one-hot编码
one-hot编码,又称独热编码、一位有效编码。one hot在特征提取上属于词袋模型(bag of words)优缺点分析优点:- 一是解决了分类器不好处理离散数据的问题- 二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)缺点:- 它是一个词袋模型,不考虑词与词之间的顺序-
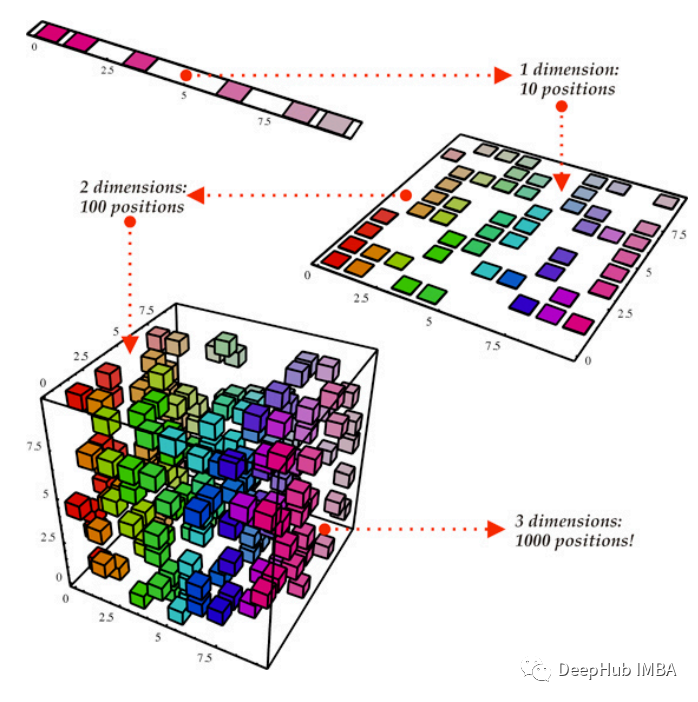
常见的降维技术比较:能否在不丢失信息的情况下降低数据维度
本文将比较各种降维技术在机器学习任务中对表格数据的有效性。
【2022】保姆级Anaconda安装与换国内源教程
一、Anaconda的安装由于Anaconda官网在境外,为了提升下载速度,我们选择从北京外国语大学镜像站下载Anaconda的安装包。Index of /anaconda/archive/ | 北京外国语大学开源软件镜像站 | BFSU Open Source Mirrorhttps://mirr

2022年最有开创性的10篇AI论文总结
本文我们总结了在2022年发表的最具开创性的10篇论文,无论如何你都应该看看。

PyTorch 2.0 推理速度测试:与 TensorRT 、ONNX Runtime 进行对比
PyTorch 2.0 于 2022 年 12 月上旬在 NeurIPS 2022 上发布,它新增的 torch.compile 组件引起了广泛关注,因为该组件声称比 PyTorch 的先前版本带来更大的计算速度提升。
机器学习深度神经网络——实验报告
机器学习实验报告6:深度神经网络

