
一般情况下k-Nearest Neighbor (KNN)都是用来解决分类的问题,其实KNN是一种可以应用于数据分类和预测的简单算法,本文中我们将它与简单的线性回归进行比较。
KNN模型是一个简单的模型,可以用于回归和分类任务。大部分的机器学习算法都是用它的名字来描述的KNN也是一样,使用一个空间来表示邻居的度量,度量空间根据集合成员的特征定义它们之间的距离。对于每个测试实例,使用邻域来估计响应变量的值。估计可以使用最多k个邻域来进行,超参数控制算法的学习方式;它们不是根据训练数据估计出来的,而是基于一些距离函数选择的最近的k个邻居。
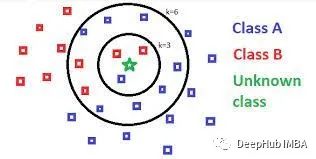
在本文中,我们将重点介绍二元分类,为了防止平局k通常设置为奇数。与分类任务不同,在回归任务中,特征向量与实值标量而不是标签相关联,KNN是通过对响应变量均值或加权均值来进行预测。
惰性学习和非参数模型
惰性学习是 KNN 的标志。惰性学习器,也称为基于实例的学习器,这种学习器很少或根本不处理训练数据。与线性回归等积极学习的算法不同,KNN 不会估计在训练阶段概括训练数据的模型的参数。惰性学习有利有弊,训练一个积极学习的成本可能很高,但使用生成的模型进行预测的成本少。通过将系数乘以特征并添加偏置参数就可以预测简单的结果,计算成本低,预测速度快。但是一个惰性的学习者做出预测的成本是很高的,因为KNN 预测需要在计算测试实例和训练实例之间的距离,也就是要访问所有的训练数据。
参数模型使用固定数量的参数或系数来汇总数据。无论使用多少个训练实例,参数的数量都保持不变。非参数可能看起来用词不当,因为它并不意味着模型没有参数;相反,它意味着参数的数量随着训练数据的数量而变化。
当不熟悉响应变量和解释变量之间的关系时,非参数模型可能会很有用。KNN 就是这种非参数模型,如果实例彼此接近,则响应变量可能具有相似的值。当训练数据稀缺或已经知道这种关系时,带有假设的模型可能会比非参数模型有用。
使用 KNN 进行分类
