
在这篇博客中,主要是收集到一些图像融合框架中引入Transformer结构的文章,提供给大家参考学习,目前图像融合领域引入Transformer结构的文章比较少(我所看到的比较少,也看可能我看的比较少?),主要作用就是把它作为一种提取特征的方式,或者说更倾向于long-range dependencies的建立。Transformer引入到图像融合领域的时间并不长,大部分文章都是2020-2022发出的,所有并没有统计发表年份。至于是具体是哪个会议或者期刊发表的并没有标注,有兴趣可以自己去查查。
Transformer 主要是通过自注意力学习图像斑块之间的全局空间关系。 自注意力机制致力于建立long-range dependencies,从而在浅层和深层中更好地利用全局信息,所以 Transformer 的使用就是解决长序列问题的一个好方法。在 CV 领域中常用的就是 CNN,它可以提取本地的特征,因为每次卷积就是提取该卷积下的特征图,在局部信息的提取上有很大优势,但无法关注图像的长期依赖关系,阻碍了复杂场景融合的上下文信息提取。所以, Transformer 的引入主要解决这个问题。
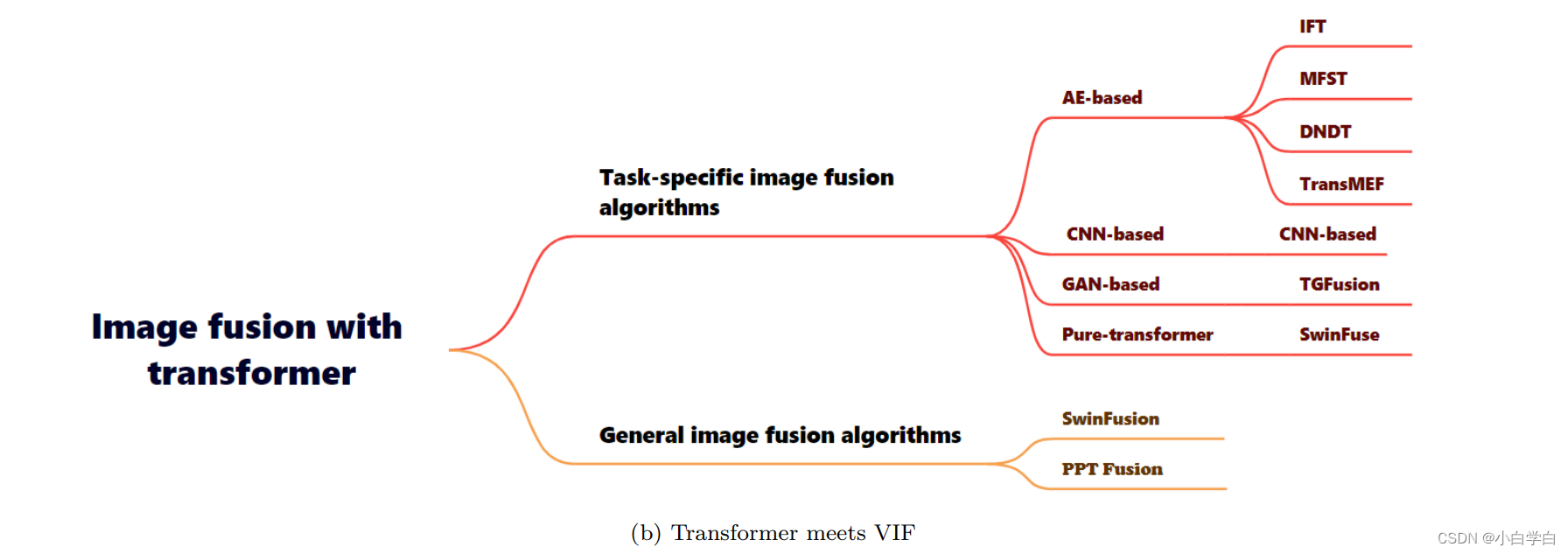
下面这个思维导图从单任务和多任务的角度进行设计的,简单看看吧!!!
下面这个表格是论文的名称,以及在网络结构上进行了总结。
CNN+Transformer结构文章类型代码Image Fusion TransformerVIF文中提供了代码链接MFST: Multi-Modal Feature Self-Adaptive Transformer for Infrared and Visible Image FusionVIFDNDT: Infrared and Visible Image Fusion Via DenseNet and Dual-TransformerVIFTransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task LearningMEF
文中提供了代码链接
TransFuse: A Unified Transformer-based Image Fusion Framework using Self-supervised Learning
Unified Framework
文中提供了代码链接TGFuse: An Infrared and Visible Image Fusion Approach Based on Transformer and Generative Adversarial NetworkVIFSwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin TransformerUnified Framework文中提供了代码链接CGTF: Convolution-Guided Transformer for Infrared and Visible Image FusionVIFPure Transformer结构(这两篇都是预训练模型做的)SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible ImagesVIF文中提供了代码链接PPT Fusion: Pyramid Patch Transformer for a Case Study in Image FusionUnified Framework新增THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractorVIFIFormerFusion: Cross-Domain Frequency Information Learning for Infrared and Visible Image Fusion Based on the Inception TransformerVIFBreaking Free from Fusion Rule: A Fully Semantic-driven Infrared and Visible Image FusionVIF扩散模型Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion ModelsVIF,扩散彩色通道特征
上述论文的实验部分都是比较的卷积方法或者传统方法,并没有比较到使用到Transforme的模型,所以他们之间的是啥情况,那就不清楚了,没刻意去比较过,有兴趣可以去比较比较。**That thing is not sure!!!**
** 思考:怎么把Tranformer合理的引入**到CNN结构中进行图像融合以及如何真正地将Transformer用到图像融合融合中(完全使用Transformer去构建图像融合模型) ???
目前,只收集到这些文章。。如有错误,希望大家看到后及时在评论区留言!!!
另外,如果想更多的关注图像融合领域相关的知识,大家可以关注以下优秀的博主:
1:部分基于深度学习的红外与可见光图像融合模型总结 - 知乎 (zhihu.com)
2:(7条消息) 红外和可见光图像融合论文及代码整理_Timer-419的博客-CSDN博客_图像融合论文
希望对大家有帮助,欢迎大家补充!!!
2023.3.17新增、扩散模型!!!
版权归原作者 小白学白 所有, 如有侵权,请联系我们删除。