Pandas处理大数据的性能优化技巧
Pandas是Python中最著名的数据分析工具。本文将介绍一些使用Pandas处理大数据时的技巧,希望对你有所帮助
YOLOv3&YOLOv5输出结果说明
本文使用的yolov3和yolov5工程文件均为github上ultralytics基于pytorch的v3和v5代码,其训练集输出结果类型基本一致,主要介绍了其输出结果,本文是一篇学习笔记本文使用的yolov3代码github下载地址:yolov3模型训练具体步骤可查看此篇博客:yolov3模型训
Python 实现朴素贝叶斯代码演示
朴素贝叶斯可以细分为三种方法:分别是伯努利朴素贝叶斯、高斯朴素贝叶斯和多项式朴素贝叶斯。下文就这三种方法进行详细讲解和演示。目录一、伯努利朴素贝叶斯方法1.1 例子解答1.1.1 代码:1.1.2 结果:二、高斯朴素贝叶斯方法2.1 解题2.1.1 代码:2.1.2 结果:2.2 检查高斯朴素贝叶斯
机器学习实战练手项目
机器学习是一种从数据生成规则、发现模型,来帮助我们预测、判断、分析和解决问题的技术。一个机器学习项目从开始到结束大致分为5步,分别是定义问题、收集数据和预处理、选择算法和确定模型、训练拟合模型、评估并优化模型性能。......
深度学习系列37:CLIP模型
含义:CLIP(Contrastive Language-Image Pre-training)git地址:https://github.com/openai/CLIPpaper:https://arxiv.org/abs/2103.00020安装:pip install git+https://g
推荐系统笔记(十):InfoNCE Loss 损失函数
InfoNCELoss是为了将N个样本分到K个类中,K
4大类11种常见的时间序列预测方法总结和代码示例
本篇文章将总结时间序列预测方法,并将所有方法分类介绍并提供相应的python代码示例,以下是本文将要介绍的方法列表:1、使用平滑技术进行时间序列预测指数平滑Holt-Winters 法2、单变量时间序列预测自回归 (AR)移动平均模型 (MA)自回归滑动平均模型 (ARMA)差分整合移动平均自回归模
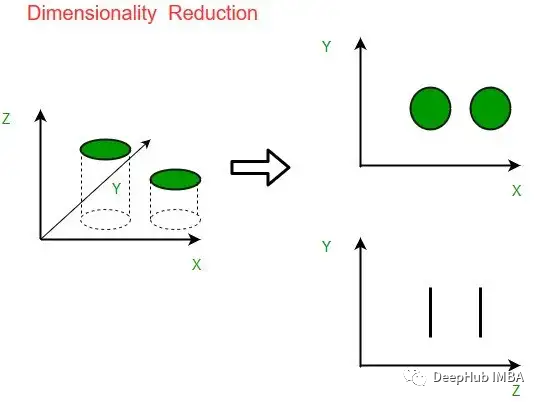
降维和特征选择的对比介绍
在machine learning中,特征降维和特征选择是两个常见的概念,在应用machine learning来解决问题的论文中经常会出现。特征降维和特征选择的目的都是使数据的维数降低,使数据维度降小。但实际上两者的区别是很大,他们的本质是完全不同的。
【seaborn】sns.set() 绘图风格设置
从这个set()函数,可以看出,通过它我们可以设置背景色、风格、字型、字体等。我们定义一个函数,这个函数主要是生成100个0到15的变量,然后用这个变量画出6条曲线。那么,问题来了,有人会说,这个set()函数这么多参数,只要改变其中任意一个参数的值,绘图效果就会发生变化,那我们怎么知道哪种搭配是最
2022 CCF BDCI 返乡发展人群预测 [0.9117+]
返乡发展人群预测:基于中国联通的大数据能力,通过使用对联通的信令数据、通话数据、互联网行为等数据进行建模,对个人是否会返乡工作进行判断A榜的结果为0.91171720。
新冠疫情预测模型--逻辑斯蒂回归拟合、SEIR模型
通过构建统计学模型、数学模型,或者利用机器学习、深度学习方法拟合疫情发展趋势,利用历史数据对未来的确诊病例等疫情形势进行预测,比如说,逻辑斯蒂生长曲线拟合数据,预测未来几天可能的发展趋势;或者利用时间序列模型构建预测模型;也可用LSTM构建预测模型,一种特殊的RNN网络。以上方法,除生长曲线外,
机器学习实战3:基于朴素贝叶斯实现单词拼写修正器(附Python代码)
本文基于朴素贝叶斯原理实现一个有趣的应用——单词拼写修正器,并梳理一些贝叶斯公式中的细节加深理解,最后给出python代码
自动驾驶入门必须要学会的ADAS(详解)
ADS分类详解
PCA降维原理 操作步骤与优缺点
PCA全称是Principal Component Analysis,即主成分分析。它主要是以“提取出特征的主要成分”这一方式来实现降维的。 介绍PCA的大体思想,先抛开一些原理公式,如上图所示,原来是三维的数据,通过分析找出两个主成分PC1和PC2,那么直接在这两个主成分的方向上就可以形成一个平面