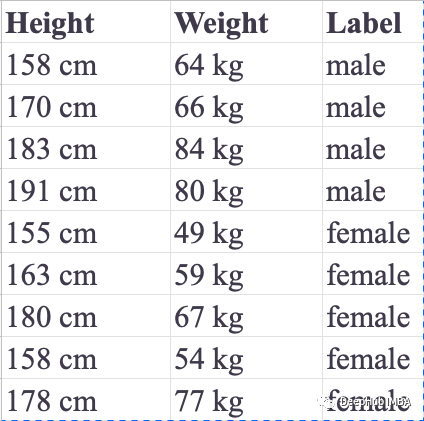
我们使用一个简单的问题作为,我们需要根据一个人的身高和体重来预测他或她的性别的情况。这里有两个标签可以分配给响应变量,这就是为什么这个问题被称为二元分类。下表记录了九个训练实例:
KNN可以使用的特征没有数量限制,但不能可视化三个以上的特征(这是因为我们生活在3维空间,无法可视化更多维的数据)。通过创建散点图,可以使用matplotlib可视化数据:
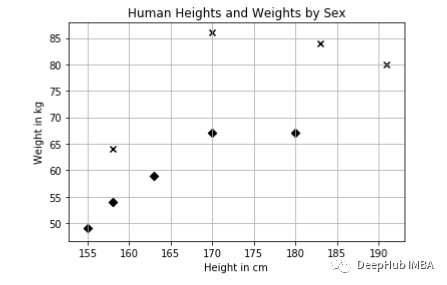
从图中可以看到,男性往往比女性更高更重,这一点由x标记所示。我们的经验也与这个观察结果一致。要根据一个人的身高和体重来预测他/她的性别。需要定义距离测量指标:我们将测量两点之间的欧氏距离。在二维空间中,计算欧氏距离如下:
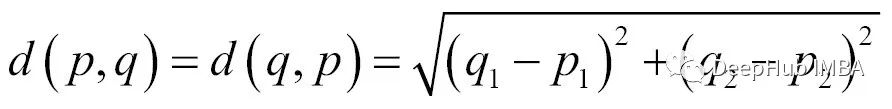
下一步是计算查询实例和所有训练实例之间的距离:

