格迁移神器 AnimeGANv2:快速生成你的漫画形象
趁着有空的时间,给大家介绍一些有趣的项目吧,比如这个漫画风格迁移神器 AnimeGANv2,可以快速生成自己的漫画形象
目标检测算法——YOLOv5/YOLOv7改进之结合MobileOne结构(高性能骨干|仅需1ms)
目标检测算法——YOLOv5/YOLOv7改进之结合MobileOne结构。移动端仅需1ms的高性能骨干!
Yolov5口罩佩戴实时检测项目(模型剪枝+opencv+python推理)
yolov5口罩佩戴实时检测项目
Nerf系列数据集记录
nerf系列数据集记录
【MMDetection】——训练个人数据集
mmdetection训练自己的数据集,全过程记录。
ACE2005数据集介绍、预处理及事件抽取
ACE2005数据集的介绍、中英文的预处理以及事件抽取的样例参考
【Stable Diffusion】基本概念之lora
使用lora可以提取画面中的任何特征,进而生成任意的画风、动作、表情等,非常方便、好用
【网络结构设计】11、E-LAN | 通过梯度传输路径来设计网络结构
本文主要介绍 E-LAN