将k设置为3,我们将选择三个最近的实例来进行预测。在下面的脚本中,计算测试和训练实例之间的距离,并确定每个邻居的最常见性别:
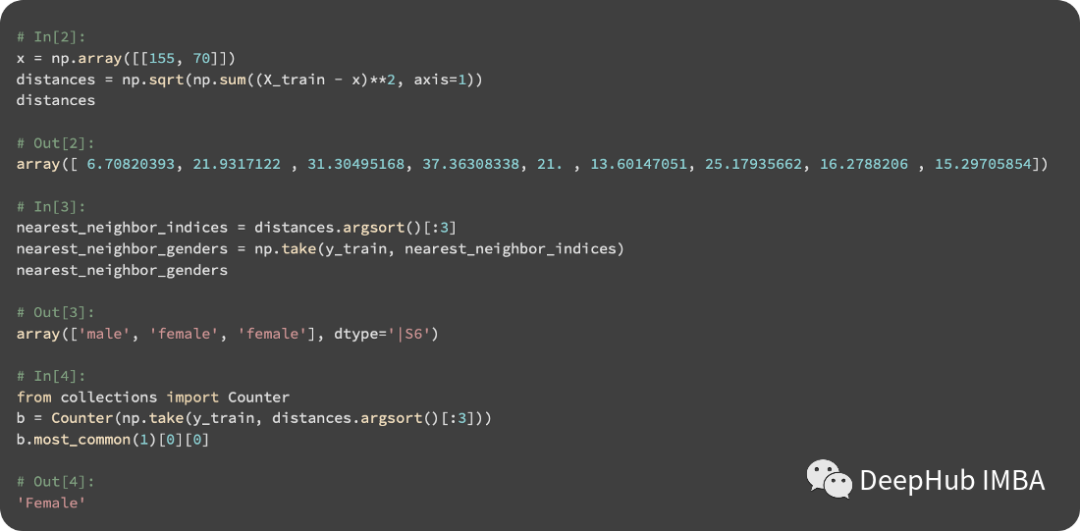
在下面的图中,圆圈表示查询实例,放大的标记表示它最近的三个邻居:
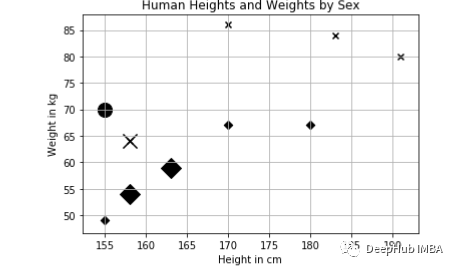
有两个女性邻居和一个性男邻居。所以我们测试实例的结果是女性。使用scikit-learn实现KNN分类器,代码如下:
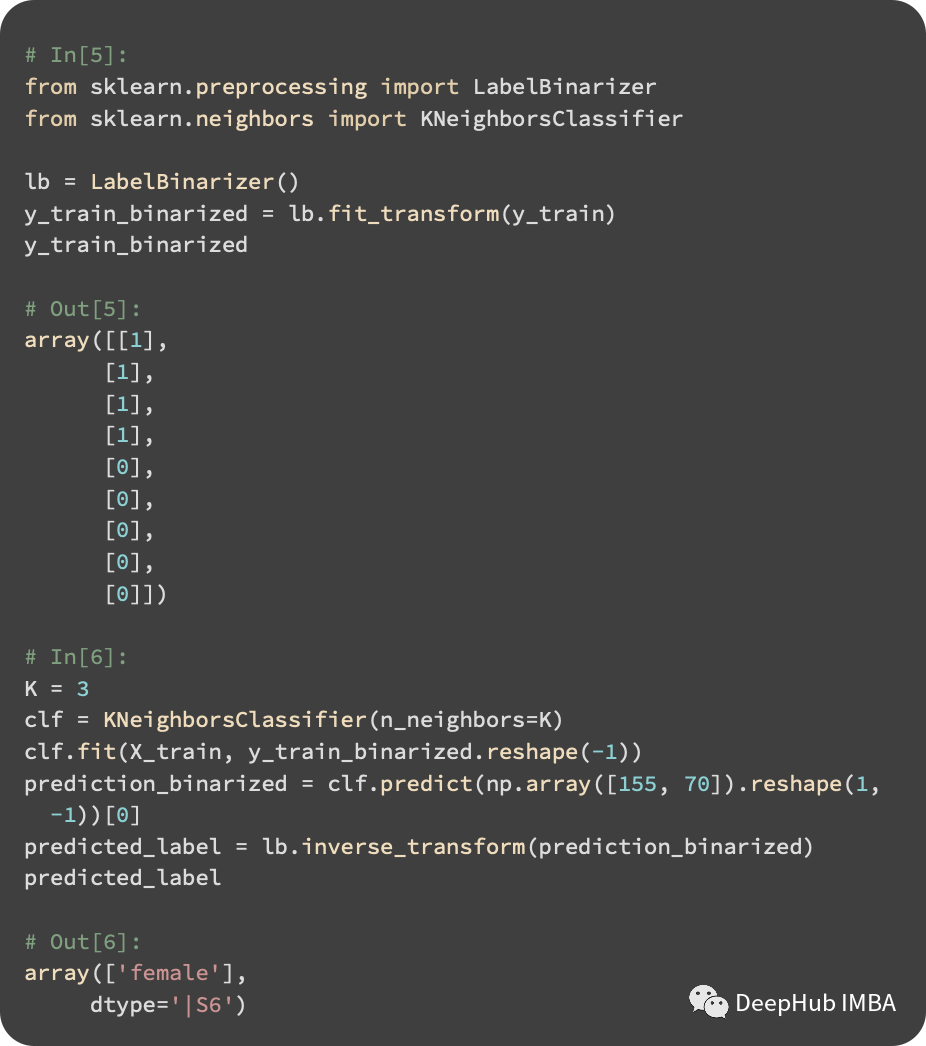
LabelBinarizer先将字符串转换为整数,fit方法创建了从标签字符串到整数的映射。输入标签使用transform方法进行转换。fit_transform同时调用fit和transform作。同时如果训练集和测试集是独立转换的,那么在训练集中男性可能映射为1,而在测试集中则映射为0。所以我们使用训练集的对象进行fit。然后使用KNeighborsClassifier进行预测。
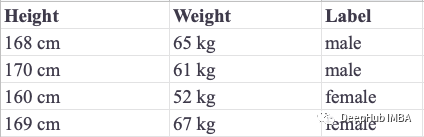
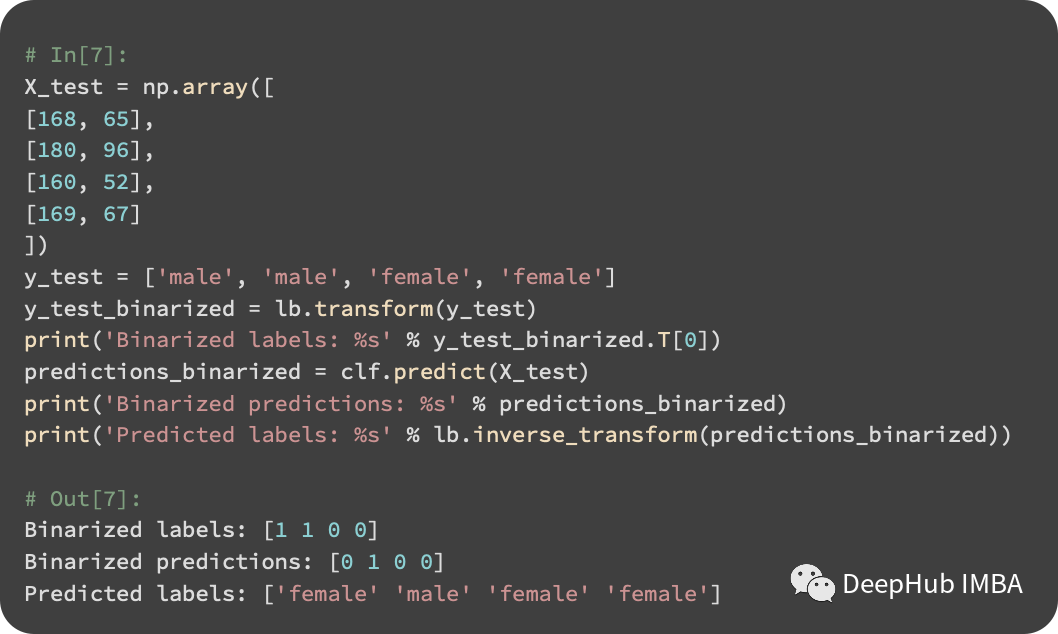
通过将我们的测试标签与分类器的预测进行比较,我们发现一个男性测试实例被错误地预测为女性。所以我们的准确率为75%:

使用 KNN 进行回归
KNN 也可以执行回归分析。让我们使用他们的身高和性别来预测他的体重。我们在下表中列出了我们的训练和测试集:
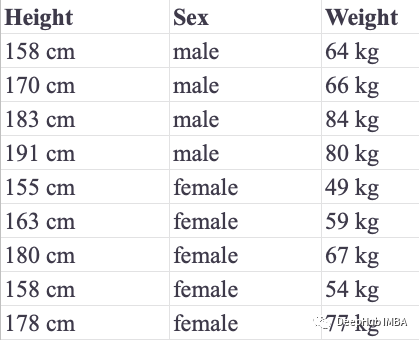
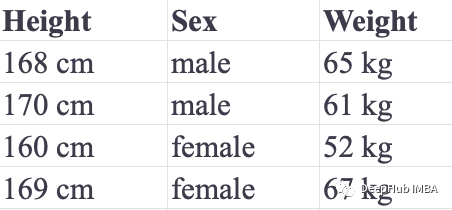
使用KNeighborsRegressor,我们可以进行回归的任务。这里作为回归任务的两个性能度量是:平均绝对误差(MAE)和均方误差(MSE):
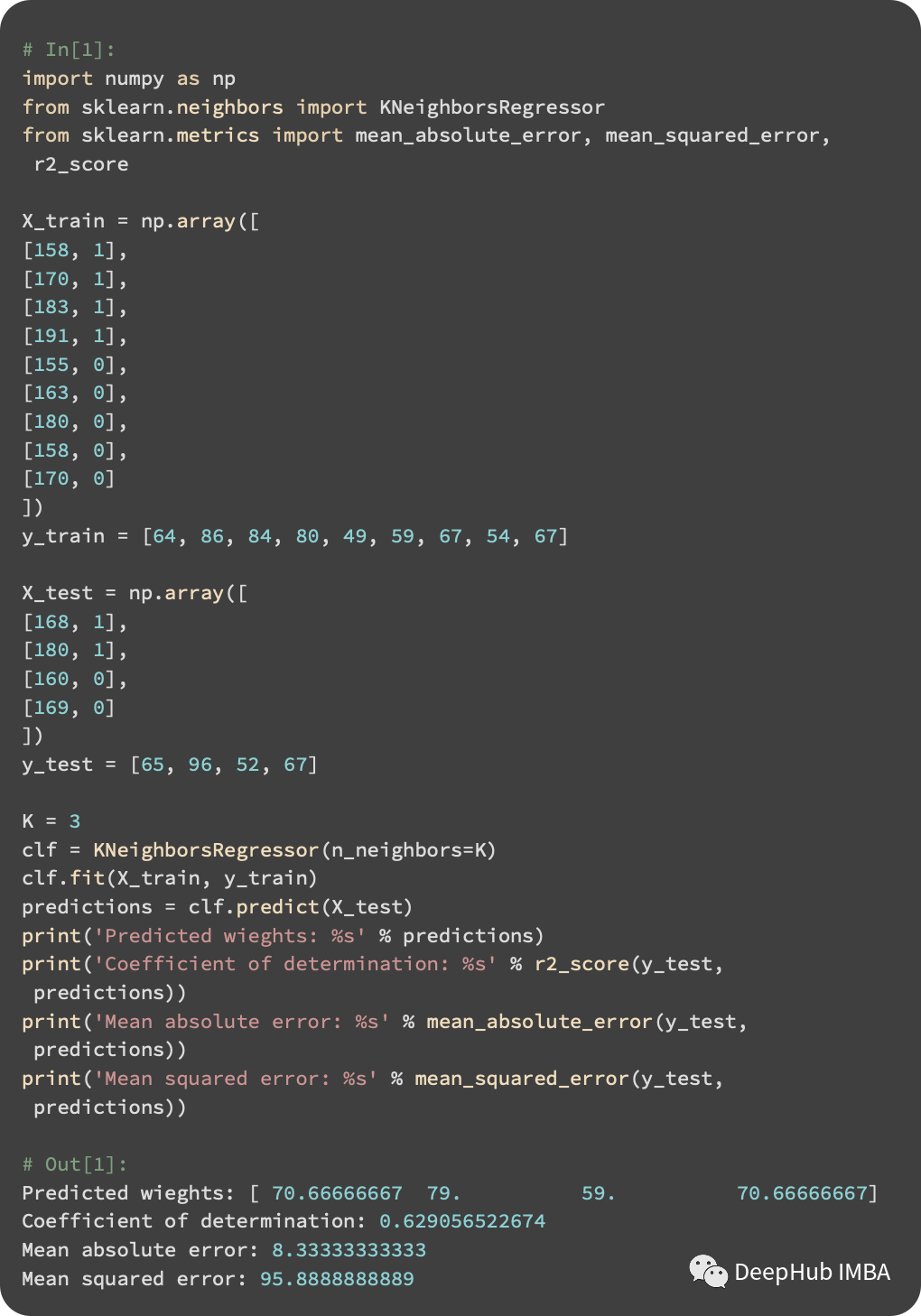
MAE的计算方法是将预测误差的绝对值取平均值。MAE的计算方法如下:
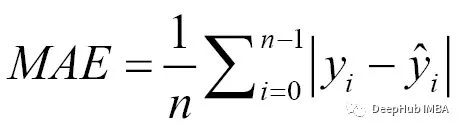
与平均绝对误差相比,均方偏差(MSE)更为常用。均方误差可以通过对预测误差的平方取平均值来计算,公式如下:
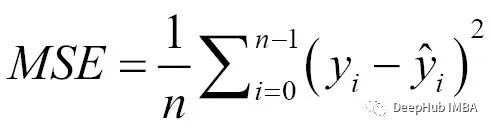
MSE比MAE对异常值的影响更大;一般情况下普通线性回归使MSE的平方根最小化
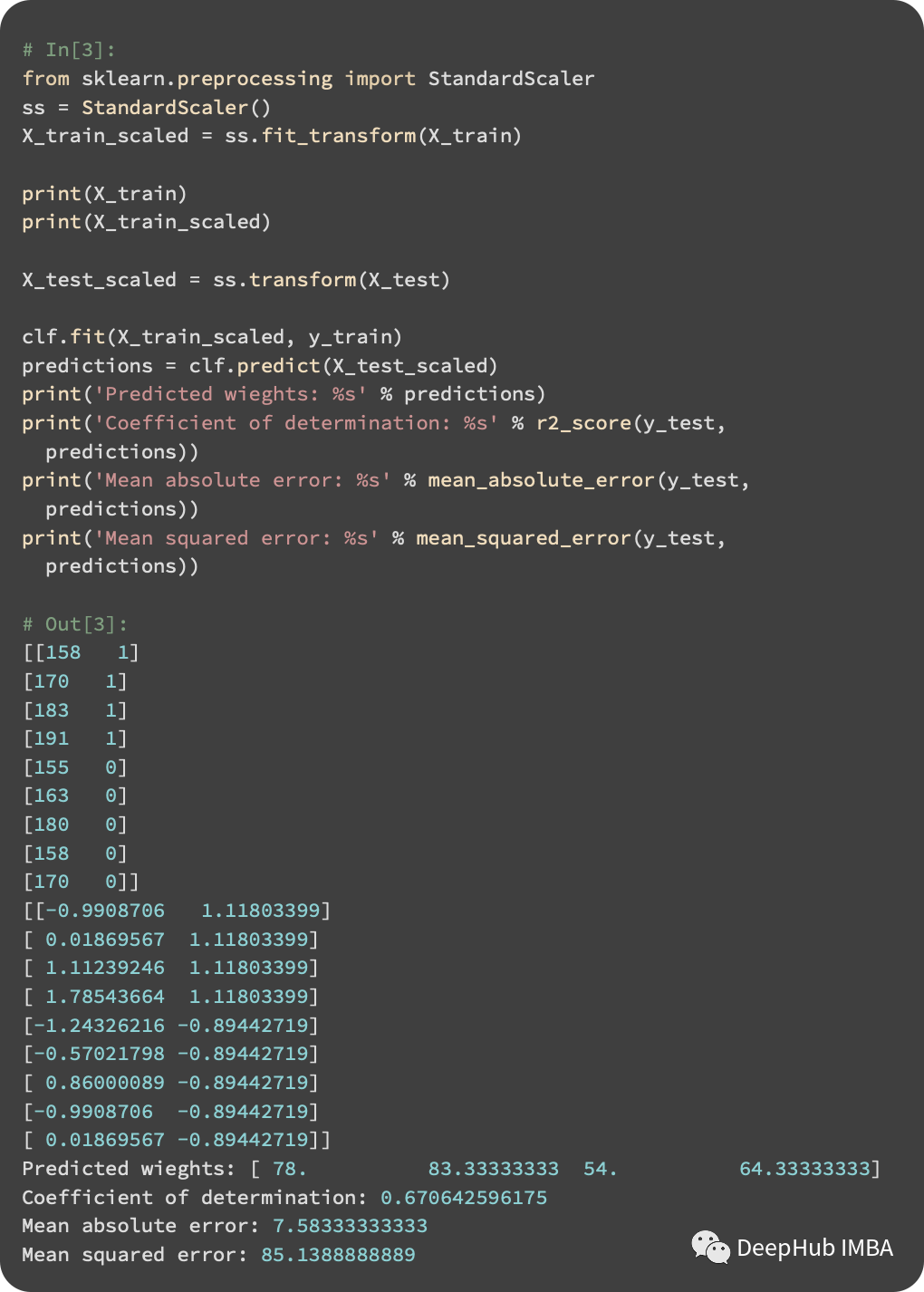
通过数据的标准化,我们的模型表现更好。当一个人的性别被包含在实例之间的距离时,模型可以做出更好的预测。
总结
KNN是我们在本文中介绍的一个简单但功能强大的分类和回归模型。KNN模型是一个懒惰的非参数学习模型;它的参数不是根据训练数据估计出来的。为了预测响应变量,它存储所有训练实例并使用最接近实例进行测试。在Sklearn中我们可以直接调用内置的方法来使用。
作者:Onepagecode